大数据学习day38----数据仓库01-----区域字典的生成
更多内容见文档
1. 区域字典的生成
mysql中有如下表格数据
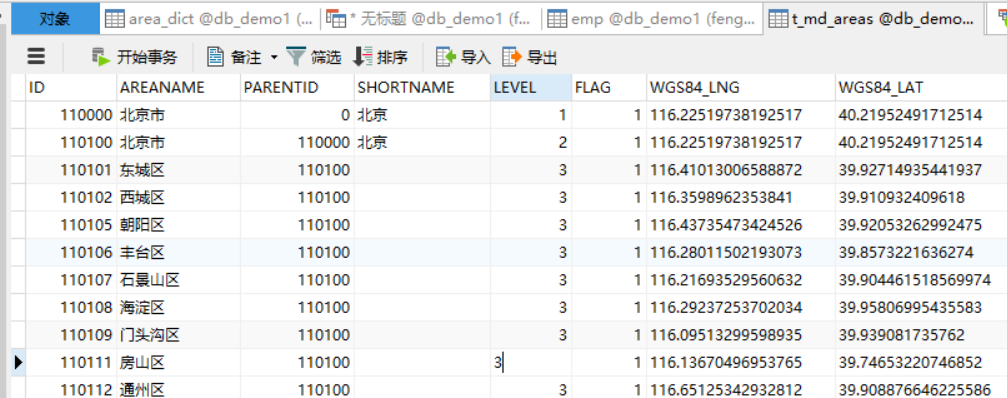
现要将这类数据转换成(GEOHASH码, 省,市,区)如下所示
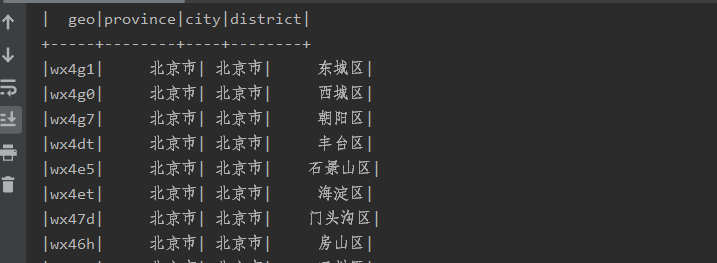
(1)第一步:在mysql中使用sql语句对表格数据进行整理(此处使用到了自关联,具体见文档大数据学习day03)
create table area_dict
as
SELECT
a.BD09_LNG as lng,
a.BD09_LAT as lat,
a.AREANAME as district,
b.AREANAME as city,
c.AREANAME as province from t_md_areas a
join t_md_areas b on a.`LEVEL`=3 and a.PARENTID=b.ID
join t_md_areas c on b.PARENTID = c.ID
得到结果如下
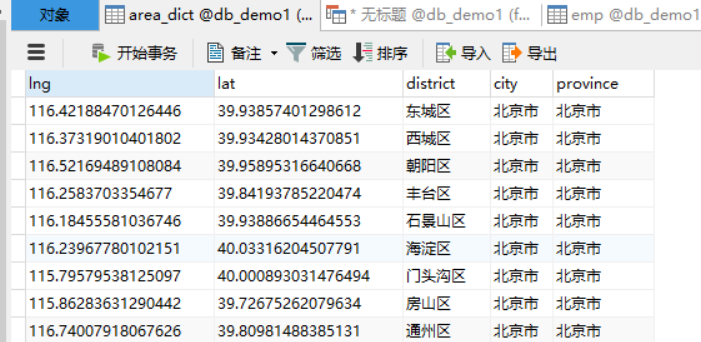
(2)第二步:使用spark sql读取这些数据,并将数据使用GeoHash编码,具体代码如下(这里涉及到parquet数据源,spark喜欢的数据格式)
AreaDictGenerator
package com._51doit import java.util.Properties import ch.hsr.geohash.GeoHash
import org.apache.spark.sql.{DataFrame, SparkSession} object AreaDictGenerator {
def main(args: Array[String]): Unit = {
// 创建SparkSession实例
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
// 创建连接数据库需要的参数
val probs: Properties = new Properties()
probs.setProperty("driver", "com.mysql.jdbc.Driver")
probs.setProperty("user","root")
probs.setProperty("password", "feng")
// 以读取mysql数据库的形式创建DataFrame
val df: DataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/db_demo1?characterEncoding=UTF-8", "area_dict", probs)
// 运算逻辑
import spark.implicits._
val res: DataFrame = df.rdd.map(row => {
val lng = row.getAs[Double]("lng")
val lat = row.getAs[Double]("lat")
val district = row.getAs[String]("district")
val city = row.getAs[String]("city")
val province = row.getAs[String]("province")
val geoCode: String = GeoHash.withCharacterPrecision(lat, lng, 5).toBase32
(geoCode, province, city, district)
}).toDF("geo", "province", "city", "district")
res.write.parquet("E:/javafile/spark/out11")
}
}
这一步即可得到上述格式的数据。
(3)验证
ParquetReader
package com._51doit
import org.apache.spark.sql.{DataFrame, SparkSession}
object ParquetReader {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
val df: DataFrame = spark.read.parquet("E:/javafile/spark/out11")
