python词云图与中文分词
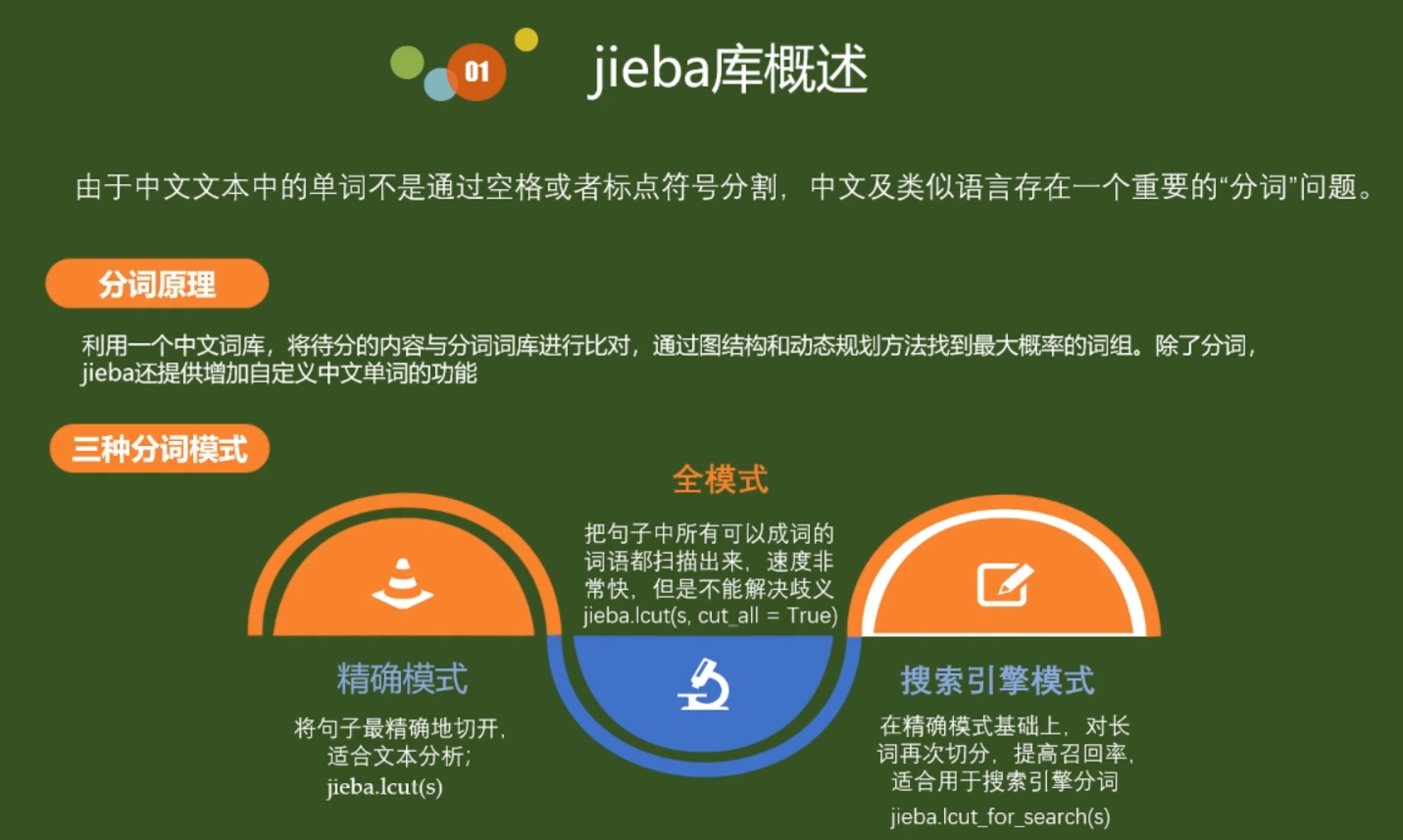


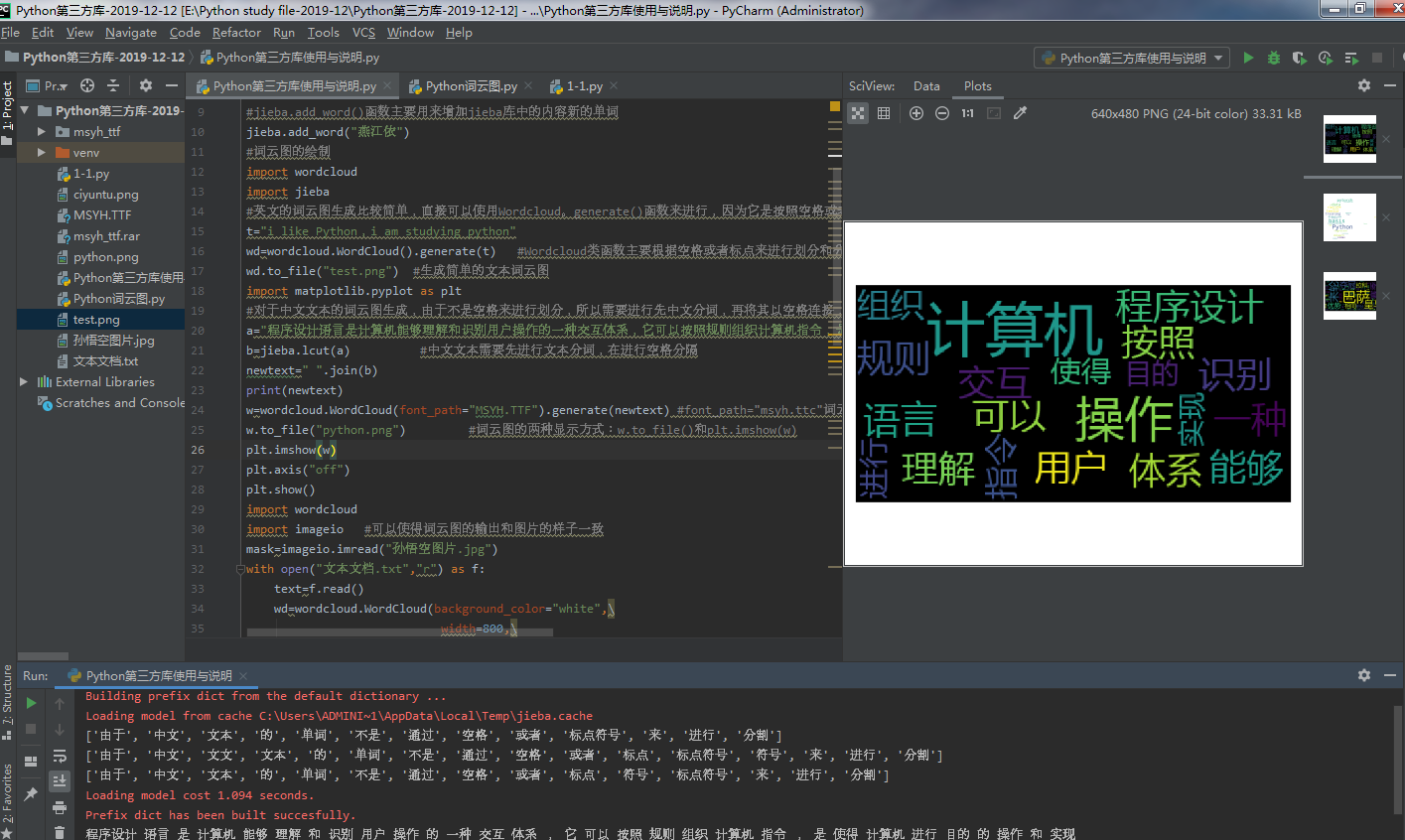
2019-12-12中文文本分词和词云图具体功能介绍与学习代码:
import jieba
a="由于中文文本的单词不是通过空格或者标点符号来进行分割"
#jieba.lcut()s是最常用的中文分词函数,用于精准模式,即将字符串分割为等量的中文词组,返回结果是列表类型
print(jieba.lcut(a))
#jieba.lcut(s,cut_all=True):用于全模式,即将字符串所有分词可能均列出来,返回结果是列表类型,冗余性较大,速度很快,但是不能解决歧义的问题
print(jieba.lcut(a,cut_all=True))
#jieba.lcut_for_search函数主要是返回搜索引擎模式,该模式首先精准执行精确模式,然后再对其中的长词进行进一步的切片获得最终结果
print(jieba.lcut_for_search(a))
#jieba.add_word()函数主要用来增加jieba库中的内容新的单词
jieba.add_word("燕江依")
#词云图的绘制
import wordcloud
import jieba
#英文的词云图生成比较简单,直接可以使用Wordcloud。generate()函数来进行,因为它是按照空格或者标点符号来进行划分
t="i like Python,i am studying python"
wd=wordcloud.WordCloud().generate(t) #Wordcloud类函数主要根据空格或者标点来进行划分和分词,主直接生成英文的词云图
wd.to_file("test.png") #生成简单的文本词云图
import matplotlib.pyplot as plt
