百度 OCR API 的使用以及与 Tesseract 的简单对比
百度 OCR API 初探
近日得知百度在其 APIStore 上开放了 OCR 的 API,目前以 即用API 的形式试运行,所谓 "即用" 指可立即调用、无需注册付费,但也加上了有使用次数这么一个限制。
目前该 API 的文档很少,不过接口和参数都在其 API页面 进行了说明,要用起来还是没有问题的。下面是接口的信息
- 接口地址: http://apis.baidu.com/apistore/idlocr/ocr
- 请求方法: POST
相关的参数则有
| 参数名 | 类型 | 必填 | 参数位置 | 描述 | 可用值 |
|---|---|---|---|---|---|
| fromdevice | string | yes | bodyParam | 来源设备 | android, iPhone, pc |
| clientip | string | yes | bodyParam | 客户端出口ip | |
| detecttype | string | yes | bodyParam | OCR服务类型 | LocateRecognize, Recognize, Locate, SingleCharRecognize |
| languagetype | string | yes | bodyParam | 待检测的文字类型 | CHN_ENG, ENG, JAP, KOR |
| imagetype | string | yes | bodyParam | 图片资源类型 | 1: 经过BASE64处理的字符串; 2: 图片源文件 |
| image | string | yes | bodyParam | 图片资源,300K以下 | |
| apikey | string | yes | header | API 密钥 |
返回的结果会是一个 JSON 字符串,如下所示:
{
"errNum": 0,
"errMsg": "success",
"querySign": "3845925467,2370020290",
"retData": [
{
"rect": {
"left": "0",
"top": "0",
"width": "33",
"height": "31"
},
"word": " 8"
}
]
}
各字段的意义如下:
errNum
标识处理是否成功, 0: 表示成功, 其它值, 表示失败。在 API页面 上可以查看更详细的错误码列表。
errMsg
错误类型说明,当服务调用成功时为字符串 'success'
querySign
本次请求用户传递原图或rl的唯一标示, 方便定位问题
retData
返回内容集合
rect
该行文字所在的矩形区域的信息
word
该行所识别出的文字
用 Python 调用百度 OCR API
在 API 页面上倒是提供了 Python 的调用示例,不过个人感觉比较丑,居然还在使用 urllib !我们完全可以用 requests 来做这些事情,下面是我写的一个方法:
# -*- coding: utf-8 -*-
import requests URL = 'http://apis.baidu.com/apistore/idlocr/ocr'
LANG_LIST = ['CHN_ENG', 'ENG', 'JAP', 'KOR'] def ocr(picture, lang='CHN_ENG'):
"""Recognize a picture and return the text on it. picture could be a local picture or url of picture on web. lang should be one of CHN_ENG, ENG, JAP, KOR
"""
data = {}
data['fromdevice'] = "pc"
data['clientip'] = '10.10.10.0'
data['detecttype'] = 'Recognize'
data['imagetype'] = "2" if lang not in LANG_LIST:
raise Exception('invalid language: %s' % lang)
else:
data['languagetype'] = lang # 此处应使用自己的 API key
header = {"apikey": "your api key"} image_file = None
try:
if picture.startswith('http://') or picture.startswith('https://'):
image_file = requests.get(picture).content
else:
image_file = open(picture, 'rb').read()
except Exception:
raise Exception('invalid picture: %s' % picture) resp = requests.post(URL, headers=header, data=data, files={"image": ("baidu.jpg", image_file)}) if resp is not None:
resp = resp.json()
if int(resp.get('errNum')) != 0:
raise Exception(reps.get('errMsg'))
else:
return resp.get('retData')[0].get('word')
else:
return None