df.show()
}
}
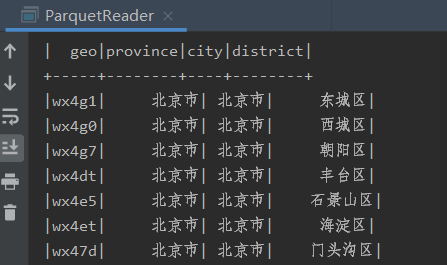
结果
大数据学习day38----数据仓库01-----区域字典的生成的更多相关文章
- 大数据学习之Linux基础01
大数据学习之Linux基础 01:Linux简介 linux是一种自由和开放源代码的类UNIX操作系统.该操作系统的内核由林纳斯·托瓦兹 在1991年10月5日首次发布.,在加上用户空间的应用程序之后 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
- 大数据学习路线,来qun里分享干货,
一.Linux lucene: 全文检索引擎的架构 solr: 基于lucene的全文搜索服务器,实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面. 推荐一个大数据学习群 ...
- 大数据学习之 LINUX
##大数据学习 古斌6.6 01. linux系统的搭建: 选用 Contos 6.5 x64位系统 (CentOS-6.5-x86_64-minimal.iso) 我选择的为迷你版 模板机: bla ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
随机推荐
- 数组中重复的数字 牛客网 剑指Offer
数组中重复的数字 牛客网 剑指Offer 题目描述 在一个长度为n的数组里的所有数字都在0到n-1的范围内. 数组中某些数字是重复的,但不知道有几个数字是重复的.也不知道每个数字重复几次.请找出数组中 ...
- Apache Solr应用服务器存在远程代码执行漏洞👻
Apache Solr应用服务器存在远程代码执行漏洞 1.描述 Apache Solr是一个开源的搜索服务,使用Java语言开发,主要基于HTTP和Apache Lucene实现的. Solr是一个高 ...
- SpringCloud升级之路2020.0.x版-30. FeignClient 实现重试
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 需要重试的场景 微服务系统中,会遇到在线发布,一般的发布更新策略是:启动一个新的,启动成功 ...
- 自定义实例默认值 axios.create(config)
自定义实例默认值 axios.create(config) 根据指定配置创建一个新的axios,也就就每个新 axios 都有自己的配置 新 axios只是没有取消请求和批量发请求的方法,其它所有语法 ...
- Java发展的重大事故
1990年,在Sun计算机公司中,由Patrick Naughton.Mi keSheridan 及 James Gosling领导的小组Green Team,开发出的新的程序语言,命名为0ak, 后 ...
- java框架面试高频问题(SpringMVC)
1.SpringMVC是什么? 请说出你对它的理解? SpringMVC是Spring将Web层基于MVC封装后的框架. 在没有SpringMVC之前,Web层的Servlet负责的事情很多,很杂. ...
- Linux——基础命令用法(上)
一.Linux基础命令 1.Linux命令行的格式 命令行的格式为:用户名+主机名+当前工作目录 输入内容的命令格式为:命令 [-短选项/--长选项] [参数] [root@localhost ~]# ...
- Abp Vnext Blazor替换UI组件 集成BootstrapBlazor(详细过程)
Abp Vnext自带的blazor项目使用的是 Blazorise,但是试用后发现不支持多标签.于是想替换为BootstrapBlazor. 过程比较复杂,本人已经把模块写好了只需要替换掉即可. 点 ...
- Java设计模式之(十二)——观察者模式
1.什么是观察者模式? Define a one-to-many dependency between objects so that when one object changes state, a ...
- k8s-数据持久化存储卷,nfs,pv/pvc
目录 数据持久化-储存卷 官方文档 存储卷类型 1.emptyDir 2.hostpath 3.pv/pvc(推荐使用) nfs官方文档 安装测试nfs pv/pvc管理nfs 官方文档 pv/pvc ...