go项目
1、循环使用缓存
每条日志需要开辟缓存块来存储内容,以减少频繁的内存分配与回收。日志结构体定义如下:
type MLogger struct {
// freeList is a list of byte buffers, maintained under freeListMu.
freeList *buffer
// freeListMu maintains the free list. It is separate from the main mutex
// so buffers can be grabbed and printed to without holding the main lock,
// for better parallelization.
freeListMu sync.Mutex
// ...
}
已经开辟出的多个内存空间形成一个单链表,其中的freeList指向这个链表的头部。由于有多个go协程同时要操作这个单链表,如打印完日志后回收缓存,或者要求一个缓存块来存储日志内容。
首先看一下缓存的回收方法,如下::
// putBuffer returns a buffer to the free list.
func (l *MLogger) putBuffer(b *buffer) {
if b.Len() >= 1500 {
fmt.Println("buffer:%d\n",b.Len())
return // Let big buffers die a natural death(自然死).
}
l.freeListMu.Lock() // 上锁
b.next = l.freeList // 为下一个可用的buffer设置值
l.freeList = b // 为当前可用的freeList设置buffer
l.freeListMu.Unlock() // 解锁
}
当开辟的缓存块过大时不进行重复利用,以释放这些内存空间。
最主要的操作就是将不需要的缓存块插入到单链表的头部,然后让freeList指针指向新插入的缓存块即可。
获取缓存块:
// getBuffer returns a new, ready-to-use buffer. (获取一个新的,可使用的缓存)
func (l *MLogger) getBuffer() *buffer {
l.freeListMu.Lock() // 上锁
b := l.freeList
if b != nil {
l.freeList = b.next
}
l.freeListMu.Unlock() // 解锁
if b == nil {
b = new(buffer)
} else {
b.next = nil
b.Reset()
}
return b
}
在获取缓存块时需要优先考虑freeList中可用的缓存块,如果有就从链表头部取一个块返回(注意:必须调用Reset()方法,因为这个块中还缓存有上一次日志的信息),否则就创建一个新的缓存块返回。
2、创意检索算法
由于广告创意有多个定向条件,而Redis中缓存的数据结构为定向条件到创意集合的映射,如:
s_area_%d // 地域编码,如861100表示北京 s_network_%d // 网络定向,1表示2G、2表示3G、3表示4G、4表示WIFI s_os_%d // 1为ios,2为android
假设要检索出地域编码为861100、操作系统定向为ios,网络定向为WIFI的创意,而Redis中已经存在的数据集如下:
s_area_861100 = {1,4,6,7}
s_network_1 = {4,5,6}
s_os_1 = {1,5,6}
当检索创意时,新创建一个map,其key为创意ID,而值为创意出现的次数,如ID为4的创意在s_area_861100、s_network_1与s_os_1中出现了3次,则map为:
map[4] = 3
统计所有的创意出现的次数:
map[1] = 2
map[4] = 2
map[5] = 2
map[6] = 3
map[7] = 1
迭代这个map,检索出创意ID出现3次的所有创意,这些创意就是符合地域编码为861100、操作系统定向为ios,网络定向为WIFI的创意集合。
3、避免缓存穿透
为了在并发高的环境下减少IO次数,可以在本地缓存中缓存一些数据,当缓存一段时长时,重新从其它的数据源拉取最新的数据,这样减少IO的同时也能保证数据的时效性。但是当并发很高时,缓存在本地的数据在某个时刻过期,这里就会有多个请求同时做数据的拉取更新操作。如果数据源为MySQL数据库时,则无法承担很高的并发。
所以在数据过期时,需要控制只有一个请求做更新操作,其它请求等待或者直接返回,这取决于具体的业务
