今天开始学Pattern Recognition and Machine Learning (PRML),章节5.2-5.3,Neural Networks神经网络训练(BP算法)
转载请注明出处:http://www.cnblogs.com/xbinworld/p/4265530.html
这一篇是整个第五章的精华了,会重点介绍一下Neural Networks的训练方法——反向传播算法(backpropagation,BP),这个算法提出到现在近30年时间都没什么变化,可谓极其经典。也是deep learning的基石之一。还是老样子,下文基本是阅读笔记(句子翻译+自己理解),把书里的内容梳理一遍,也不为什么目的,记下来以后自己可以翻阅用。
5.2 Network Training
我们可以把NN看做一种通用的非线性函数,把输入向量x变换成输出向量y,可以类比于第一章中的多项式曲线拟合问题。给定输入集合 ,目标集合
,目标集合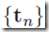 ,sum-of-squares error function定义为:
,sum-of-squares error function定义为:
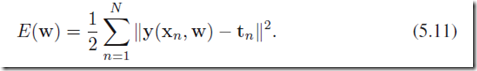
这一节主要主要是想说明error function也可以从最大似然估计的角度推导出来的。见(5.12-14)。这一部分从简了,有时间完善。
(case 1)上面的y可以是identity,即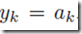
(case 2)当然也可以是二分类问题逻辑回归模型(可以参考第4章逻辑回归的内容),处理单一的2分类问题。
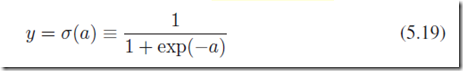
针对一个样本的类别的条件概率是一个伯努利分布Bernoulli distribution:
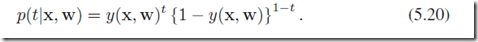
定义在数据集上的error function是cross-entropy:

有人证明,采用cross-entropy作为分类问题的目标函数可以比最小均方差泛化能力更强,以及训练更快。
(case 3)如果我们要做的分类是K个独立二分类分体,那么上面的条件分布修改为:
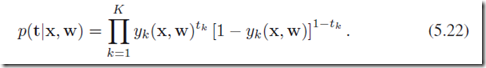
error funciton:
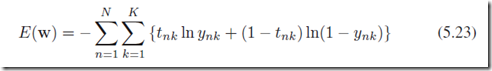

这里讲一讲参数共享,第一层的神经网络的参数实际上被output层所有神经元所贡献,这样的贡献可以减少了一定的计算量同时提高了泛化能力。
(case 4)当我们考虑不是独立二分类,而是1-of-K的分类问题,也就是说每一个结果是互斥的,我们需要采用softmax分类:
在数据集上error function定义:
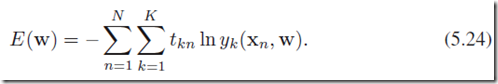
其中,softmax的激励函数定义为
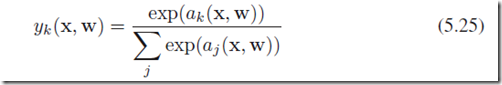

上面这一段说明了softmax的一个平移不变性的特性,但是会在regularization框架下消失。
总结一下:

下面讲一讲优化的方法:
5.2.4 Gradient descent optimization
梯度下降(GD)的公式是这样的:

这个也叫做batch model,梯度是定义在整个数据集上的,也就是是每一步迭代需要整个数据集。参数优化过程中每一步都是朝着error function下降最快的方向前进的,这样的方法就称为梯度下降算法,或者最速梯度下降。但是这样的方法比较容易找到局部最优(local optima),比如下面的图示,来自leftnoteasy


初始的时候我们在一个随机的位置,希望找到目标值最低的谷底,但是事实上我们并不知道我们找到的是不是global optima。上述batch model的优化方法,还有更快捷的方法,如conjugate gradients和quasi-Newton methods。如果要得到足够好的最小值,就需要多进行几轮GD,每次都选用不同的随即初始点,并在validation set中验证结果的有效性。
还有一种on-line版本的gradient descent(或者称为sequential gradient descent或者stochastic gradient descent),在训练神经网络的时候被证明非常有效。定义在数据集上的error function是每个独立样本的error function之和:

