[DB] Spark Core (1)
生态
- Spark Core:最重要,其中最重要的是RDD(弹性分布式数据集)
- Spark SQL
- Spark Streaming
- Spark MLLib:机器学习算法
- Spark Graphx:图计算
特点
- 针对大规模数据处理的快速通用引擎
- 基于内存计算
- 速度快,易用,兼容性强
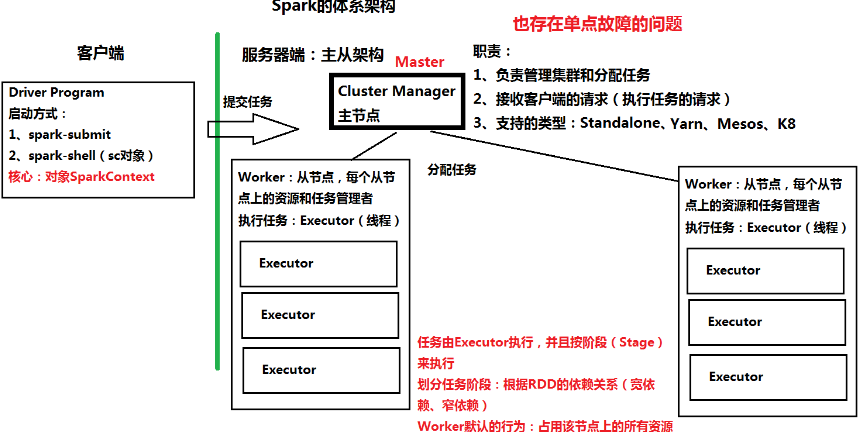
体系架构
- 主节点:Cluster Manager(Standalone时叫Master)
- 从节点:Worker(占用节点上所有资源,耗内存,没用内存管理机制,易OOM)

安装部署
- 安装jdk,配置主机名,配置免密码登录
- 伪分布(Standalone):一台机器上模拟分布式环境(Master+Worker)
- 核心配置文件:conf/spark-env.sh
- cp spark-env.sh.template spark-env.sh
- export JAVA_HOME=/root/training/jdk1.8.0_144
- export SPARK_MASTER_HOST=bigdata111
- export SPARK_MASTER_PORT=7077
- 启动:sbin/start-all.sh
- Web Console:http://192.168.174.111:8080/
- 核心配置文件:conf/spark-env.sh
- 全分布:先在主节点上安装,再把装好的目录复制到从节点上
- scp -r spark-2.1.0-bin-hadoop2.7/ root@bigdata114:/root/training
- 在主节点上启动集群
HA
- 基于文件目录
- 本质还是只有一个主节点
- 创建恢复目录保存状态信息
- 主要用于开发和测试
- mkdir /root/training/spark-2.1.0-bin-hadoop2.7/recovery
- spark-env.sh
- export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/root/training/spark-2.1.0-bin-hadoop2.7/recovery"

- 基于zookeeper
- 用于生产环境
- 相当于数据库
- 数据同步,选举功能,分布式锁(秒杀)
- 步骤
- 设置时间同步
- date -s 2020-06-03
- 启动zk
- 配置spark-env.sh,注释掉最后两行,添加:
- export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=bigdata112:2181,bigdata113:2181,bigdata114:2181 -Dspark.deploy.zookeeper.dir=/spark"
- bigdata112上启动spark集群后,在bigdata114上启动Master


工具
- spark-submit:用于提交Spark任务(jar包)
- bin/spark-submit --master spark://bigdata111:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.1.0.jar 100
- spark-shell:相当于REPL,命令行工具
- 本地模式
- bin/spark-shell
- 不需连接到Spark集群上,在本地(Eclipse)直接运行,用于开发和测试
- 集群模式
- bin/spark-shell --master spark://bigdata111:7077
- WordCount
- sc.textFile("/root/temp/data.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
- 本地模式

- sc.textFile("hdfs://bigdata111:9000/input/data.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)saveAsTextFile("hdfs://bigdata111:9000/output/1025")

- val rdd1 = sc.textFile("/root/temp/input/data.txt")
- val rdd2 = rdd1.flatMap(_.split(" "))
- val rdd3 = rdd2.map((_,1)) 【完整:val rdd3 = rdd2.map((word:String)=>(word,1) )】
- val rdd4 = rdd3.reduceByKey(_+_)【完整:val rdd4 = rdd3.reduceByKey((a:Int,b:Int)=> a+b)】
- rdd4.collect
IDE开发WordCount
- Scala版本
- 本地模式