func (c *PowerCache) GetWithValueLoader(ctx context.Context,
key string, valueLoader ValueLoader) (interface{}, error) {
v, err := c.GetIfPresent(key) // 获取本地缓存中的数据
if err == nil { // 表示从本地缓存中取出了不过期的数据,直接返回即可
return v, err
}
// 代码点1
if atomic.CompareAndSwapInt32(&c.loadFlag, 0,1) { // 进行数据更新
v, err := c.GetIfPresent(key)
if err == nil {
c.loadFlag = 0
return v, err
}
// 从数据源拉取最新代码同时也会更新本地缓存数据
temp,tempErr :=c.loadWithValueLoader(ctx,key, valueLoader) // 代码点2
c.loadFlag = 1 // 代码点3
return temp,tempErr
}else {
time.Sleep(time.Millisecond * time.Duration(5))
v, err := c.GetIfPresent(key)
if err == nil {
return v, err
}
}
return nil,errors.New("Data Empty!") // 等待5毫秒后仍然没有从本地缓存中获取到最新的数据
}
其中涉及到一个原子API CompareAndSwapInt32,对全局的loadFlag原子性的进行比较交换。也就是loadFlag与0比较,如果相等则将loadFlag置为1。由于是原子性操作,所以只会有一个go协程调用方法后返回true。
进入后还要再一次从本地缓存中取一次数据,因为这个go协程可能在代码点1处,而另外一个更新数据的go协程已经走到了代码点3,将loadFlag设置为1。这时候这个协程直接调用GetIfPresent()方法获取数据返回即可。
代码点2在代码点3之后,避免由于本地缓存数据还未更新时,loadFlag置为1,导致更多的协程进入这个循环体内。
不更新数据的协程直接等待5毫秒后再次从本地缓存获取数据,如果取到直接返回,否则返回空。
5、流量请求分发
首先需要理解双管道类型:
func main() {
requestChan := make(chan chan string)
go GetResponse(requestChan)
go SendRequest(requestChan)
time.Sleep(time.Second) // 防止主协程过早退出,子协程跟着退出
}
func GetResponse(requestChan chan chan string) {
// 创建一个接收信息的小管道
responseChan := make(chan string)
// 将这个小管道通过公有的大管理传递给其它协程
requestChan <- responseChan
// 从小管道中接收信息
response := <-responseChan
fmt.Printf("Response: %v\n", response)
}
func SendRequest(requestChan chan chan string) {
// 从大管道中取出小管道
responseChan := <-requestChan
// 往小管道中写入内容
responseChan <- "helloworld!"
}
可以将chan chan 理解为大管道嵌套的小管道。如上例子打印内容如下:
Response: helloworld!
可以使用管道特性来控制go协程,因为协程在获取管道数据时,如果获取不到数据将阻塞等待。利用这个特性结合双管道可以模拟一个协程池,类似于线程池。这样就可以重复利用协程及管道来减少创建协程带来的性能损耗了。
先来参阅一篇文章,如下:
http://marcio.io/2015/07/handling-1-million-requests-per-minute-with-golang/
其基本的架构如下图:
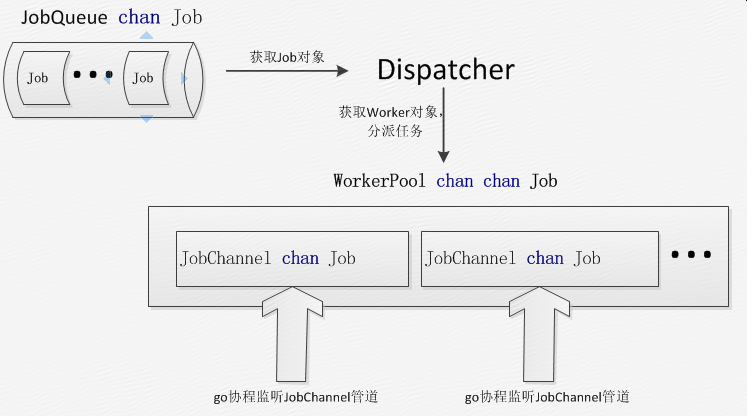
多个Request将任务放入了管道中,Dispatcher从管道中取出任务并从WorkerPool的大管道中取出一个Worker对象,将任务放入worker对象的管道JobChannel中。有几点值得注意:
(1)在WorkerPool中取出的Worker对象,这个Worker对象的JobChannel管道后监听的go协程一定是阻塞等待的,也就是说go协程没有其它的任务在执行。
