如何用Python来处理数据表的长宽转换(图文详解)
不多说,直接上干货!
很多地方都需用到这个知识点,比如Tableau里。 通常可以采取如python 和 r来作为数据处理的前期。
Tableau学习系列之Tableau如何通过数据透视表方式读取数据文件(图文详解)
数据长宽转换是很常用的需求,特别是当是从Excel中导入的汇总表时,常常需要转换成一维表(长数据)才能提供给图表函数或者模型使用。
python中,我这里只讲两个函数:
melt #数据宽转长
pivot_table #数据长转宽
Python中的Pandas包提供了与R语言中reshape2包内几乎同名的melt函数来对数据进行塑型(宽转长)操作,甚至连内部参数都保持了一致的风格。
import pandas as pd
import numpy as np mydata=pd.DataFrame({
"Name":["苹果","谷歌","脸书","亚马逊","腾讯"],
"Conpany":["Apple","Google","Facebook","Amozon","Tencent"],
"Sale2013":[,,,,],
"Sale2014":[,,,,],
"Sale2015":[,,,,],
"Sale2016":[,,,,]
}) mydata1=mydata.melt(
id_vars=["Name","Conpany"], #要保留的主字段
var_name="Year", #拉长的分类变量
value_name="Sale" #拉长的度量值名称
)

除此之外,我了解到还可以通过stack、wide_to_long函数来进行宽转长,但是个人觉得melt函数比较直观一些,也与R语言中的数据宽转长用法一致,推荐使用。
奇怪的是我好像没有在pandas中找到对应melt的数据长转宽函数(R语言中都是成对出现的)。还在Python中提供了非常便捷的数据透视表操作函数,刚开始就已经说过是,长数据转宽数据就是数据透视的过程(自然宽转长就可以被称为逆透视咯,PowerBI也是这么称呼的)。
pandas中的数据透视表函数提供如同Excel原生透视表一样的使用体验,即行标签、列标签、度量值等操作,根据使用规则,行列主要操作维度指标,值主要操作度量指标。
那么以上长数据mydata1就可以通过这种方式实现透视。
mydata1.pivot_table(
index=["Name","Conpany"], #行索引(可以使多个类别变量)
columns=["Year"], #列索引(可以使多个类别变量)
values=["Sale"] #值(一般是度量指标)
)
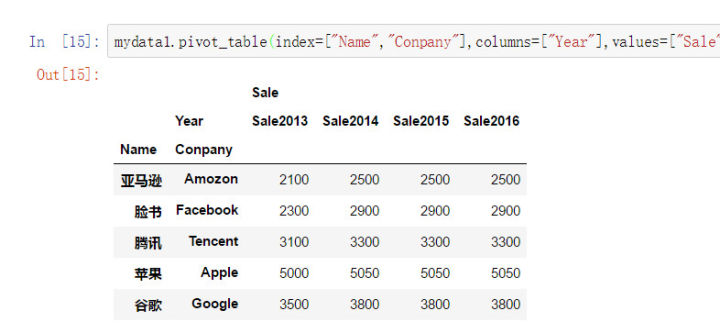
通常这种操作也可以借助堆栈函数来达到同样的目的。(但是使用stack\unstack需要额外设置多索引,灰常麻烦,所以不是很推荐,有兴趣可以查看pandas中的stack/unstack方法,这里不再赘述)。
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



如何用Python来处理数据表的长宽转换(图文详解)的更多相关文章
- 如何用R来处理数据表的长宽转换(图文详解)
不多说,直接上干货! 很多地方都需用到这个知识点,比如Tableau里. 通常可以采取如python 和 r来作为数据处理的前期. Tableau学习系列之Tableau如何通过数据透视表方式读取 ...
- Ubuntu14.04下沙盒数据导入到 Neo4j 数据库(图文详解)
不多说,直接上干货! 参考博客 http://blog.csdn.net/u012318074/article/details/72793914 (表示感谢) 前期博客 Neo4j沙盒实验申请过程 ...
