使用jsoup爬取所有成语
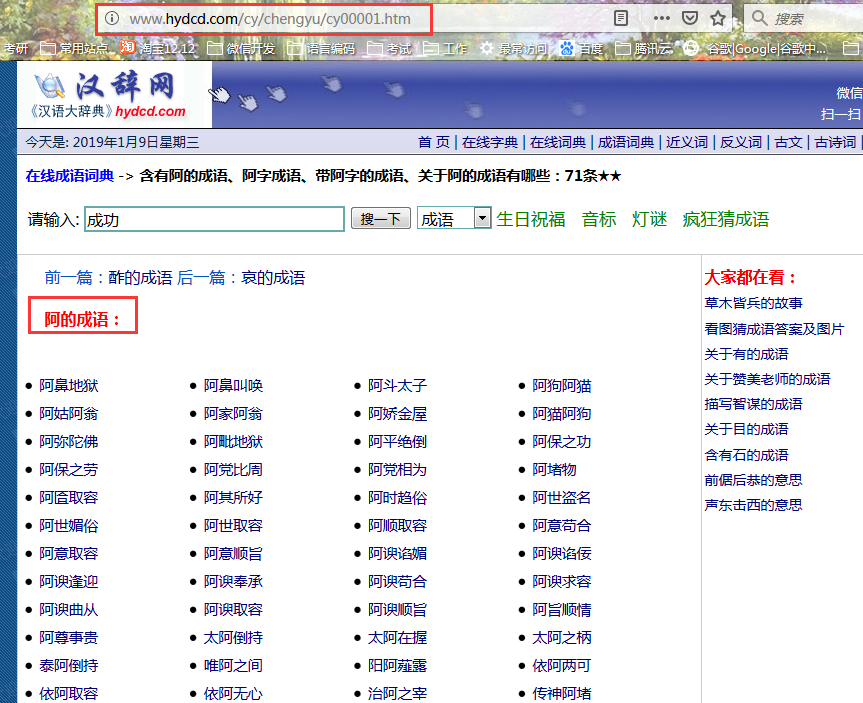
前几天看到有人在博问上求所有成语,想到刚好看了jsoup,就动手实践了一下,提问者给出了网站,一看很简单,就两种页面,一种是包含某个字的成语链接页面,一个是具体的包含某个字的成语的页面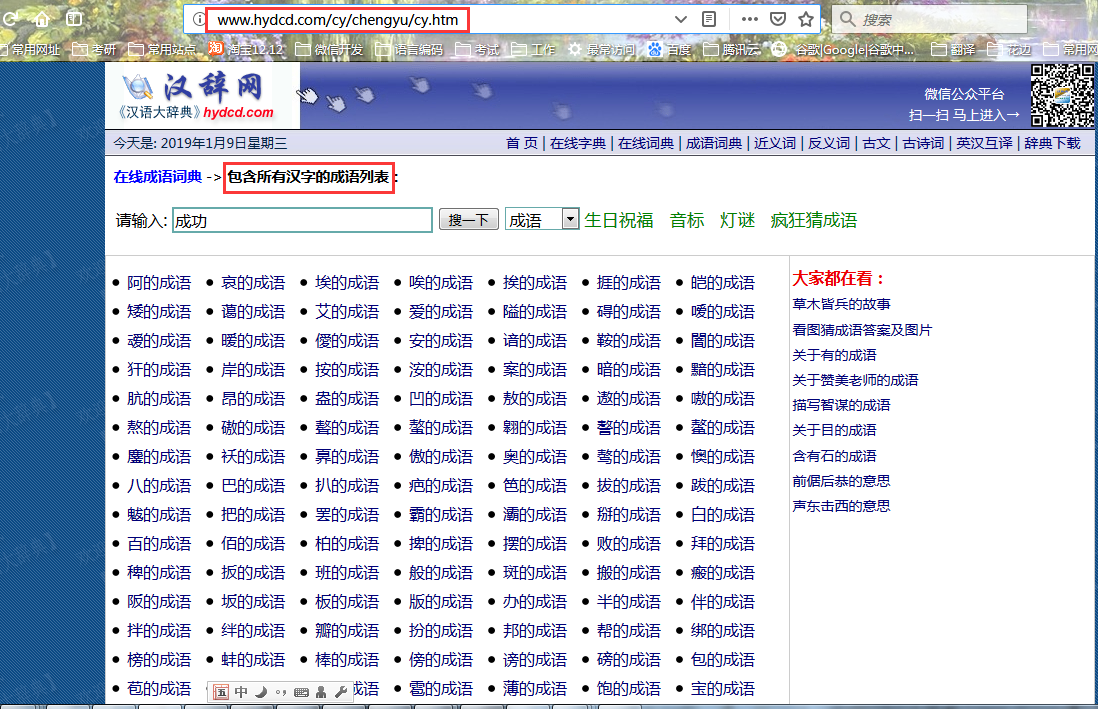
下面是我的代码,用到了jsoup的jar包
package cnblogs.spider; import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.net.URL;
import java.util.ArrayList;
import java.util.List; import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; public class IdiomScratch
{ public static void main(String[] args)
{
final String url = "http://www.hydcd.com/cy/chengyu/cy.htm";
final String urlSub = "http://www.hydcd.com/cy/chengyu/";
BufferedWriter writer = null;
try
{
Document doc = Jsoup.parse(new URL(url).openStream(), "gb18030", "http://www.hydcd.com");
Element cyTable = doc.getElementById("table1");
Elements aElements = cyTable.getElementsByTag("a");
List<String> aHrefs = new ArrayList<String>(); if(null != aElements && aElements.size() > 0)
{
for(int i = 0, size = aElements.size(); i < size; i++)
{
aHrefs.add(urlSub + aElements.get(i).attr("href"));
} File cytxt = new File("c://cengyu.txt");
if(!cytxt.exists())
{
cytxt.createNewFile();
} writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(cytxt)));
String cy = null; for(int i = 0, size = aHrefs.size(); i < size; i++)
{
doc = Jsoup.parse(new URL(aHrefs.get(i)).openStream(), "gb18030", "http://www.hydcd.com");
cyTable = doc.getElementById("table1");
aElements = cyTable.getElementsByTag("a"); if(null != aElements && aElements.size() > 0)
{
int b = 0;
for(int j = 0, size2 = aElements.size(); j < size2; j++)
{
cy = aElements.get(j).text(); writer.write(cy + " ");
b++;
if(b == 8)
{
b = 0;
writer.write("\r\n");
}
} writer.write("\r\n");
if(b != 0)
{
writer.write("\r\n");
}
writer.flush();
}
}
}
}
catch(IOException e)
{
e.printStackTrace();
}
finally
{
if(null != writer)
{
try
{
writer.close();
}
catch(IOException e)
{
e.printStackTrace();
}
}
}
} }
说一下碰到的坑,一开始没有注意编码问题,得到的txt结果中总有一些乱码,后来看网页源码显示编码是gb2312,就换成了gb2312,但还是不对,一想gb2312是简体字的,肯定不能包含所有的成语中的汉字啊,所有就查了一下汉字的编码,发现有gb18030,就用这个试了一下,果然没有乱码了
结果如下:
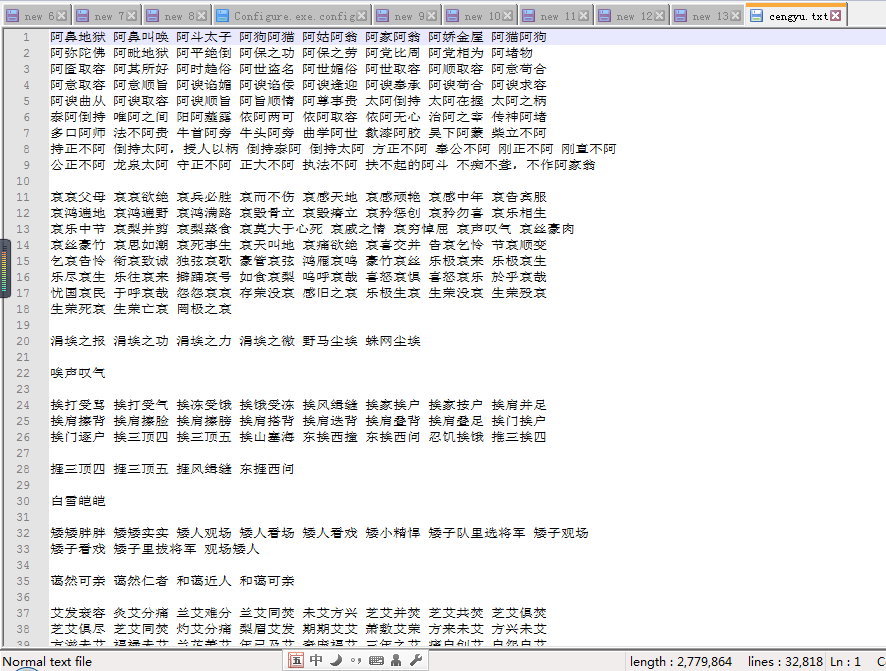
下面是所有成语的txt文件和代码:
使用jsoup爬取所有成语的更多相关文章
- Jsoup爬取带登录验证码的网站
今天学完爬虫之后想的爬一下我们学校的教务系统,可是发现登录的时候有验证码.因此研究了Jsoup爬取带验证码的网站: 大体的思路是:(需要注意的是__VIEWSTATE一直变化,所以我们每个页面都需要重 ...
