HashMap、ConcurrentHashMap对比
1.hashmap的put的原理,hashmap的扩容及计算槽的算法,线程安全的hashtable、ConcurrentHashMap的区别是什么
1.1 hashMap的put原理
什么时候变成红黑树?
当链表的长度为8以及table长度大于64时,变成红黑树(若小于64,则扩容),长度为8也是基于泊松离散分布,一个key中变成链表长度为8的概率很低,另外就是从查询效率方面,红黑树的平均查找长度(为确定记录在查找表中的位置,需和给定值进行比较的关键字个数的期望值)为:log(n) 若长度为8,则log2(8) = 3 ,链表的平均查找长度为8/2 = 4 红黑树效率更高
当红黑树的长度为6时,从红黑树变回链表,不直接用8,是防止数据结构来回变动。
为什么不直接使用红黑树,而是要先使用链表实在不行再转红黑树呢?
因为树节点的大小是链表节点大小的两倍,所以只有在容器中包含足够的节点保证使用才用它
add节点时,jdk7是头插法,而jdk8是尾插法
1.2 hash原理
jdk8:

jdk7:
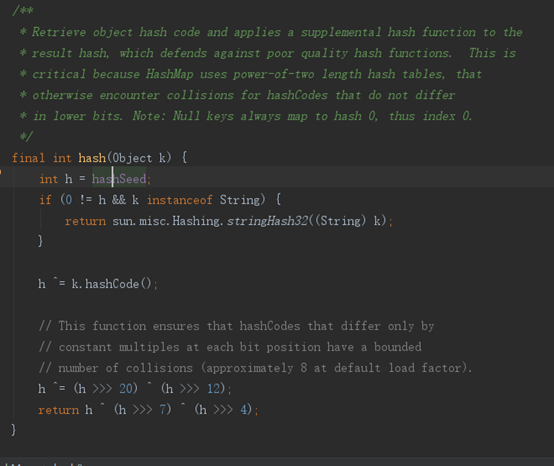
不管jdk7和8是怎么hash的,但是他们在使用的时候都使这样:
h & (length-1); (这里也可以说明hashMap容量为什么一定是2的n次方,为了方便& 16是经验值)
因为同length-1按位与,同 h% length一样,能够计算出来数组的下标,而且按位与效率更高,不需要十进制转换;而且还可以解决hash值为负数的为题,如果是对负数取模,还是比较麻烦(例如:-17 % 10 的计算结果如下:r = (-17) - (-17 / 10) x 10 = (-17) - (-1 x 10) = -7),如果是二进制,length-1肯定是正数,也就是得到的结果一定是正数
在jdk7中把hash值进行了4次右移,是为了对key的hashCode(32位有符号的int值)进行扰动计算,防止不同hashCode的高位不同但低位相同导致的hash冲突。简单点说,就是为了把高位的特征和低位的特征组合起来,降低哈希冲突的概率,也就是说,尽量做到任何一位的变化都能对最终得到的结果产生影响。
Java 8中这一步做了优化,只做一次16位右位移(也就取到了高16位)异或混合,而不是四次,但原理是不变的。
补充hashTable一些内容:
HashMap默认的初始化大小为16,之后每次扩充为原来的2倍。
HashTable默认的初始大小为11,之后每次扩充为原来的2n+1。
当哈希表的大小为素数时,简单的取模哈希的结果会更加均匀,所以单从这一点上看,HashTable的哈希表大小选择,似乎更高明些。因为hash结果越分散效果越好。
在取模计算时,如果模数是2的幂,那么我们可以直接使用位运算来得到结果,效率要大大高于做除法。所以从hash计算的效率上,又是HashMap更胜一筹。
但是,HashMap为了提高效率使用位运算代替哈希,这又引入了哈希分布不均匀的问题,所以HashMap为解决这问题,又对hash算法做了一些改进,进行了扰动计算。
1.3 负载因子为什么是0.75?
负载因子 = 填入表中的元素个数 / 散列表的长度
如果是1时,就说明,这个时候hashmap都满了,然后再扩容,这样肯定会有大量的hash冲突,
如果是0.5时,这个时候还有一半的空间,会造成空间浪费
设置为0.75是“泊松分布(描述单位时间内随机事件发生的次数的概率分布)”,在时间和空间上的折中。
1.4 为什么用红黑树?
红黑树本质上是一棵二叉查找树(左子节点的值小于根节点的值,右子节点的值大于根节点的值),但他在二叉查找树的基础上增加了着色和相关性质,使红黑树相对平衡,从而保证了红黑树的查找、插入、删除的时间复杂度都是O(logn)
红黑树的5个性质:
根节点是黑色
每个叶子节点是黑色
每个红色节点的所有叶子节点都是黑色
红黑树的左旋:左旋中的“左”,意味着“被旋转的节点将变成一个左节点”
红黑树的右旋:被旋转的节点将变成一个右节点
1.5 hashmap、hashtable、ConcurrentHashmap的区别
- hashtable的key不允许有null
- concurrenthashmap的key也不能为null
- 在JDK1.7版本中,ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,主要实现原理是实现了锁分离的思路解决了多线程的安全问题。put和 get 两次Hash到达指定的HashEntry,第一次hash到达Segment,第二次到达Segment里面的Entry,然后在遍历entry链表,Segment实现了ReentrantLock,也就带有锁的功能。当执行put操作时,会进行第一次key的hash来定位Segment的位置,如果该Segment还没有初始化,即通过CAS操作进行赋值,然后进行第二次hash操作,找到相应的HashEntry的位置,这里会利用继承过来的锁的特性,在将数据插入指定的HashEntry位置时(链表的尾端),会通过继承ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒.