1 package day0605
2
3 import org.apache.spark.SparkConf
4 import org.apache.spark.SparkContext
5
6 object MyWordCount {
7 def main(args:Array[String]):Unit = {
8 //创建一个任务的配置信息
9 //设置Master=local,表示运行在本地模式上
10 //集群模式不需设置Master
11 val conf = new SparkConf().setAppName("MyWordCount").setMaster("local")
12
13 //创建一个SparkContext对象
14 val sc = new SparkContext(conf)
15
16 //执行WordCount
17 val result = sc.textFile("hdfs://192.168.174.111:9000/input/data.txt")
18 .flatMap(_.split(" ")).map((_,1))
19 .reduceByKey(_+_).collect
20
21 //打印结果
22 result.foreach(println)
23
24 //停止SparkContext
25 sc.stop()
26 }
27 }

- 集群模式
- bin/spark-submit --master spark://bigdata111:7077 --class day0605.MyWordCount /root/temp/demo1.jar hdfs://bigdata111:9000/input/data.txt hdfs://bigdata111:9000/output/0605/demo1
- 集群模式
1 package day0605
2
3 import org.apache.spark.SparkConf
4 import org.apache.spark.SparkContext
5
6 //通过spark-submit提交
7
8 object MyWordCount {
9 def main(args:Array[String]):Unit = {
10 //创建一个任务的配置信息
11 //设置Master=local,表示运行在本地模式上
12 //集群模式不需设置Master
13 val conf = new SparkConf().setAppName("MyWordCount")
14
15 //创建一个SparkContext对象
16 val sc = new SparkContext(conf)
17
18 //执行WordCount
19 val result = sc.textFile(args(0))
20 .flatMap(_.split(" "))
21 .map((_,1))
22 .reduceByKey(_+_)
23
24 //输出到hdfs
25 result.saveAsTextFile(args(1))
26
27 //停止SparkContext
28 sc.stop()
29 }
30 }

