[Spark Core] Spark Shell 实现 Word Count
0. 说明
在 Spark Shell 实现 Word Count
RDD (Resilient Distributed dataset), 弹性分布式数据集。
示意图
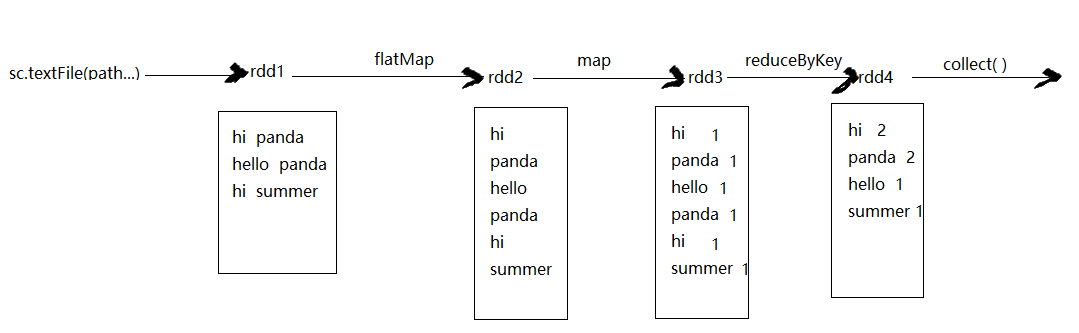
1. 实现
1.1 分步实现
# step 加载文档
val rdd1 = sc.textFile("file:///home/centos/wc1.txt") # step 压扁
val rdd2 = rdd1.flatMap(line=>{line.split(" ")}) # step 标1成对
val rdd3 = rdd2.map(word=>{(word , )}) # step 聚合
val rdd4 = rdd3.reduceByKey((a:Int,b:Int)=>{a + b}) # step
rdd4.collect()
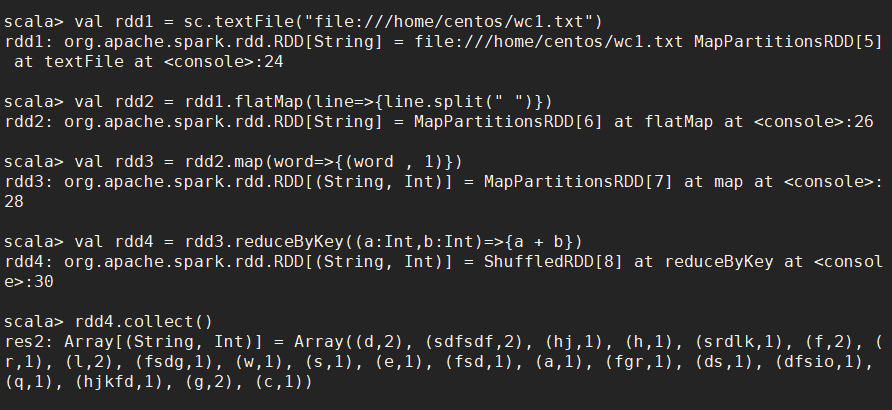
1.2 一步完成 (reduceByKey)
sc.textFile("file:///home/centos/wc1.txt").flatMap(_.split(" ")).map((_,)).reduceByKey(_+_).collect()

1.3 一步完成 (groupByKey)
sc.textFile("file:///home/centos/wc1.txt").flatMap(_.split(" ")).map((_,)).groupByKey().mapValues(_.size).collect()

[Spark Core] Spark Shell 实现 Word Count的更多相关文章
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- Spark:java api实现word count统计
方案一:使用reduceByKey 数据word.txt 张三 李四 王五 李四 王五 李四 王五 李四 王五 王五 李四 李四 李四 李四 李四 代码: import org.apache.spar ...
- [Spark Core] Spark 实现气温统计
0. 说明 聚合气温数据,聚合出 MAX . MIN . AVG 1. Spark Shell 实现 1.1 MAX 分步实现 # 加载文档 val rdd1 = sc.textFile(" ...
- [Spark Core] Spark Client Job 提交三级调度框架
0. 说明 官方文档 Job Scheduling Spark 调度核心组件: DagScheduler TaskScheduler BackendScheduler 1. DagSchedule ...
- [Spark Core] Spark 核心组件
0. 说明 [Spark 核心组件示意图] 1. RDD resilient distributed dataset , 弹性数据集 轻量级的数据集合,逻辑上的集合.等价于 list 没有携带数据. ...
- [Spark Core] Spark 使用第三方 Jar 包的方式
0. 说明 Spark 下运行job,使用第三方 Jar 包的 3 种方式. 1. 方式一 将第三方 Jar 包分发到所有的 spark/jars 目录下 2. 方式二 将第三方 Jar 打散,和我们 ...
- 【待补充】[Spark Core] Spark 实现标签生成
0. 说明 在 IDEA 中编写 Spark 代码实现将 JSON 数据转换成标签,分别用 Scala & Java 两种代码实现. 1. 准备 1.1 pom.xml <depend ...
- [Spark Core] Spark 在 IDEA 下编程
0. 说明 Spark 在 IDEA 下使用 Scala & Spark 在 IDEA 下使用 Java 编写 WordCount 程序 1. 准备 在项目中新建模块,为模块添加 Maven ...
- shell 实现word count
awk '{arr[$2]+=$1}END{for (i in arr) print i,arr[i]}' sort_all.txt | sort -k2nr -g
随机推荐
- mysql计算排名 转
from :http://www.cnblogs.com/aeiou/p/5719396.html http://www.cnblogs.com/zengguowang/p/5541431.html ...
- 当语音识别搭配AI之后,我的语音助手更懂我的心了
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由腾讯云AI中心发表于云+社区专栏 我今天演讲主要分四个部分,第一个是分享语音识别概述,然后是深度神经网络的基础:接下来就是深度学习在语 ...
- Tomcat学习总结(4)——基于Tomcat7、Java、WebSocket的服务器推送聊天室
前言 HTML5 WebSocket实现了服务器与浏览器的双向通讯,双向通讯使服务器消息推送开发更加简单,最常见的就是即时通讯和对信息实时性要求比较高的应用.以前的服务器消息推送大 ...
- maven jetty debug 无法关联第三方类库解决办法
http://ifedorenko.github.com/m2e-extras/
- redis-小用
1.redis之flushall.flushdb‘尴尬’操作恢复 redis是基于内存的一种高效数据库,在内存中高效但是不安全,重启和断电都会导致数据丢失.所以就需要用到数据的持久化,redis有两种 ...
- UVa 1572 Self-Assembly (拓扑排序)
题目链接: https://cn.vjudge.net/problem/UVA-1572 Automatic Chemical Manufacturing is experimenting with ...
- 如何让win2008服务器显示中文无乱码
使用Windows Server 2008 R2 IIS搭建FTP服务器时,客户端登录FTP后中文文件夹显示为乱码,应在“控制面板”-“区域和语言”中查看“当前系统区域设置”的情况. 应确保“非Uni ...
- linux下安装oracle及weblogic
安装weblogic 下载weblogic http://www.oracle.com/technetwork/middleware/weblogic/downloads/wls-for-dev-17 ...
- zookeeper 知识点汇总
目录 Zookeeper 是什么 Zookeeper 树状模型 Zookeeper 集群结构 如何使用 ZooKeeper 运行 Zookeeper 步骤1 修改 ZooKeeper 配置文件 步骤 ...
- 青蛙的约会(poj1061+欧几里德)
青蛙的约会 Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 94174 Accepted: 17412 Descripti ...