spark实验(一)--spark安装(1)
一、实验目的
(1)掌握 Linux 虚拟机的安装方法。Spark 和 Hadoop 等大数据软件在 Linux 操作系统 上运行可以发挥最佳性能,因此,本教程中,Spark 都是在 Linux 系统中进行相关操作,同 时,下一章的 Scala 语言也会在 Linux 系统中安装和操作。鉴于目前很多读者正在使用 Windows 操作系统,因此,为了顺利完成本教程的后续实验,这里有必要通过本实验,让读 者掌握在 Windows 操作系统上搭建 Linux 虚拟机的方法。当然,安装 Linux 虚拟机只是安 装 Linux 系统的其中一种方式,实际上,读者也可以不用虚拟机,而是采用双系统的方式安 装 Linux 系统。本教程推荐使用虚拟机方式。 (2)熟悉 Linux 系统的基本使用方法。本教程全部在 Linux 环境下进行实验,因此, 需要读者提前熟悉 Linux 系统的基本用法,尤其是一些常用命令的使用方法。
二、实验过程
环境:centos6.4,jdk1.7.0,spark1.5.2
根据这篇博文https://www.cnblogs.com/Genesis2018/p/9079787.html安装spark1.5.2
首先输入
wget http://archive.apache.org/dist/spark/spark-1.5.2/spark-1.5.2-bin-hadoop2.6.tgz下载spark1.5.2

等待下载完成后,将下载完的文件进行解压
输入
tar -zxvf spark-1.5.2-bin-hadoop2.6.tgz将下载完的文件进行解压,之后输入以下命令移动到对应的/usr/local/目录中
mv spark-1.5.2-bin-hadoop2.6 /usr/local/
接着输入
gedit /etc/profile.d/spark.sh在打开的文件中添加以下的信息
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR==$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/usr/local/spark-1.5.2-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin保存退出后
输入
source /etc/profile.d/spark.sh使文件生效
接着输入
cp /usr/local/spark-1.5.2-bin-hadoop2.6/conf/spark-env.sh.template /usr/local/spark-1.5.2-bin-hadoop2.6/conf/spark-env.shgedit /usr/local/spark-1.5.2-bin-hadoop2.6/conf/spark-env.sh在打开的文件中输入(IP和jdk需要根据自己本身的版本进行设置)
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.221.x86_64/jre
export SCALA_HOME=/usr/local/scala-2.10.6
export HADOOP_HOME=/usr/local/hadoop-2.7.2
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_HOST=192.168.57.128
export SPARK_LOCAL_IP=192.168.57.128
接着输入
cp /usr/local/spark-1.5.2-bin-hadoop2.6/conf/slaves.template /usr/local/spark-1.5.2-bin-hadoop2.6/conf/slavesgedit /usr/local/spark-1.5.2-bin-hadoop2.6/conf/slaves将localhost中的内容改为对应虚拟机ip的地址
192.168.57.128
保存退出
验证spark安装:
sbin/start-master.sh在服务器外边输入对应
http://192.168.57.128:8080/
发现正常启动
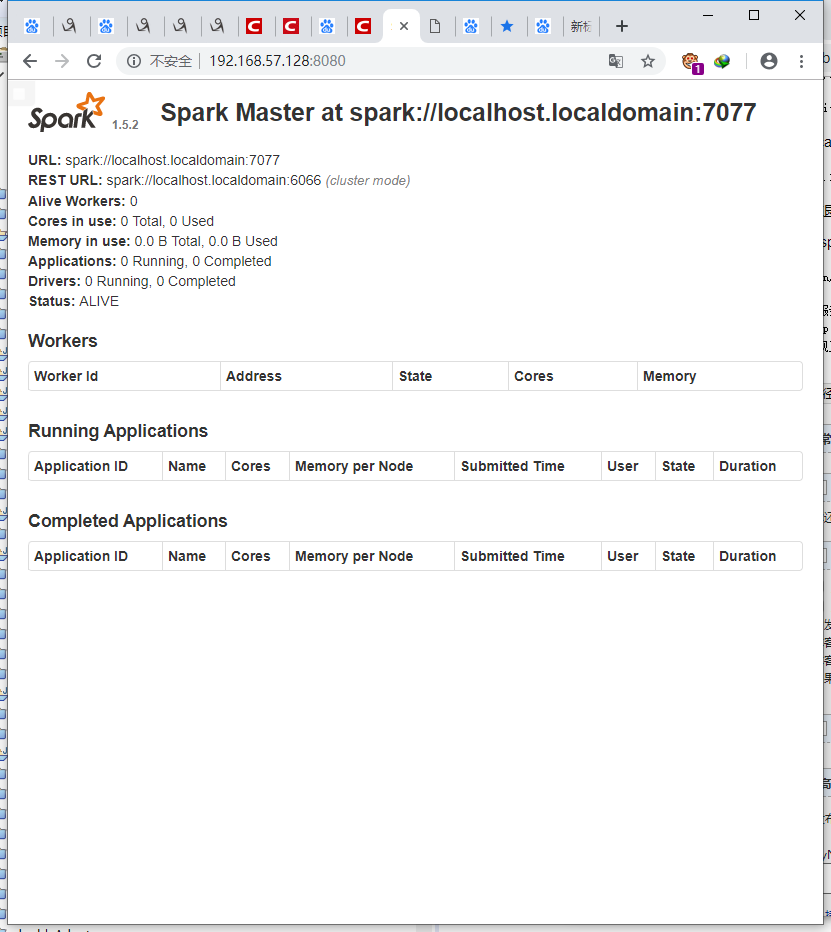
spark安装完毕
spark实验(一)--spark安装(1)的更多相关文章
- spark实验(五)--Spark SQL 编程初级实践(1)
一.实验目的 (1)通过实验掌握 Spark SQL 的基本编程方法: (2)熟悉 RDD 到 DataFrame 的转化方法: (3)熟悉利用 Spark SQL 管理来自不同数据源的数据. 二.实 ...