(2)Dispatcher从大管道中取Worker对象,当这个Worker对象中的Jobchannel被协程处理完后,这个协程负责再次将这个Worker对象放入WorkerPool中。
AdExchange由于对请求处理的时间要求比较苛刻,并且要对多个返回结果进行筛选,所以架构与上面有所不同。
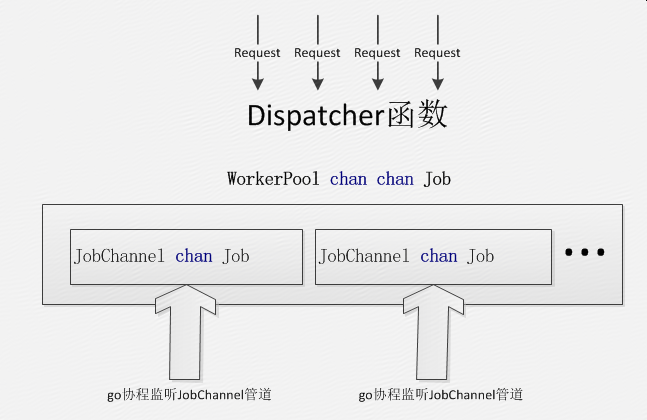
这个架构没有JobQueue这个队列,而Dispatcher也不是单个协程,而只是一个Dispatcher函数。所有的请求来时,由于每个请求都由一个go协程来处理,所以让这些go协程尽可能的多做与自身相关的任务,如将自己的Job分发出去,减少由单个Dispatcher分发带来的风险,提升分发效率。
初始化一个指定大小的线程池,代码如下:
func init(){
var MaxWorker = 200
WorkerPool = make(chan chan Job, MaxWorker)
for i := 0; i < MaxWorker; i++ {
worker := NewWorker(i+1, WorkerPool)
worker.Start()
}
}
调用了worker对象的Start()函数,这个函数的实现如下:
func (w Worker) Start() {
go func() {
for {
// 处理任务的协程负责将w.JobChannel重新放回大管道内
w.WorkerPool <- w.JobChannel
select {
case job := <-w.JobChannel:
// 处理具体的job任务
case <-w.QuitChan:
return // we have received a signal to stop
}
}
}()
}
Start()启动了一个协程,将Worker对象的JobChannel放入大管道内,表示这个协程没有在做任务,而是在监听JobChannel。
当Dispatcher从大管道内取出一个w.JobChannel时,往其中放入Job对象,这样上面的协程就能接收到任务,处理具体的Job任务了,处理完成后再将这个JobChannel放回大管道,供Dispatcher继续获取分派任务。
如Dispatcher分派任务,如下:
for _, val := range jobs {
select {
case worker := <-WorkerPool:
worker <- val
case <-time.After(time.Millisecond * time.Duration(5)):
return nil, errors.New("WorkerPool Blocking!")
}
}
从WorkerPool中取可用的JobChannel,如果取不到表示线程池中所有的协程都在做任务,已经没有空闲的协程了。
这样做的好处有:
(1)分离业务代码,如上代码分离了请求的分发、结果的筛选与请求的处理业务
(2)高效的并发模型 实现了线程安全,同时可以在每个协程内缓存数据块,无锁操作map等等
go项目的更多相关文章
- Fis3前端工程化之项目实战
Fis3项目 项目目录结构: E:. │ .gitignore │ fis-conf.js │ index.html │ package.json │ README.md │ ├─material │ ...
- 【原】Android热更新开源项目Tinker源码解析系列之三:so热更新
本系列将从以下三个方面对Tinker进行源码解析: Android热更新开源项目Tinker源码解析系列之一:Dex热更新 Android热更新开源项目Tinker源码解析系列之二:资源文件热更新 A ...
- 最近帮客户实施的基于SQL Server AlwaysOn跨机房切换项目
最近帮客户实施的基于SQL Server AlwaysOn跨机房切换项目 最近一个来自重庆的客户找到走起君,客户的业务是做移动互联网支付,是微信支付收单渠道合作伙伴,数据库里存储的是支付流水和交易流水 ...
- Hangfire项目实践分享
Hangfire项目实践分享 目录 Hangfire项目实践分享 目录 什么是Hangfire Hangfire基础 基于队列的任务处理(Fire-and-forget jobs) 延迟任务执行(De ...
- Travis CI用来持续集成你的项目
这里持续集成基于GitHub搭建的博客为项目 工具: zqz@ubuntu:~$ node --version v4.2.6 zqz@ubuntu:~$ git --version git versi ...
