【慕课网实战】Spark Streaming实时流处理项目实战笔记六之铭文升级版
铭文一级:
整合Flume和Kafka的综合使用
avro-memory-kafka.conf
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = hadoop000
avro-memory-kafka.sources.avro-source.port = 44444
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = hadoop000:9092
avro-memory-kafka.sinks.kafka-sink.topic = hello_topic
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
avro-memory-kafka.sinks.kafka-sink.requiredAcks =1
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
flume-ng agent \
--name avro-memory-kafka \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/avro-memory-kafka.conf \
-Dflume.root.logger=INFO,console
flume-ng agent \
--name exec-memory-avro \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/exec-memory-avro.conf \
-Dflume.root.logger=INFO,console
kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic hello_topic
铭文二级:
Kafka Producer java API编程:
建KafkaProperties类=>
申明三个静态属性:
public static final String
1.BROKER_LIST="192.168.0.115:9092" //IP地址修改成自己的地址
2.ZK="192.168.0.115:2181" //IP地址修改成自己的地址
3.TOPIC="hello_topic"
建KafkaProducer类=>
创建构造方法实现123小点,参数为topic:(构造方法为私有还是公有?公有)
1.申明Producer类(导入类为kafka.javaapi.Producer),查看返回值与参数值
2.参数值new ProducerConfig(),里面参数为properties(在构造方法中new出来)
3.properties需要put三个属性:
A.metadata.broker.list //类静态方法获得
B.serializer.class //kafka.serializer.StringEncoder
C.request.required.acks //值说明如下:
0:不等待任何握手机制;
1:写到本地log并返回ack,常用,但可能有一丁点数据丢失
-1:严格握手,只要有副本存活就没有数据丢失
4.使类继承Thread类,因为使用线程测试
public void run(){
int messageNo = 1;
while(true){
String message = "message_" + messageNo;
producer.send(new KeyedMessage<Integer,String>(topic,message));
system.out.println("Send:" + message);
messageNo++;
}
try{
Thread.sleep(2000);
}catch(Exception e){
e.printStackTrace();
}
}
建KafkaClientApp测试类:
1.申明main方法
2.new KafkaProducer(KafkaProperties.TOPIC).start();
3.jps查询是否已启动zookeeper、kafka、consumer,必须先启动
4.运行main方法可观察到控制台与consumer终端有内容输出
Kafka Consumer java API编程:
创建KafkaConsumer类=>
申明参数为topic的构造方法
private ConsumerConnector createConnector(){
Properties properties = new Properties();
properties.put("zookeeper.connect", KafkaProperties.ZK);
properties.put("group.id",KafkaProperties.GROUP_ID);
return Consumer.createJavaConsumerConnector(new ConsumerConfig(properties));
}
public void run() {
ConsumerConnector consumer = createConnector();
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, 1);
// topicCountMap.put(topic2, 1);
// topicCountMap.put(topic3, 1);
// String: topic
// List<KafkaStream<byte[], byte[]>> 对应的数据流
Map<String, List<KafkaStream<byte[], byte[]>>> messageStream = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = messageStream.get(topic).get(0); //获取我们每次接收到的数据
ConsumerIterator<byte[], byte[]> iterator = stream.iterator();
while (iterator.hasNext()) {
String message = new String(iterator.next().message());
System.out.println("rec: " + message);
}
}
代码分析:
1.获取Consumer,根据分装过的topicCountMap生成信息流messageStream
topicCountMap.put(topic,1);//参数“1” 指生成一个信息流
2.此时messageStream里面还有topic,需要去除topic,返回stream
3.将stream进行迭代,返回iterator
4.通过while(iterator.hasNext())与iterator.next().message()生成message并返回
ps:KafkaProperties类勿忘需要加一个属性GROUP_ID并添加到properties,自起一个id即可
示例:
public static final String GROUP_ID = "test_group1";