- jsoup爬取某网站安全数据
jsoup爬取某网站安全数据 package com.vfsd.net; import java.io.IOException; import java.sql.SQLException; impor ...
- 使用Jsoup 爬取网易首页所有的图片
package com.enation.newtest; import java.io.File; import java.io.FileNotFoundException; import java. ...
- java爬虫入门--用jsoup爬取汽车之家的新闻
概述 使用jsoup来进行网页数据爬取.jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuer ...
- 使用Jsoup爬取网站图片
package com.test.pic.crawler; import java.io.File; import java.io.FileOutputStream; import java.io.I ...
- 如何使用Jsoup爬取网页内容
前言: 这是一篇迟到很久的文章了,人真的是越来越懒,前一阵用jsoup实现了一个功能,个人觉得和selenium的webdriver原理类似,所以今天正好有时间,就又来更新分享了. 实现场景: 爬取博 ...
- 利用Jsoup爬取新冠疫情数据并存至数据库
需要用到的jar包(用来爬取的jsoup,htmlunit-2.37.0-bin以及连接数据库中的mysql.jar) 链接:https://pan.baidu.com/s/1VlylWmlhjd8K ...
- 利用jsoup爬取百度网盘资源分享连接(多线程)
突然有一天就想说能不能用某种方法把百度网盘上分享的资源连接抓取下来,于是就动手了.知乎上有人说过最好的方法就是http://pan.baidu.com/wap抓取,一看果然链接后面的uk值是一串数字, ...
- jsoup爬取网站图片
package com.ij34.JsoupTest; import java.io.File; import java.io.FileOutputStream; import java.io.Inp ...
随机推荐
- PHP中常用的数组函数总结
整理了一份PHP开发中数组操作大全,包含有数组操作的基本函数,数组的分段和填充,数组与栈,数组与列队,回调函数,排序,计算,其他的数组函数等. 一,数组操作的基本函数 数组的键名和值 array_va ...
- 百度地图 android SDKv2.2.0
首先创建自己的KEY http://lbsyun.baidu.com/apiconsole/key 然后点击设置 参照官网文档点击下面连接 官网文档 http://developer.baidu.c ...
- 无法定位序数****于动态链接库LIBEAY32.dll上
问题出现原因: GNS3打开出现问题 尝试的方法如下: 创建脚本: @echo 开始注册 copy libeay32.dll %windir%\system32 regsvr32 %windir%\s ...
- Html的本质及在web中的作用
概要 本文以一个Socket程序为例由浅及深地揭示了Html的本质问题,同时介绍了作为web开发者我们在开发网站时需要做的事情 Html的本质以及开发需要的工作 1.服务器-客户端模型 其实,对于所有 ...
- [UE4]把枪打飞addImpulse
一.武器如果没有开启模拟物理,会漂浮在空中 二.武器开启模拟物理,运行游戏的时候就会掉到地上了.之所以要加“Delay”延迟,是因为创建武器在先(没有持有人),持有武器动作在后,加上“delay”延迟 ...
- Windows安装启动MySQL
Win安装MySQL数据库将下载下来的mysql解压到指定目录下,cmd切换到bin目录下>mysqld -install 安装服务>mysqld -remove 卸载服务>net ...
- cordova 常用操作
#创建插件 plugman create --name MyMath --plugin_id SimpleMath --plugin_version #进入插件目录 cd MyMath #plugin ...
- Elasticsearch分布式机制探究
Elasticsearch是一套分布式的系统,分布式是为了应对大数据量隐藏了复杂的分布式机制 分片机制 shard = hash(routing) % number_of_primary_shards ...
- 锚点定位,jquery定位到页面指定位置
jquery锚点定位 $('body,html').animate({scrollTop: $('#ter1').offset().top}, 500);#ter1是你要定位的id对象,500是0.5 ...
- solr defType查询权重排序
Solr的defType有dismax/edismax两种,这两种的区别,可参见:http://blog.csdn.net/duck_genuine/article/details/8060026 下 ...