需要注意的是,虽然 API 页面上说图片目前仅支持 jpg 格式,但实际上对图片格式的检查很有可能是通过检查文件名的后缀来进行的,所以通过将 "imagetype" 设置为 2 并将图片以 jpg 作为后缀名进行上传来绕过这个限制。
然后拿一张图片来看看!好,就是下面这张了:
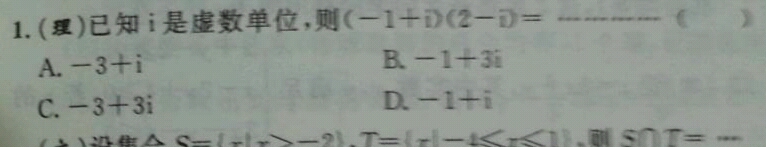
识别结果如下:

与 Tesseract 的简单对比
要比较全面、客观地对比出两个不同的产品的性能是需要大量的数据和详尽地设计的,这里只是根据我个人对 OCR 系统的认识,使用了少量的数据进行的对比,至于两者孰优孰劣请读者自行试验再下结论。
图一:
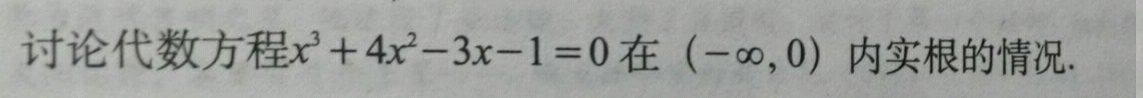
百度 OCR API 识别结果:
讨论代数方程r+积—劲—1=0在(—”0)内实根的情况
Tesseract 识别结果:
讨论代数方程娱+4筹-3χ-l=O在 (-∞,O〉 内实根的情况₋
图二:
百度 OCR API 识别结果:
L(理)已知:是虚数单位.则(―1―D《2―D=一一一一f》 A―3+iB―1―3 C―3+3D―1―1
Tesseract 识别结果:
L₍₋₎已概ᵢ量ᵦ效单位。口(—₁针)(2₋E,= ⋯烟~₋ (
A₋₋₃+ᵢ BL-{•S宜 C.-3+3i D·一l震拿 罐震 ,△、an.△ᵅ=₂₋!₋₃—?又₋T=xf —$⩽ᵣ⩽玉 ₋l S校 r= —
图三:

百度 OCR API 识别结果:
新课标全国)在一组样本数据(Xl,y)G,y)%不全相等的散点图中,若所有样本点ki,y4+|上,则这组样本数据的样本相关系数为0 Boc.号
Tesseract 识别结果:
!新课标全国)在岗组样本数据Uh趴汕懒h…
蘑. 不全相等)的散点图中,若所有样本点牺酬 L篆+I 上,则这组样本数据的样本相关系数为 o 1
B.0 时
图四:
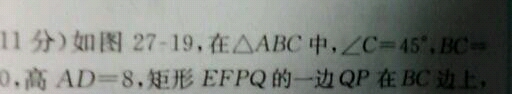
百度 OCR API 识别结果:
11分)如图271日.在△A风中,∠C=45·现妹10.高AD=8.矩形EFPQ的一边吐在风边上,1
Tesseract 识别结果:
.’⁻.∴ 、,〉 、、.罐’∣【
r\∪【川 '′ ∣⋃./L 、∥('中.
"pQ的
图五:

百度 OCR API 识别结果:
B
Tesseract 识别结果:
乐散说, 你是找的全部
你是耕掌希宁触-都余
但找的主命宁
猪漆能装有你 就傅
她环东能玻节玻引才
A美未能表有童气
大她东能装有四兔
从以上这些对比,我得到以下一些 不一定客观 的结论:
- 百度的 OCR 系统对噪声、模糊等有较强的抗干扰性,这一点上要优于 Tesseract
- 百度的 OCR 系统没有进行布局分析,但 Tesseract 在布局分析上做得比较好
- 百度的 OCR 系统 可能 对 黑底白字 的图像识别不好
百度 OCR API 的使用以及与 Tesseract 的简单对比
10 Jun 2015
百度 OCR API 初探
近日得知百度在其 APIStore 上开放了 OCR 的 API,目前以 即用API 的形式试运行,所谓 "即用" 指可立即调用、无需注册付费,但也加上了有使用次数这么一个限制。
目前该 API 的文档很少,不过接口和参数都在其 API页面 进行了说明,要用起来还是没有问题的。下面是接口的信息
- 接口地址: http://apis.baidu.com/apistore/idlocr/ocr
- 请求方法: POST
相关的参数则有
| 参数名 | 类型 | 必填 | 参数位置 | 描述 | 可用值 |
|---|---|---|---|---|---|
| fromdevice | string | yes | bodyParam | 来源设备 | android, iPhone, pc |
| clientip | string | yes | bodyParam | 客户端出口ip | |
| detecttype | string | yes | bodyParam | OCR服务类型 | LocateRecognize, Recognize, Locate, SingleCharRecognize |
| languagetype | string | yes | bodyParam | 待检测的文字类型 | CHN_ENG, ENG, JAP, KOR |
| imagetype | string | yes | bodyParam | 图片资源类型 | 1: 经过BASE64处理的字符串; 2: 图片源文件 |
| image | string | yes | bodyParam | 图片资源,300K以下 | |
| apikey | string | yes | header | API 密钥 |
返回的结果会是一个 JSON 字符串,如下所示:
{
"errNum": 0,
"errMsg": "success",
"querySign": "3845925467,2370020290",
"retData": [
{
"rect": {
"left": "0",
"top": "0",
"width": "33",
"height": "31"
},
"word": " 8"
}
]
}
各字段的意义如下:
errNum
标识处理是否成功, 0: 表示成功, 其它值, 表示失败。在 API页面 上可以查看更详细的错误码列表。
errMsg
错误类型说明,当服务调用成功时为字符串 'success'
querySign
本次请求用户传递原图或rl的唯一标示, 方便定位问题
retData
返回内容集合
rect
该行文字所在的矩形区域的信息
word
该行所识别出的文字
用 Python 调用百度 OCR API