- 【原】Android热更新开源项目Tinker源码解析系列之一:Dex热更新
[原]Android热更新开源项目Tinker源码解析系列之一:Dex热更新 Tinker是微信的第一个开源项目,主要用于安卓应用bug的热修复和功能的迭代. Tinker github地址:http ...
- 【原】Android热更新开源项目Tinker源码解析系列之二:资源文件热更新
上一篇文章介绍了Dex文件的热更新流程,本文将会分析Tinker中对资源文件的热更新流程. 同Dex,资源文件的热更新同样包括三个部分:资源补丁生成,资源补丁合成及资源补丁加载. 本系列将从以下三个方 ...
- Angular企业级开发(5)-项目框架搭建
1.AngularJS Seed项目目录结构 AngularJS官方网站提供了一个angular-phonecat项目,另外一个就是Angular-Seed项目.所以大多数团队会基于Angular-S ...
- 【分享】标准springMVC+mybatis项目maven搭建最精简教程
文章由来:公司有个实习同学需要做毕业设计,不会搭建环境,我就代劳了,顺便分享给刚入门的小伙伴,我是自学的JAVA,所以我懂的.... (大图直接观看显示很模糊,请在图片上点击右键然后在新窗口打开看) ...
- ABP入门系列(2)——通过模板创建MAP版本项目
一.从官网创建模板项目 进入官网下载模板项目 依次按下图选择: 输入验证码开始下载 下载提示: 二.启动项目 使用VS2015打开项目,还原Nuget包: 设置以Web结尾的项目,设置为启动项目: 打 ...
随机推荐
- recovery 界面汉化过程详解
一. 主要是针对recovery汉化,主要汉化对象是界面显示为中文. 二. 基于中文的汉化,有两种方式,一种是基于GB2312的编码格式汉化,另外一种是基于unicode编码格式汉化.下面介绍unic ...
- VirtualBox网络连接方式
VirtualBox图形界面下有四种网络接入方式,它们分别是: 1.NAT 网络地址转换模式(NAT,Network Address Translation) 2.Bridged Adapter 桥接 ...
- 用户 'XXX\SERVERNAME$' 登录失败。 原因: 找不到与提供的名称匹配的登录名。 [客户端: ]
一工厂的中控服务器遇到了下面Alert提示,'XXX\SERVERNAME$' XXX表示对应的域名, SERVERNAME$(脱敏处理,SERVERNAME为具体的服务器名称+$),而且如下所示, ...
- java导出数据到excel里:直接导出和导出数据库数据
一.直接导出 package com.ij34.util; import java.io.FileNotFoundException; import java.io.FileOutputStream; ...
- mcelog用法详解
手动启动mcelog方法: # mcelog --daemon Run mcelog in daemon mode, waiting for errors from the kernel. 后台服务启 ...
- Linux进程调度器的设计--Linux进程的管理与调度(十七)
1 前景回顾 1.1 进程调度 内存中保存了对每个进程的唯一描述, 并通过若干结构与其他进程连接起来. 调度器面对的情形就是这样, 其任务是在程序之间共享CPU时间, 创造并行执行的错觉, 该任务分为 ...
- c/c++ 线性表之双向链表
c/c++ 线性表之双向链表 线性表之双向链表 不是存放在连续的内存空间,链表中的每个节点的next都指向下一个节点,每个节点的before都指向前一个节点,最后一个节点的下一个节点是NULL. 真实 ...
- ELK-elkstack-使用消息队列
日志通过logstash收集到redis,之后从logstash从redis读取数据存入到ES 1. logstash使用redis测试 通过标准输入到redis中 logstash配置与启动 [yu ...
- css点滴1—八种方式实现元素垂直居中
这里介绍实现元素垂直居中的方式,文章是参考了<css制作水平垂直居中对齐>这一篇文章. 1.行高和高度实现 这种方式实现单行垂直居中是很简单的,但是要保证元素内容是单行的,并且其高度是不变 ...
- 【C编程基础】C程序常用函数
基础知识 1.const const 修饰的数据类型是指常类型,常类型的变量或对象的值是不能被更新的. ; 或 ; //在定义该const变量时,通常需要对它进行初始化,因为以后就没有机会再改变它了 ...