#对于中文文本的词云图生成,由于不是空格来进行划分,所以需要进行先中文分词,再将其以空格连接,之后对其进行Wordcloud的generate函数,这样便可以实现中文文本的词云图的生成
a="程序设计语言是计算机能够理解和识别用户操作的一种交互体系,它可以按照规则组织计算机指令,是使得计算机进行目的的操作和实现"
b=jieba.lcut(a) #中文文本需要先进行文本分词,在进行空格分隔
newtext=" ".join(b)
print(newtext)
w=wordcloud.WordCloud(font_path="MSYH.TTF").generate(newtext) #font_path="msyh.ttc"词云图的字体设置,需要进行下载
w.to_file("python.png") #词云图的两种显示方式:w.to_file()和plt.imshow(w)
plt.imshow(w)
plt.axis("off")
plt.show()
import wordcloud
import imageio #可以使得词云图的输出和图片的样子一致
mask=imageio.imread("孙悟空图片.jpg")
with open("文本文档.txt","r") as f:
text=f.read()
wd=wordcloud.WordCloud(background_color="white",\
width=800,\
height=600,\
max_words=200,\
max_font_size=80,mask=mask,\
).generate(text)
plt.axis("off") #关掉坐标轴的显示
plt.imshow(wd)
wd.to_file("ciyuntu.png")
plt.show() import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt s1 = """ 在克鲁伊夫时代,巴萨联赛中完成了四连冠,后三个冠军都是在末轮逆袭获得的。