在 API 页面上倒是提供了 Python 的调用示例,不过个人感觉比较丑,居然还在使用 urllib !我们完全可以用 requests 来做这些事情,下面是我写的一个方法:
# -*- coding: utf-8 -*-
import requests URL = 'http://apis.baidu.com/apistore/idlocr/ocr'
LANG_LIST = ['CHN_ENG', 'ENG', 'JAP', 'KOR'] def ocr(picture, lang='CHN_ENG'):
"""Recognize a picture and return the text on it. picture could be a local picture or url of picture on web. lang should be one of CHN_ENG, ENG, JAP, KOR
"""
data = {}
data['fromdevice'] = "pc"
data['clientip'] = '10.10.10.0'
data['detecttype'] = 'Recognize'
data['imagetype'] = "2" if lang not in LANG_LIST:
raise Exception('invalid language: %s' % lang)
else:
data['languagetype'] = lang # 此处应使用自己的 API key
header = {"apikey": "your api key"} image_file = None
try:
if picture.startswith('http://') or picture.startswith('https://'):
image_file = requests.get(picture).content
else:
image_file = open(picture, 'rb').read()
except Exception:
raise Exception('invalid picture: %s' % picture) resp = requests.post(URL, headers=header, data=data, files={"image": ("baidu.jpg", image_file)}) if resp is not None:
resp = resp.json()
if int(resp.get('errNum')) != 0:
raise Exception(reps.get('errMsg'))
else:
return resp.get('retData')[0].get('word')
else:
return None
需要注意的是,虽然 API 页面上说图片目前仅支持 jpg 格式,但实际上对图片格式的检查很有可能是通过检查文件名的后缀来进行的,所以通过将 "imagetype" 设置为 2 并将图片以 jpg 作为后缀名进行上传来绕过这个限制。
然后拿一张图片来看看!好,就是下面这张了:
识别结果如下:
与 Tesseract 的简单对比
要比较全面、客观地对比出两个不同的产品的性能是需要大量的数据和详尽地设计的,这里只是根据我个人对 OCR 系统的认识,使用了少量的数据进行的对比,至于两者孰优孰劣请读者自行试验再下结论。
图一:
百度 OCR API 识别结果:
讨论代数方程r+积—劲—1=0在(—”0)内实根的情况
Tesseract 识别结果:
讨论代数方程娱+4筹-3χ-l=O在 (-∞,O〉 内实根的情况₋
图二:
百度 OCR API 识别结果:
L(理)已知:是虚数单位.则(―1―D《2―D=一一一一f》 A―3+iB―1―3 C―3+3D―1―1
Tesseract 识别结果:
L₍₋₎已概ᵢ量ᵦ效单位。口(—₁针)(2₋E,= ⋯烟~₋ (
A₋₋₃+ᵢ BL-{•S宜 C.-3+3i D·一l震拿 罐震 ,△、an.△ᵅ=₂₋!₋₃—?又₋T=xf —$⩽ᵣ⩽玉 ₋l S校 r= —
图三:
百度 OCR API 识别结果:
新课标全国)在一组样本数据(Xl,y)G,y)%不全相等的散点图中,若所有样本点ki,y4+|上,则这组样本数据的样本相关系数为0 Boc.号
Tesseract 识别结果:
!新课标全国)在岗组样本数据Uh趴汕懒h…
蘑. 不全相等)的散点图中,若所有样本点牺酬 L篆+I 上,则这组样本数据的样本相关系数为 o 1
B.0 时
图四:
百度 OCR API 识别结果:
11分)如图271日.在△A风中,∠C=45·现妹10.高AD=8.矩形EFPQ的一边吐在风边上,1
Tesseract 识别结果:
.’⁻.∴ 、,〉 、、.罐’∣【
r\∪【川 '′ ∣⋃./L 、∥('中.
"pQ的
图五:
百度 OCR API 识别结果:
B
Tesseract 识别结果:
乐散说, 你是找的全部
你是耕掌希宁触-都余
但找的主命宁
猪漆能装有你 就傅
她环东能玻节玻引才
A美未能表有童气
大她东能装有四兔
从以上这些对比,我得到以下一些 不一定客观 的结论:
- 百度的 OCR 系统对噪声、模糊等有较强的抗干扰性,这一点上要优于 Tesseract
- 百度的 OCR 系统没有进行布局分析,但 Tesseract 在布局分析上做得比较好
- 百度的 OCR 系统 可能 对 黑底白字 的图像识别不好
百度 OCR API 的使用以及与 Tesseract 的简单对比的更多相关文章
- 利用百度地图API,获取经纬度坐标
利用百度地图API,获取经纬度坐标 代码很简单,但在网上没找到现成的获取地图经纬度的页面. 就是想,给当前页面传递一个经纬度,自动定位到此经纬度.然后可以重新选择,选择完返回经纬度. 效果如下: 源代 ...