properties.put("group.id",KafkaProperties.GROUP_ID);
Kafka实战=>
整合Flume和kafka完成实时数据采集
修改avro-memory-logger.conf//将sink改成kafka,详情可看CDH5里面的文档,官网新版有些小改动
type:org.apache.flume.sink.kafka.KafkaSink
brokerList:hadoop000:9092
非必须:
topic //自己尝试不设置是否可以,默认是调用含有topic参数的topic
batchSize:5
requiredAcks:1
分别开始,然后测试。
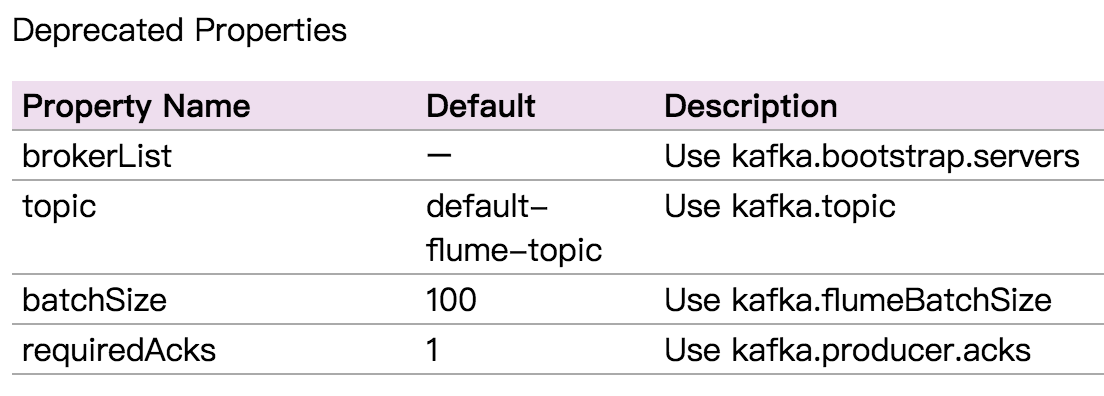
ps:上面属性名已经不推荐,最新官网为,可能跟版本有关,自行测试:
【慕课网实战】Spark Streaming实时流处理项目实战笔记六之铭文升级版的更多相关文章
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十之铭文升级版
铭文一级: 第八章:Spark Streaming进阶与案例实战 updateStateByKey算子需求:统计到目前为止累积出现的单词的个数(需要保持住以前的状态) java.lang.Illega ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记七之铭文升级版
铭文一级: 第五章:实战环境搭建 Spark源码编译命令:./dev/make-distribution.sh \--name 2.6.0-cdh5.7.0 \--tgz \-Pyarn -Phado ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十四之铭文升级版
铭文一级: 第11章 Spark Streaming整合Flume&Kafka打造通用流处理基础 streaming.conf agent1.sources=avro-sourceagent1 ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记二之铭文升级版
铭文一级: 第二章:初识实时流处理 需求:统计主站每个(指定)课程访问的客户端.地域信息分布 地域:ip转换 Spark SQL项目实战 客户端:useragent获取 Hadoop基础课程 ==&g ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十六之铭文升级版
铭文一级: linux crontab 网站:http://tool.lu/crontab 每一分钟执行一次的crontab表达式: */1 * * * * crontab -e */1 * * * ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十五之铭文升级版
铭文一级:[木有笔记] 铭文二级: 第12章 Spark Streaming项目实战 行为日志分析: 1.访问量的统计 2.网站黏性 3.推荐 Python实时产生数据 访问URL->IP信息- ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十二之铭文升级版
铭文一级: ======Pull方式整合 Flume Agent的编写: flume_pull_streaming.conf simple-agent.sources = netcat-sources ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十一之铭文升级版
铭文一级: 第8章 Spark Streaming进阶与案例实战 黑名单过滤 访问日志 ==> DStream20180808,zs20180808,ls20180808,ww ==> ( ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记九之铭文升级版
铭文一级: 核心概念:StreamingContext def this(sparkContext: SparkContext, batchDuration: Duration) = { this(s ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记八之铭文升级版
铭文一级: Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, ...
随机推荐
- linux查看目录下所有文件内容中是否包含某个字符串
转发自:http://blog.csdn.net/yimingsilence/article/details/76071949 查找目录下的所有文件中是否含有某个字符串 find .|xargs gr ...
- go语言中container容器数据结构heap、list、ring
heap堆的使用: package main import ( "container/heap" "fmt" ) type IntHeap []int //我们 ...
- c#启动windows服务问题总结
程序以管理员权限运行的原因 在Vista 和 Windows 7 及更新版本的操作系统,增加了 UAC(用户账户控制) 的安全机制,如果 UAC 被打开,用户即使以管理员权限登录,其应用程序默认情况下 ...
- 8K - 圆桌会议
HDU ACM集训队的队员在暑假集训时经常要讨论自己在做题中遇到的问题.每当面临自己解决不了的问题时,他们就会围坐在一张圆形的桌子旁进行交流,经过大家的讨论后一般没有解决不了的问题,这也只有HDU A ...
- C# iframe session 丢失
在页面A中使用iframe引用另一站点页面B,但页面B上面的session总是丢失,百度了一下,不用改程序,直接在iis里面操作,解决方法如下 1.打开IIS管理器 inetmgr 2.选择被嵌入if ...
- Eigen解线性方程组
一. 矩阵分解: 矩阵分解 (decomposition, factorization)是将矩阵拆解为数个矩阵的乘积,可分为三角分解.满秩分解.QR分解.Jordan分解和SVD(奇异值)分解等,常见 ...
- TCP Nagle算法&&延迟确认机制
TCP Nagle算法&&延迟确认机制 收藏 秋风醉了 发表于 3年前 阅读 1367 收藏 0 点赞 0 评论 0 [腾讯云]买域名送云解析+SSL证书+建站!>>> ...
- BFS和DFS (java版)
package com.algorithm.test; import java.util.ArrayDeque; import java.util.Scanner; public class DfsA ...
- Startup.国外新锐公司及其技术Blog
国外技术公司Tech/Engineering Blog 1. vimeo https://coderwall.com/team/vimeo http://blog.assembly.com/ 2. l ...
- Java与go哪个更适合后端开发呢?哪个更适合新手呢?
Java语言目前在后端开发领域有广泛的应用,尤其是大型互联网平台往往选择Java作为主要的后端编程语言.同时,Java自身的生态比较健全,也有大量的成功案例,所以采用Java做后端编程语言是一个风险比 ...