- spark实验(三)--Spark和Hadoop的安装(1)
一.实验目的 (1)掌握在 Linux 虚拟机中安装 Hadoop 和 Spark 的方法: (2)熟悉 HDFS 的基本使用方法: (3)掌握使用 Spark 访问本地文件和 HDFS 文件的方法. ...
- spark实验(二)--scala安装(1)
一.实验目的 (1)掌握在 Linux 虚拟机中安装 Hadoop 和 Spark 的方法: (2)熟悉 HDFS 的基本使用方法: (3)掌握使用 Spark 访问本地文件和 HDFS 文件的方法. ...
- spark实验(二)--eclipse安装scala环境(2)
此次在eclipse中的安装参考这篇博客https://blog.csdn.net/lzxlfly/article/details/80728772 Help->Eclipse Marketpl ...
- 在阿里云上搭建 Spark 实验平台
在阿里云上搭建 Spark 实验平台 Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程 [传统文化热爱者] 阿里云服务器搭建spark特别坑的地方 阿里云实现Hadoop+Sp ...
- Apache Spark简单介绍、安装及使用
Apache Spark简介 Apache Spark是一个高速的通用型计算引擎,用来实现分布式的大规模数据的处理任务. 分布式的处理方式可以使以前单台计算机面对大规模数据时处理不了的情况成为可能. ...
- spark的standlone模式安装和application 提交
spark的standlone模式安装 安装一个standlone模式的spark集群,这里是最基本的安装,并测试一下如何进行任务提交. require:提前安装好jdk 1.7.0_80 :scal ...
- Spark运行环境的安装
scala-2.9.3:一种编程语言,下载地址:http://www.scala-lang.org/download/ spark-1.4.0:必须是编译好的Spark,如果下载的是Source ...
- 实验5 Spark SQL编程初级实践
今天做实验[Spark SQL 编程初级实践],虽然网上有答案,但都是用scala语言写的,于是我用java语言重写实现一下. 1 .Spark SQL 基本操作将下列 JSON 格式数据复制到 Li ...
随机推荐
- CLR处理损坏状态的异常
你有没有写过不太正确但足够接近的代码?当一切顺利的时候,你是否不得不编写运行良好的代码,但是你不太确定当出了问题时会发生什么?有一个简单的.不正确的语句可能位于您编写或必须维护的代码中:catch ( ...
- Django流程-以登录功能为例
Django流程-以登录功能为例 一.注意点 1.新创建的app一定要先去settings.py注册 简写:'app01' 完整:'app01.apps.App01Config' 2.启动Django ...
- 使用pip安装速度慢问题的解决
参考博客:https://blog.csdn.net/u011580175/article/details/82292424 解决方案所以,在使用pip时,可以指定使用国内的下载源这样下载速度会快很多 ...
- Centos610-Nginx-TCP代理配置
1.安装Nginx 详见<nginx>安装 2.下载nginx_tcp_proxy_module模块 下载 wget https://github.com/yaoweibin/nginx ...
- tomcat服务器启动执行的两个方法
第一 SetApplicationContext(需要继承ApplicationContextAware)重写 第二 ContextInitialize(需要继承servleContet)重写,(co ...
- S3C2440_时钟和电源管理_阅读开发手册记录
1.如何进入sleep mode 1)要把一些重要的数据存放在状态寄存器里,状态寄存器里的数据在掉电后不会丢失. 2)要设置好唤醒源 3)配置相关寄存器,使其进入sleep mode 2.如何从sle ...
- linux 自带php切换xampp
查看系统中有哪些用户: cut -d : -f 1 /etc/passwd 查看当前php: which php 删除系统自带php软链 rm -rf /usr/bin/php 切换到PHP新路径 l ...
- python调用c++开发的动态库
此处列举一下python调用Windows端动态库. # *- coding=utf-8 -* import ctypes from ctypes import * import os objdll ...
- mysql设置定时任务(对于中控心跳包的实现有意义)
转载:https://www.cnblogs.com/laowu-blog/p/5073665.html 目前用途:因为 脚本正常开关会给中控发送消息 但是万一脚本被强制关闭 没有触发脚本关闭事件就无 ...
- MySQL忘记密码(终极解决方法,亲测有效,windows版本)
1.进入mysql的bin目录 2.net stop mysql 3.mysqld --skip-grant-tables 输入 mysqld --skip-grant-tables 回车. (--s ...