- 百度地图api基本用法
首先 ,如果想调用百度地图api,你需要获取一个百度地图api的密钥. 申请密钥很简单,在百度地图api的首页就有相关链接,填写相关信息百度就会给你一个密钥了. 接下来,就是引入百度地图的api 关键 ...
- 百度地图API详解之事件机制,function“闭包”解决for循环和监听器冲突的问题:
原文:百度地图API详解之事件机制,function"闭包"解决for循环和监听器冲突的问题: 百度地图API详解之事件机制 2011年07月26日 星期二 下午 04:06 和D ...
- 使用Python基于百度等OCR API的文字识别
百度OCR Baidu OCR API:一定额度免费,目前是每日500次 Python SDK文档:https://cloud.baidu.com/doc/OCR/OCR-Python-SDK.htm ...
- PHP:基于百度大脑api实现OCR文字识别
有个项目要用到文字识别,网上找了很多资料,效果不是很好,偶然的机会,接触到百度大脑.百度大脑提供了很多解决方案,其中一个就是文字识别,百度提供了三种文字识别,分别是银行卡识别.身份证识别和通用文字识别 ...
- 一篇文章搞定百度OCR图片文字识别API
一篇文章搞定百度OCR图片文字识别API https://www.jianshu.com/p/7905d3b12104
- 百度OCR文字识别API使用心得===com.baidu.ocr.sdk.exception.SDKError[283604]
异常com.baidu.ocr.sdk.exception.SDKError[283604]App identifier unmatch.错误的packname或bundleId.logId::303 ...
- Ocr答题辅助神器 OcrAnswerer4.x,通过百度OCR识别手机文字,支持屏幕窗口截图和ADB安卓截图,支持四十个直播App,可保存题库
http://www.cnblogs.com/Charltsing/p/OcrAnswerer.html 联系qq:564955427 最新版为v4.1版,开放一定概率的八窗口体验功能,请截图体验(多 ...
- 利用百度OCR实现验证码自动识别
在爬取网站的时候都遇到过验证码,那么我们有什么方法让程序自动的识别验证码呢?其实网上已有很多打码平台,但是这些都是需要money.但对于仅仅爬取点数据而接入打码平台实属浪费.所以百度免费ocr正好可以 ...
随机推荐
- 2019.4.11 一题 XSY 1551 ——广义后缀数组(trie上后缀数组)
参考:http://www.mamicode.com/info-detail-1949898.html (log2) https://blog.csdn.net/geotcbrl/article/de ...
- java 子类父类相互转换
子类转父类 (父类引用指向子类对象) 子类可以转换为父类,如下父类FruitTest与其子类AppleTest class FruitTest { String str = "FruitTe ...
- angular2的ngfor ngif指令嵌套
angular2的ngfor ngif指令嵌套 ng2 结构指令不能直接嵌套使用,可使用<ng-container>标签来包裹指令 示例如下: <ul> <ng-cont ...
- OpenCV相机标定坐标系详解
在OpenCV中,可以使用calibrateCamera函数,通过多个视角的2D/3D对应,求解出该相机的内参数和每一个视角的外参数. 使用C++接口时的输入参数如下: objectPoints - ...
- 阿里云香港B区通过IPV6规避Google验证码
最近买了阿里云香港B来FQ,然而被Google的验证码折磨的死去活来.四处查询,终于找到了一个合适的方案. 添加IPV6支持 阿里云香港是没有IPV6地址的,需要一个tunnel,这边使用HE.NET ...
- 在本机将本机的ip和mac绑定
cmd命令框中输入arp -s ip mac即可绑定 解除绑定:arp -d ip
- Python 进制转换与位运算
十进制转二进制.八进制.十六进制: dec = int(input("输入数字:")) print("十进制数为:", dec) print("转换为 ...
- IKAnalyzer 添加扩展词库和自定义词
原文链接http://blog.csdn.net/whzhaochao/article/details/50130605 IKanalyzer分词器 IK分词器源码位置 http://git.osch ...
- mongodb 安装(官方说明链接)
这里面有很全的 https://docs.mongodb.com/manual/tutorial/install-mongodb-on-windows/ 先截个图吧,都是标准的流程,按照操作,是可以安 ...
- ThinkPHP 3.1.2 查询方式 -4
一.普通查询方式 a.字符串 $arr=$m->where("sex=0 and username='gege'")->find(); b.数组 $data['sex' ...