[DB] Spark Core (2)
RDD
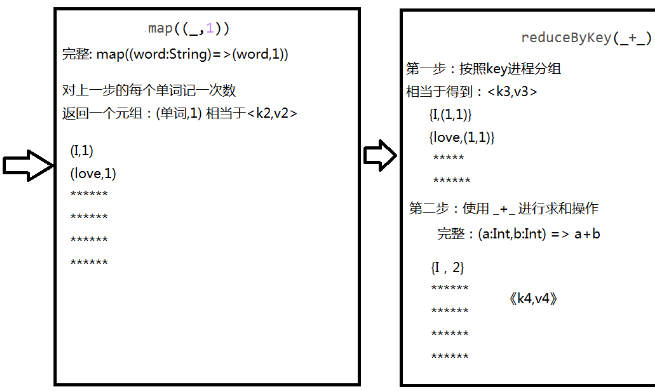
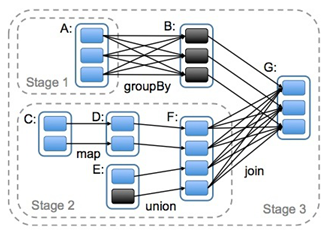
WordCount处理流程
- sc.textFile("/root/temp/data.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

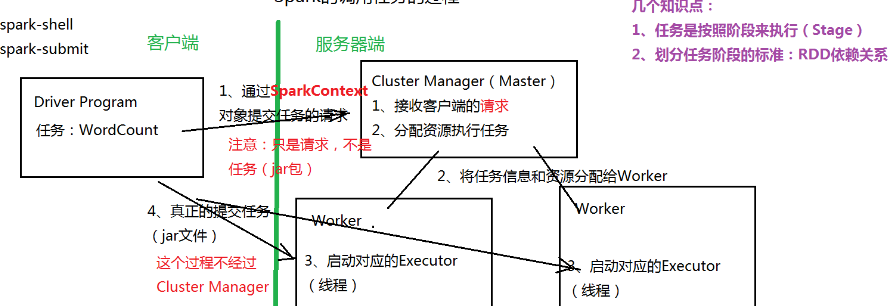
调用任务过程
- 客户端将任务通过SparkContext对象提交给Manager
- Manager将任务分配给Worker
- 客户端将任务提交给Worker
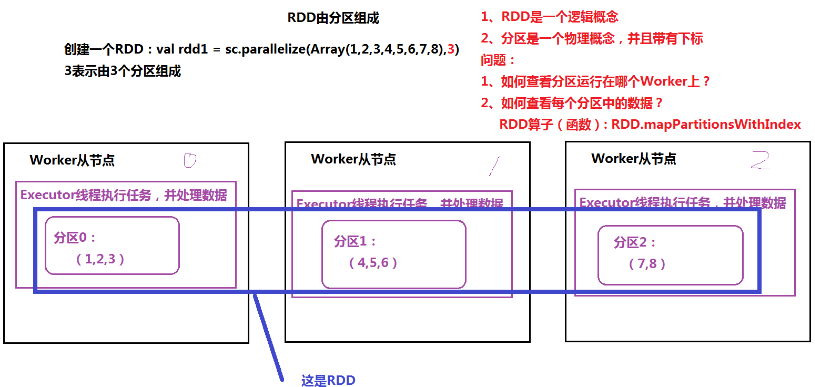
特性
- 由分区组成,每个分区运行在不同的worker上
- 通过算子(函数)处理每个分区中的数据
- RDD之间存在依赖关系(宽依赖、窄依赖),根据依赖关系,划分任务的Stage(阶段)
创建
- 通过集合创建:SparkContext.parallelize
- 通过读取外部数据源:HDFS,本地目录
算子(函数)
- Transformation:由一个RDD生成一个新的RDD。延时加载(计算)
- map(func):对原来的RDD进行某种操作,返回一个新的RDD
- filter(func):过滤
- flatMap(func):压平,类似Map
- mapPartitions(func):对RDD中的每个分区进行操作
- sample(withReplacement, fraction, seed)
- union(otherDataset):集合操作
- distinct([numTasks]):去重
- groupByKey([numTasks]):聚合操作(分组)
- sortByKey([ascending],[numTasks]):排序(针对<key,value>)
- sortBy()
- Action:对RDD计算出一个结果
- reduce(func)
- collect():
- foreach(func):类似map,但没有返回值
缓存
- 默认将RDD的数据缓存在内存中
- 提高性能
- 表示RDD可以被缓存,函数:persist 或 cache
容错
- 检查点(Checkpoint)
- 复习:HDFS中,由SecondaryNameNode进行日志的合并
- 一种容错机制,Lineage(血统)表示任务执行的声明周期(整个任务的执行过程)
- 血统越长,出错概率越大,出错时不需要从头计算,从最近检查点的位置往后计算即可
- 命令(本地模式和集群模式操作一样):
- sc.setCheckpointDir("/root/temp/spark"):指定检查点文件保存目录
- rdd1.checkpoint:标识RDD可以生成检查点
依赖
- 单步WordCount程序:
- val rdd1 = sc.textFile("/root/temp/input/data.txt")
- val rdd2 = rdd1.flatMap(_.split(" "))
- val rdd3 = rdd2.map((_,1)) 完整: val rdd3 = rdd2.map((word:String)=>(word,1) )
- val rdd4 = rdd3.reduceByKey(_+_)
- rdd4.collect
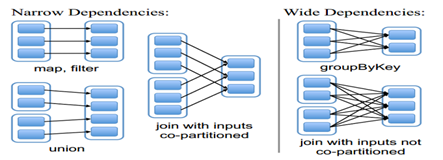
- 根据依赖关系划分任务执行的Stage(阶段)
- 宽依赖(类似“超生”):多个RDD的分区依赖了同一个父RDD分区(左父右子),如groupBy
- 窄依赖(类似“独生子女”):每个父RDD分区,最多被一个RDD的分区使用,如map
- 宽依赖是划分stage的依据
参考
官方API
http://spark.apache.org/docs/2.1.0/api/scala/index.html#org.apache.spark.package
[DB] Spark Core (2)的更多相关文章
- [DB] Spark Core (1)
生态 Spark Core:最重要,其中最重要的是RDD(弹性分布式数据集) Spark SQL Spark Streaming Spark MLLib:机器学习算法 Spark Graphx:图计算 ...