- Ubuntu16.04下沙盒数据导入到 Neo4j 数据库(图文详解)
不多说,直接上干货! 参考博客 http://blog.csdn.net/u012318074/article/details/72793914 (表示感谢) 前期博客 Neo4j沙盒实验申请过 ...
- SPSS学习系列之SPSS Statistics导入读取数据(多种格式)(图文详解)
不多说,直接上干货! SPSS Statistics导入读取数据的步骤: 文件 -> 导入数据 成功! 欢迎大家,加入我的微信公众号:大数据躺过的坑 免费给分享 同时,大 ...
- Python的Django框架中forms表单类的使用方法详解
用户表单是Web端的一项基本功能,大而全的Django框架中自然带有现成的基础form对象,本文就Python的Django框架中forms表单类的使用方法详解. Form表单的功能 自动生成HTML ...
- SQL Server 表的管理_关于数据增删查改的操作的详解(案例代码)
SQL Server 表的管理_关于数据增删查改的操作的详解(案例代码)-DML 1.SQL INSERT INTO 语句(在表中插入) INSERT INTO 语句用于向表中插入新记录. SQL I ...
- 图解大数据 | 海量数据库查询-Hive与HBase详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/84 本文地址:http://www.showmeai.tech/article-det ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 如何在IDEA里给大数据项目导入该项目的相关源码(博主推荐)(类似eclipse里同一个workspace下单个子项目存在)(图文详解)
不多说,直接上干货! 如果在一个界面里,可以是单个项目 注意:本文是以gradle项目的方式来做的! 如何在IDEA里正确导入从Github上下载的Gradle项目(含相关源码)(博主推荐)(图文详解 ...
随机推荐
- 可执行 jar | 到底如何执行
dog │ pom.xml │ └───src └───main └───java └───cn └───zno Dog.java bark │ pom.xml │ └───src └───main ...
- 手把手教Electron+vue的使用
.现如今前端框架数不胜数,尤其是angular.vue吸引一大批前端开发者,在这个高新技术快速崛起的时代,自然少不了各种框架的结合使用.接下来是介绍electron+vue的结合使用. 2.Elect ...
- hdu 5084 前缀和预处理
http://acm.hdu.edu.cn/showproblem.php?pid=5084 给出矩阵M,求M*M矩阵的r行c列的数,每个查询跟前一个查询的结果有关. 观察该矩阵得知,令ans = M ...
- SRM483
250pt 题意:给定一个[0,1)间的实数,一个分母不超过maxDen的分数逼近.. 思路:直接枚举.然后判断. code: #line 7 "BestApproximationDiv1. ...
- Concurrency Programming Guide 并发设计指引(二)
以下翻译是本人通过谷歌工具进行翻译,并进行修正后的结果,希望能对大家有所帮助.如果您发现翻译的不正确不合适的地方,希望您能够发表评论指正,谢谢.转载请注明出处. Concurrency and App ...
- 在windows右键菜单中加入自己的程序 [转载]
原文链接: http://blog.csdn.net/marklr/article/details/4006356 在windows右键菜单中加入自己的程序 标签: windowsattribute ...
- 三维数组—— 与宝玉QQ群交流 之三
鞠老师 12:50:34 A[excel文件名][excel.sheet][sheet.行][sheet.列] 构成四维数组 计131-张振渊 12:51:54 a[1][0][0][3]? 鞠老师 ...
- INDEX--从数据存放的角度看索引
测试表结构: CREATE TABLE TB1 ( ID ,), C1 INT, C2 INT ) 1. 聚集索引(Clustered index) 聚集索引可以理解为一个包含表中除索引键外多有剩余列 ...
- WPF点滴(3) 行为-Behavior
为了定制个性化的用户界面,我们通常会借助于WPF强大的样式(style),修改控件属性,重写控件模板(template),样式帮助我们构建一致的个性化控件.通过样式可以调整界面的显示效果,这只是界面构 ...
- NHibernate问题求大神解决!!!
这是我定义的实体类 对应的数据库表 映射文件 数据访问层写的是插入语句 错误: 捕捉到 NHibernate.Exceptions.GenericADOException HResult=-21462 ...