在91/92赛季,巴萨末轮前落后皇马1分,结果皇马客场不敌特内里费使得巴萨逆转。
一年之后,巴萨用几乎相同的方式逆袭,皇马还是末轮输给了特内里费。
在93/94赛季中,巴萨末轮前落后拉科1分。
巴萨末轮5比2屠杀塞维利亚,拉科则0比0战平瓦伦西亚,巴萨最终在积分相同的情况下靠直接交锋时的战绩优势夺冠。
神奇的是,拉科球员久基奇在终场前踢丢点球,这才有了巴萨的逆袭。""" s2 = """ 巴萨上一次压哨夺冠,发生在09/10赛季中。末轮前巴萨领先皇马1分,只要赢球就将夺冠。
末轮中巴萨4比0大胜巴拉多利德,皇马则与对手踢平。
巴萨以99分的佳绩创下五大联赛积分纪录,皇马则以96分成为了悲情的史上最强亚军。""" s3 = """在48/49赛季中,巴萨末轮2比1拿下同城死敌西班牙人,以2分优势夺冠。
52/53赛季,巴萨末轮3比0战胜毕巴,以2分优势力压瓦伦西亚夺冠。
在59/60赛季,巴萨末轮5比0大胜萨拉戈萨。皇马巴萨积分相同,巴萨靠直接交锋时的战绩优势夺冠。""" mylist = [s1, s2, s3]
word_list = [" ".join(jieba.cut(sentence)) for sentence in mylist]
new_text = ' '.join(word_list)
wordcloud = WordCloud(font_path="MSYH.TTF",background_color="black").generate(new_text)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
python词云图与中文分词的更多相关文章
- 特朗普退出《巴黎协定》:python词云图舆情分析
1 前言 2017年6月1日,美国特朗普总统正式宣布美国退出<巴黎协定>.宣布退出<巴黎协定>后,特朗普似乎成了“全球公敌”. 特斯拉总裁马斯克宣布退出总统顾问团队 迪士尼董事 ...