- JDK1.8版本中synchronized+CAS+HashEntry+红黑树,
1.7跟1.8的相比,1.8的数据结构更加简单,使用红黑树优化查询效率。在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了
1.6 ConcurrentHashmap size的计算方式
jdk7:有两种方案:当第一种方案失败的时候回走第二种方案
第一种方案:使用不加锁的模式去尝试多次计算的segement的modcount(记录数据变化操作的次数),最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的.再返回segement中count值相加的结果。
第二种方案:给每个Segment加上锁,然后计算。
jdk8:
baseCount + 数组中的每个count
增加数量的时候,会先cas增加baseCount,如果baseCount增加失败,则会写到数组中,目的是为了减少锁冲突。
HashMap、ConcurrentHashMap对比的更多相关文章
- HashTable & HashMap & ConcurrentHashMap 原理与区别
一.三者的区别 HashTable HashMap ConcurrentHashMap 底层数据结构 数组+链表 数组+链表 数组+链表 key可为空 否 是 否 value可为空 否 是 否 ...
- 深入理解HashMap+ConcurrentHashMap的扩容策略
前言 理解HashMap和ConcurrentHashMap的重点在于: (1)理解HashMap的数据结构的设计和实现思路 (2)在(1)的基础上,理解ConcurrentHashMap的并发安全的 ...
- Jdk8 Hashmap ConcurrentHashMap
JDK1.8 Hashmap JDK1.8 ConcurrentHashMap 不采用segment而采用 synchronized (f) f = table[i]; 减小锁的力度 设计了MOVE ...
- java多线程:并发包中ConcurrentHashMap和jdk的HashMap的对比
一:HashMap--->底层存储的是Entry<K,V>[]数组--->Entry<K,V>的结构是一个单向的链表static class Entry<K, ...
- java多线程之hashmap concurrenthashmap的状态同步
最近在高并发的系统中发现,concurrenthashmap除了大家熟知的避免循环期间发生ConcurrentModificationException异常外,还有重要的一点是Retrievals r ...
- HashMap? ConcurrentHashMap? 相信看完这篇没人能难住你!
前言 Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据. 本篇主要想讨论 ConcurrentHashMap 这样一个并发容器,在正式开始之前我觉得有必要谈谈 ...
- Java7/8 HashMap ConcurrentHashMap
网上关于 HashMap 和 ConcurrentHashMap 的文章确实不少,不过缺斤少两的文章比较多,所以才想自己也写一篇,把细节说清楚说透,尤其像 Java8 中的 ConcurrentHas ...
- HashMap? ConcurrentHashMap?
前言 Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据. 本篇主要想讨论 ConcurrentHashMap 这样一个并发容器,在正式开始之前我觉得有必要谈谈 ...
- java面试考点-HashTable/HashMap/ConcurrentHashMap
HashTable 内部数据结构是数组+链表,键值对不允许为null,线程安全,但是锁是整表锁,性能较差/效率低 HashMap 结构同HashTable,键值对允许为null,线程不安全, 默认初始 ...
随机推荐
- 蓝图before request
方法1 @bp.before_request def test(): print("test") 方法2 def bp_before_request(): print(test) ...
- R语言中文分词包jiebaR
R语言中文分词包jiebaR R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大. R语言作为统计学一门语言,一直在小众领域闪耀着光芒.直到大数据 ...
- 大一C语言学习笔记(10)---编程篇--制作简易计算器,支持加,减,乘,除,取余运算,要求 0 bug
博主自开学初就一直在努力为自己的未来寻找学习方向,学习编程嘛,尽量还是要抱大腿的,所以我就加入了我们学校的智能设备研究所,别的不说,那的学长们看起来是真的很靠谱,学长们的学习氛围也超级浓厚,所以我就打 ...
- Python爬虫中的URLError\HTTPError异常类,异常的抛出
# _*_ coding : utf-8 _*_# @Time : 2021/11/2 14:20# @Author : 秋泊酱 import urllib.request import urllib ...
- [bzoj2668]交换棋子
基本思路是,要让所有黑点都相对应(所以首先判断黑点的个数).如果没有交换限制,可以按以下方法建图:源点向所有初始黑点连(1,0)的边,最终黑点向汇点连(1,0)的边,相邻的两点连边(inf,1),最小 ...
- 数值分析:幂迭代和PageRank算法(Numpy实现)
1. 幂迭代算法(简称幂法) (1) 占优特征值和占优特征向量 已知方阵\(\bm{A} \in \R^{n \times n}\), \(\bm{A}\)的占优特征值是比\(\bm{A}\)的其他特 ...
- 【玩具】使用Python自动化发送微信消息进行订水
事情是这样的,我知道淘宝上有卖一种USB接口的大按钮,估计是给工厂或者医院之类的场景设计的,样子长这样: 然后我就一直挺想搞一个的,不为别的,就是玩,但是想来想去也没想到这玩意儿对我而言能有啥用途,就 ...
- Codeforces 1208F - Bits And Pieces(高维前缀和)
题面传送门 题意:求 \(\max\limits_{i<j<k}a_i|(a_j\&a_k)\). \(1\leq n \leq 10^6,1\leq a_i\leq 2\time ...
- CF#581 (div2)题解
CF#581 题解 A BowWow and the Timetable 如果不是4幂次方直接看位数除以二向上取整,否则再减一 #include<iostream> #include< ...
- MYSQL权限全解
• All/All Privileges权限代表全局或者全数据库对象级别的所有权限 • Alter权限代表允许修改表结构的权限,但必须要求有create和insert权限配合.如果是rename表名, ...