- Java版本
1 package demo;
2
3 import java.util.Arrays;
4 import java.util.Iterator;
5 import java.util.List;
6
7 import org.apache.spark.SparkConf;
8 import org.apache.spark.api.java.JavaPairRDD;
9 import org.apache.spark.api.java.JavaRDD;
10 import org.apache.spark.api.java.JavaSparkContext;
11 import org.apache.spark.api.java.function.FlatMapFunction;
12 import org.apache.spark.api.java.function.Function2;
13 import org.apache.spark.api.java.function.PairFunction;
14
15 import scala.Tuple2;
16
17 /*
18 * 使用spark submit提交
19 * bin/spark-submit --master spark://bigdata111:7077 --class demo.JavaWordCount /root/temp/demo2.jar hdfs://bigdata111:9000/input/data.txt
20 */
21
22 public class JavaWordCount {
23
24 public static void main(String[] args) {
25 //运行在本地模式,可以设置断点
26 SparkConf conf = new SparkConf().setAppName("JavaWordCount").setMaster("local");
27
28 //运行在集群模式
29 //SparkConf conf = new SparkConf().setAppName("JavaWordCount");
30
31 //创建一个SparkContext对象: JavaSparkContext对象
32 JavaSparkContext sc = new JavaSparkContext(conf);
33
34 //读入HDFS的数据
35 JavaRDD<String> rdd1 = sc.textFile(args[0]);
36
37 /*
38 * 分词
39 * FlatMapFunction:接口,用于处理分词的操作
40 * 泛型:String 读入的每一句话
41 * U: 返回值 ---> String 单词
42 */
43 JavaRDD<String> rdd2 = rdd1.flatMap(new FlatMapFunction<String, String>() {
44
45 @Override
46 public Iterator<String> call(String input) throws Exception {
47 //数据: I love Beijing
48 //分词
49 return Arrays.asList(input.split(" ")).iterator();
50 }
51 });
52
53 /*
54 * 每个单词记一次数 (k2 v2)
55 * Beijing ---> (Beijing,1)
56 * 参数:
57 * String:单词
58 * k2 v2不解释
59 */
60 JavaPairRDD<String, Integer> rdd3 = rdd2.mapToPair(new PairFunction<String, String, Integer>() {
61
62 @Override
63 public Tuple2<String, Integer> call(String word) throws Exception {
64 return new Tuple2<String, Integer>(word, 1);
65 }
66
67 });
68
69 //执行Reduce的操作
70 JavaPairRDD<String, Integer> rdd4 = rdd3.reduceByKey(new Function2<Integer, Integer, Integer>() {
71
72 @Override
73 public Integer call(Integer a, Integer b) throws Exception {
74 //累加
75 return a+b;
76 }
77 });
78
79 //执行计算(Action),把结果打印在屏幕上
80 List<Tuple2<String,Integer>> result = rdd4.collect();
81
82 for(Tuple2<String,Integer> tuple:result){
83 System.out.println(tuple._1+"\t"+tuple._2);
84 }
85
86 //停止JavaSparkContext对象
87 sc.stop();
88 }
89 }
参考
spark.apache.org
spark任务提交两种方式
https://www.cnblogs.com/LHWorldBlog/p/8414342.html
[DB] Spark Core (1)的更多相关文章
- [DB] Spark Core (3)
高级算子 mapPartitionWithIndex:对RDD中每个分区(有下标)进行操作,通过自己定义的一个函数来处理 def mapPartitionsWithIndex[U](f: (Int, ...
- [DB] Spark Core (2)
RDD WordCount处理流程 sc.textFile("/root/temp/data.txt").flatMap(_.split(" ")).map(( ...
- Spark Streaming揭秘 Day35 Spark core思考
Spark Streaming揭秘 Day35 Spark core思考 Spark上的子框架,都是后来加上去的.都是在Spark core上完成的,所有框架一切的实现最终还是由Spark core来 ...
- 【Spark Core】任务运行机制和Task源代码浅析1
引言 上一小节<TaskScheduler源代码与任务提交原理浅析2>介绍了Driver側将Stage进行划分.依据Executor闲置情况分发任务,终于通过DriverActor向exe ...
- TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9a7c0a1 转换为 spark.core.IViewport。
1.错误描述 TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9aa90a1 转换为 spark.core.IViewport. ...
- Spark Core
Spark Core DAG概念 有向无环图 Spark会根据用户提交的计算逻辑中的RDD的转换(变换方法)和动作(action方法)来生成RDD之间的依赖关系,同时 ...
- spark core (二)
一.Spark-Shell交互式工具 1.Spark-Shell交互式工具 Spark-Shell提供了一种学习API的简单方式, 以及一个能够交互式分析数据的强大工具. 在Scala语言环境下或Py ...
- Spark Core 资源调度与任务调度(standalone client 流程描述)
Spark Core 资源调度与任务调度(standalone client 流程描述) Spark集群启动: 集群启动后,Worker会向Master汇报资源情况(实际上将Worker的资 ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
随机推荐
- vue 快速入门 系列 —— 虚拟 DOM
其他章节请看: vue 快速入门 系列 虚拟 DOM 什么是虚拟 dom dom 是文档对象模型,以节点树的形式来表现文档. 虚拟 dom 不是真正意义上的 dom.而是一个 javascript 对 ...
- 仅仅使用Google就完成了人生第一次破解
2021年2月6日21:17:09 begin 起因 在异乡的打工人,不善言谈,幸有一老同学,周末常邀吃饭,感恩之心铭记于心.她结婚时,为表心意欲做视频,视频需要制作字幕,搜索之,偶遇一字幕软件,但是 ...
- 安装mongoDB出现的问题:无法启动
在我的电脑- 管理 - 服务-中会出现一个MongoDB Server的服务,你需要去手动删除这个服务删除指令: 在cmd管理员模式下使用: sc delete MongoDB Server 然后再配 ...
- vite 动态 import 引入打包报错解决方案
关注公众号: 微信搜索 前端工具人 ; 收货更多的干货 原文链接: 自己掘金文章 https://juejin.cn/post/6951557699079569422/ 关注公众号: 微信搜索 前端工 ...
- Go+gRPC-Gateway(V2) 微服务实战,小程序登录鉴权服务(五):鉴权 gRPC-Interceptor 拦截器实战
拦截器(gRPC-Interceptor)类似于 Gin 中间件(Middleware),让你在真正调用 RPC 服务前,进行身份认证.参数校验.限流等通用操作. 系列 云原生 API 网关,gRPC ...
- JavaScript中的new,bind,call,apply的简易实现
Function原型链中的 apply,call 和 bind 方法是 JavaScript 中相当重要的概念,与 this 关键字密切相关,相当一部分人对它们的理解还是比较浅显,所谓js基础扎实,绕 ...
- Day13_68_中止线程
中止线程方法一 * 在线程类中定义一个bollean类型的变量,默认值设置为ture,如果想要中断线程,只需要将该boolean类型的变量设置为false就可以了 * 代码 package com.s ...
- 在nginx配置将请求转发到某个真实后端服务ip
一.打开nginx机器的nginx配置文件 命令: locate nginx.conf 会列出所有nginx.conf文件的地址, 一般咱们要用的nginx配置文件是/usr/local/nginx/ ...
- Salesforce 集成篇零基础学习(一)Connected App
本篇参考: https://zhuanlan.zhihu.com/p/89020647 https://trailhead.salesforce.com/content/learn/modules/c ...
- Django Ajax序列化与反序列化
序列化与反序列是最常用的功能,有时我们需要将一个表单组打包成Json格式等然后再提交给服务端,这样可以提高效率节约带框,如下是Django配合Ajax实现的序列化与反序列化,文件上传等操作. Ajax ...