- python利用jieba进行中文分词去停用词
中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词. 分词模块jieba,它是python比较好用的分词模块.待分词的字符串可以是 unicod ...
- [python] 使用Jieba工具中文分词及文本聚类概念
声明:由于担心CSDN博客丢失,在博客园简单对其进行备份,以后两个地方都会写文章的~感谢CSDN和博客园提供的平台. 前面讲述了很多关于Python爬取本体Ontology.消息盒Inf ...
- python词云图之WordCloud
1. 导入需要的包package import matplotlib.pyplot as plt from scipy.misc import imread from wordcloud import ...
- Java实现敏感词过滤 - IKAnalyzer中文分词工具
IKAnalyzer 是一个开源的,基于java语言开发的轻量级的中文分词工具包. 官网: https://code.google.com/archive/p/ik-analyzer/ 本用例借助 I ...
- Python词云的中文问题
image= Image.open('F:/__identity/course/建模/九寨沟地震/四川地图.jpg') fig = plt.figure(figsize=(20, 16)) graph ...
- [Python] 基于 jieba 的中文分词总结
目录 模块安装 开源代码 基本用法 启用Paddle 词性标注 调整词典 智能识别新词 搜索引擎模式分词 使用自定义词典 关键词提取 停用词过滤 模块安装 pip install jieba jieb ...
- 【python】利用jieba中文分词进行词频统计
以下代码对鲁迅的<祝福>进行了词频统计: import io import jieba txt = io.open("zhufu.txt", "r" ...
- 3.python词云图的生成
安装库 pip install jieba wordcloud matplotlib 准备 txt文本 字体(simhei.ttf) 词云背景图片 代码 import matplotlib.pyplo ...
随机推荐
- Java面向对象编程 -6.2
数组的引用传递 通过数组的基本定义可以发现,在数组使用的过程中依然需要使用new进行内存空间的开辟,同理,那么也一定存在有内存的关系匹配问题. 但是数组本身毕竟属于引用数据类型,那么既然是引用数据类型 ...
- html解析のBeautifulSoup
引子: 使用python爬虫对爬取网页进行解析的时候,如果使用正则表达式,有很多局限,比如标签中出现换行,或者标签的格式不规范,都有可能出现取不到数据,BeautifulSoup作为一个专门处理htm ...
- 解决 IDEA 下 struts.xml 中 extends="struts-default" 报红的问题
现象 在IDEA中配置struts.xml时 extends="struts-default" 报红,配置拦截器时属性无预选项提示,也爆红. struts.xml本身的配置并没有错 ...
- linu后台执行py文件和关闭的后台py文件
后台执行py nohup python xxx.py 关闭后台执行py 查看进程pid ps -aux|grep main.py 根据pid关闭关闭进程 kill -9 (pid)
- ubuntu 18 python3.6更换国内源和pip3源
1.更换国内源 查看Ubuntu18版本和codename(一定要注意codename对应) lsb_release -a No LSB modules are available. Distribu ...
- SpringBoot与Mybatis整合(包含generate自动生成代码工具,数据库表一对一,一对多,关联关系中间表的查询)
链接:https://blog.csdn.net/YonJarLuo/article/details/81187239 自动生成工具只是生成很单纯的表,复杂的一对多,多对多的情况则是在建表的时候就建立 ...
- 配置SVTI
路由器SVTI站点到站点VPN 在IOS 12.4之前建立安全的站点间隧道只能采用GRE over IPSec,从IOS 12.4之后设计了一种全新的隧道技术,即VIT(Virtual ...
- 用js实现复制内容到操作系统粘贴板(兼容IE、谷歌、火狐等浏览器)
一.如果只考虑IE浏览器,可以直接用原声js实现 if(window.clipboardData){ //清空操作系统粘贴板 window.clipboardData.clearData(); //将 ...
- pip源、搭建虚拟环境、git
一.pip源 1.1 介绍 1.采用国内源,加速下载模块的速度2.常用pip源:-- 豆瓣:https://pypi.douban.com/simple-- 阿里:https://mirrors.al ...
- 树莓派4B踩坑指南 - (6)安装常用软件及相关设置
安装软件 安装LibreOffice中文包 sudo apt-get install libreoffice-l10n-zh-cn sudo reboot 安装codeblocks并汉化: sudo ...