- [DB] Spark Core (3)
高级算子 mapPartitionWithIndex:对RDD中每个分区(有下标)进行操作,通过自己定义的一个函数来处理 def mapPartitionsWithIndex[U](f: (Int, ...
- Spark Streaming揭秘 Day35 Spark core思考
Spark Streaming揭秘 Day35 Spark core思考 Spark上的子框架,都是后来加上去的.都是在Spark core上完成的,所有框架一切的实现最终还是由Spark core来 ...
- 【Spark Core】任务运行机制和Task源代码浅析1
引言 上一小节<TaskScheduler源代码与任务提交原理浅析2>介绍了Driver側将Stage进行划分.依据Executor闲置情况分发任务,终于通过DriverActor向exe ...
- TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9a7c0a1 转换为 spark.core.IViewport。
1.错误描述 TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9aa90a1 转换为 spark.core.IViewport. ...
- Spark Core
Spark Core DAG概念 有向无环图 Spark会根据用户提交的计算逻辑中的RDD的转换(变换方法)和动作(action方法)来生成RDD之间的依赖关系,同时 ...
- spark core (二)
一.Spark-Shell交互式工具 1.Spark-Shell交互式工具 Spark-Shell提供了一种学习API的简单方式, 以及一个能够交互式分析数据的强大工具. 在Scala语言环境下或Py ...
- Spark Core 资源调度与任务调度(standalone client 流程描述)
Spark Core 资源调度与任务调度(standalone client 流程描述) Spark集群启动: 集群启动后,Worker会向Master汇报资源情况(实际上将Worker的资 ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
随机推荐
- 系统编程-信号-总体概述和signal基本使用
信号章节 -- 信号章节总体概要 信号基本概念 信号是异步事件,发送信号的线程可以继续向下执行而不阻塞. 信号无优先级. 1到31号信号是非实时信号,发送的信号可能会丢失,不支持信号排队. 31号信号 ...
- 生产环境中mysql数据库由主从关系切换为主主关系
目录 一.清除原从数据库数据及主从关系 1.1.关闭主从数据库原有的主从关系 1.2.清除从数据库原有数据 二.将主库上的数据备份到从库 2.1.备份主库数据到从库 2.2.在从库使用tsc.sql文 ...
- 设计原则:单一职责(SRP)原则
1 什么是单一职责(SRP)原则 单一职责原则的英文是 Single Responsibility Principle,缩写为 SRP.翻译过来就是:一个类或者模块只负责完成一个职责(或者功能). 所 ...
- JavaScript课程——Day01
1.网页由三部分组成: 1.1.HTML:超文本标记语言,专门编写网页内容的语言.(结构) 1.2.CSS:层叠样式表.(样式) 1.3.javaScript:网页交互的解释性脚本语言,专门编写客户端 ...
- Day01_03_Java名词
java名词 SDK 软件开发工具包 JDK Java的软件开发工具包,其中包括Java虚拟机(JVM),Java运行环境(即jre),Java工具(编译器,运行工具等)和Java基础类库等. JRE ...
- 深入学习Android系统上mount命令的使用
博客链接:http://blog.csdn.net/qq1084283172/article/details/52493227 在Android系统的预装apk病毒和elf病毒的清除时,经常需要先获取 ...
- POJ2155二维线段树
题意: 给一个n*n的01矩阵,然后有两种操作(m次)C x1 y1 x2 y2是把这个小矩形内所有数字异或一遍,Q x y 是询问当前这个点的值是多少?n<=1000 m<=5 ...
- Windows Pe 第三章 PE头文件(上)
第三章 PE头文件 本章是全书重点,所以要好好理解,概念比较多,但是非常重要. PE头文件记录了PE文件中所有的数据的组织方式,它类似于一本书的目录,通过目录我们可以快速定位到某个具体的章节:通过P ...
- 痞子衡嵌入式:可通过USB Device Path来唯一指定i.MXRT设备进行ROM/Flashloader通信
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是通过USB Device Path来唯一指定i.MXRT设备进行ROM/Flashloader通信. i.MXRT系列高性能微控制器从2 ...
- c语言编程学习之二维数组
二维数组 c语言按照行主序存储二维数组.也就是说,二维数组元素在内存中的位置是连续的,每行末尾元素(若不是最后一行)的下一个元素就是下一行的首元素. 如下图所示 接下来我们来分析一下如何将二维数组所有 ...