那么,on-line GD的更新公式是:

每次更新一个样本,方式是每次sequential取一个样本,或者有放回的random取。在onlineGD和GD之间还存在着中间形态,基于一个batch的数据。onlineGD的好处有:计算量小,同时更容易从有些local optima中逃出。
5.3 Error Backpropagation误差反向传导
在这一节中,我们会讨论一种快速计算前向网络误差函数E(w)梯度的方法——也就是著名的Error backpropagation算法,或者简称 backprop。
值得一提的是,backpropagation在其他地方也有类似的名称,比如在multilayer perceptron(MLP)经常也叫做backpropagation network。backpropagation在其中的意思是通过梯度下降的方法来训练MLP。事实上,大部分算法(训练)涉及一个迭代过程来最小化目标函数,在这个过程中基本上有两个阶段:一是计算error function的对于参数的导数,BP正是提供了一种计算所有参数导数的快速、有效方法;二是通过求出的导数来更新原来的参数,最常见的方法就是梯度下降方法。这两个阶段是相互独立的,这意味着BP算法的思想并不是只能用于MLP这样的网络,也不是只能用于均方误差这样的error function,BP可以被用于很多其他算法。
5.3.1 Evaluation of error-function derivatives
接下来我们来推导一下BP算法,条件是在一个任意拓扑结构的前向网络中,任意的可导的非线性激励函数,以及支持一系列error function(基本是很通用的了)。推导过程会用一个具有一个隐层的神经网络,以及均方误差的error function来说明。
常见的error function,定义在一个i.i.d(独立同分布)数据集上,有如下的形式:

下面我们会考虑针对error function其中的一项来求梯度,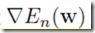 。这个结果可以直接用于序列优化(sequential optimization),或者把结果累加起来用于batch优化。(注:其实这个所谓序列优化就是现在广为人知的随机梯度下降。)
。这个结果可以直接用于序列优化(sequential optimization),或者把结果累加起来用于batch优化。(注:其实这个所谓序列优化就是现在广为人知的随机梯度下降。)
首先,我们先来考虑最为简单的线性output函数的情况:

y_k是对样本x的第k个输出(假设输出层有多个node),是x所有维度的一个线性组合。更一般性而言,我们定义在任意一个样本x_n上error function:
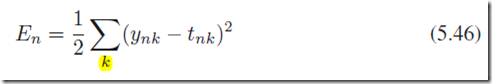
其中 ,上面error function针对参数
,上面error function针对参数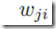 的梯度是:
的梯度是:

这个结果可以看做是一种“局部计算”——这个乘积一部分是误差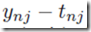 连接在权重
连接在权重 的输出端,另一部分是变量
的输出端,另一部分是变量 连接在权重
连接在权重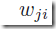 的输入端。上面的形式在逻辑回归中也出现过(章节4.3.2),在softmax中也是类似,下面来看在更一般的多层前向网络中是怎么样的。
的输入端。上面的形式在逻辑回归中也出现过(章节4.3.2),在softmax中也是类似,下面来看在更一般的多层前向网络中是怎么样的。
在一个一般结构的前向网络中,每个神经元(不算输入层)计算它输入的加权和:

其中zi是前面一个神经元(后面叫做节点或者node之类的都是同一个意思)的激励值输出,也是一个输入值输入到了节点j, 是这个连接的权重。在前面一篇今天开始学PRML-5.1节,我们介绍过,可以通过引入一个额外的输入节点且固定激励值是+1,我们可以把bias项合并在上面的累加中。因此,我们对待bias项是和对待其他的待估权重是一样的。然后得到节点j的激励函数的形式:
是这个连接的权重。在前面一篇今天开始学PRML-5.1节,我们介绍过,可以通过引入一个额外的输入节点且固定激励值是+1,我们可以把bias项合并在上面的累加中。因此,我们对待bias项是和对待其他的待估权重是一样的。然后得到节点j的激励函数的形式:

上面两个式子就说明了一个神经元获得输入值然后得到激励值输出的过程。对于训练集合中的任何一个样本,我们都反复通过上面两个式子,计算出所有隐藏神经元和输出神经元的激励值。这个过程就叫做向前传播,就像是一个向前的流经过网络一样。
下面来推导error function对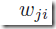 的导数,下面每一个节点的值都依赖于具体的样本n,但是为了清晰表达,省去了n这个标记。权重
的导数,下面每一个节点的值都依赖于具体的样本n,但是为了清晰表达,省去了n这个标记。权重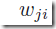 只能通过输入网络
只能通过输入网络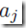 的值来影响神经元j,因此通过链式法则可以得到推导:
的值来影响神经元j,因此通过链式法则可以得到推导:

记

这个表示很重要,一般可以称为error(误差或者残差);从(5.48)可以得到:

于是可以得到:

和前面提到的线性模型一样,上面的导数也是由连接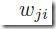 的输出端的误差和输入端输入值的成绩得到(z=1是bias项)。因此,关键就是计算网络中隐藏神经元和输出神经元的
的输出端的误差和输入端输入值的成绩得到(z=1是bias项)。因此,关键就是计算网络中隐藏神经元和输出神经元的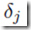 的值了。
的值了。
对于输出层,任何一个神经元k可以得到:

注:这个推导是直接从(5.46)来的,在书中用的是线性输出来推导的,即y_k=a_k。如果不是线性输出,而是个f(a_k),那么还要乘以一项f(a_k)的导数。
对于隐藏层,我们用链式法则:
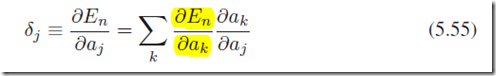
k代表所有j神经元的下一层神经元。这个式子的意思是说,j神经元对目标error function的影响是只能通过所有的所有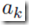 来实现的。通过(5.51)(5.48-49),可以得到
来实现的。通过(5.51)(5.48-49),可以得到

称为反向传导法则。到这里,大概可以看到为什么叫做“反向传导”了,可以从图5.7进一步了解:误差的传播是从输出层逐层回传的。先通过output层计算残差并求出最后一层参数,然后往回传播。

最后来总结一下BP算法的过程:(这里偷懒一下直接借用书上的总结啦:))

思路很清晰。如果用传统的梯度下降来求解,需要对所有的样本求出来的导数做累加,然后用于传统的梯度下降的公式中。

5.3.2 A simple example
下面来就一个稍微具体一点的例子说明一下:一个两层神经网络(如图5.1),输出层是线性输出,并且采用sum-of-squares误差,激励函数采用双曲正切函数tanh,
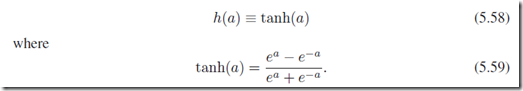
并且导数:

定义在一个样本n上面的误差函数:
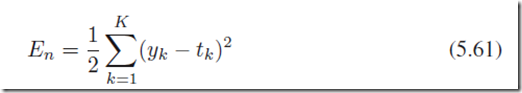
其中yk是输出值,tk是目标值;向前传播的过程可以描述为:
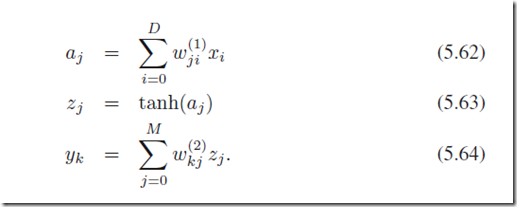
然后计算每一个输出神经元的残差和隐层神经元的残差:

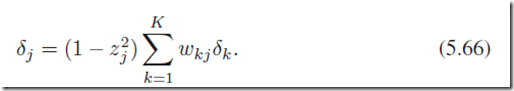
最后得到第一层参数和第二层参数的导数,分别用于梯度下降计算。
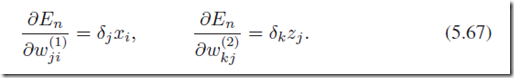
5.3.3 Efficiency of backpropagation
神经网络计算的一个主要问题是计算量大,在之前的模型中,如果有W数量的连接(神经元突触),那么一次前向传播的复杂度是O(W),而一般来说W是远远大于神经元节点数量的。
在5.48可以看到,每一个参数需要有一次乘法和一次加法。
另外一种求倒数的方式是用数值方法,
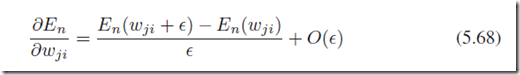
其中 ;数值方法计算精度是一个问题,我们可以把
;数值方法计算精度是一个问题,我们可以把 变的非常小,直到接近于精度的极限。采用symmetrical central differences可以大大盖上上述的精度问题:
变的非常小,直到接近于精度的极限。采用symmetrical central differences可以大大盖上上述的精度问题:
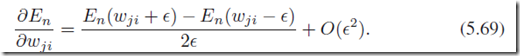
但是计算量差不多是(5.68)的两倍。实际上数值方法的计算不能利用前面的有用信息,每一次导数都需要独立计算,计算上并不能简化。
但是有意思的是数值导数在另外一个地方有用武之地——gradient check!我们可以用central differences的结果和BP算法中的导数进行比较,以此来判断BP算法执行是否是正确的。
今天开始学Pattern Recognition and Machine Learning (PRML),章节5.2-5.3,Neural Networks神经网络训练(BP算法)的更多相关文章
- 今天开始学习模式识别与机器学习Pattern Recognition and Machine Learning (PRML),章节5.1,Neural Networks神经网络-前向网络。
话说上一次写这个笔记是13年的事情了···那时候忙着实习,找工作,毕业什么的就没写下去了,现在工作了有半年时间也算稳定了,我会继续把这个笔记写完.其实很多章节都看了,不过还没写出来,先从第5章开始吧, ...
- Pattern Recognition And Machine Learning读书会前言
读书会成立属于偶然,一次群里无聊到极点,有人说Pattern Recognition And Machine Learning这本书不错,加之有好友之前推荐过,便发了封群邮件组织这个读书会,采用轮流讲 ...
- Pattern Recognition and Machine Learning (preface translation)
前言 鉴于机器学习产生自计算机科学,模式识别却起源于工程学.然而,这些活动能被看做同一个领域的两个方面,并且他们同时在这过去的十年间经历了本质上的发展.特别是,当图像模型已经作为一个用来描述和应用概率 ...
- Andrew Ng 的 Machine Learning 课程学习 (week4) Multi-class Classification and Neural Networks
这学期一直在跟进 Coursera上的 Machina Learning 公开课, 老师Andrew Ng是coursera的创始人之一,Machine Learning方面的大牛.这门课程对想要了解 ...
- Pattern recognition and machine learning 疑难处汇总
不断更新ing......... p141 para 1. 当一个x对应的t值不止一个时,Gaussian nosie assumption就不合适了.因为Gaussian 是unimodal的,这意 ...
- Pattern Recognition And Machine Learning (模式识别与机器学习) 笔记 (1)
By Yunduan Cui 这是我自己的PRML学习笔记,目前持续更新中. 第二章 Probability Distributions 概率分布 本章介绍了书中要用到的概率分布模型,是之后章节的基础 ...
- 学习笔记-----《Pattern Recognition and Machine Learning》Christopher M. Bishop
Preface 模式识别这个词,以前一直不懂是什么意思,直到今年初,才开始打算读这本广为推荐的书,初步了解到,它的大致意思是从数据中发现特征,规律,属于机器学习的一个分支. 在前言中,阐述了什么是模式 ...
- Pattern Recognition and Machine Learning 模式识别与机器学习
模式识别(PR)领域: 关注的是利⽤计算机算法⾃动发现数据中的规律,以及使⽤这些规律采取将数据分类等⾏动. 聚类:目标是发现数据中相似样本的分组. 反馈学习:是在给定的条件下,找到合适的动作, ...
- 今天开始学模式识别与机器学习(PRML),章节5.1,Neural Networks神经网络-前向网络。
今天开始学模式识别与机器学习Pattern Recognition and Machine Learning (PRML),章节5.1,Neural Networks神经网络-前向网络. 话说上一次写 ...
随机推荐
- Echo团队Alpha冲刺随笔 - 第五天
项目冲刺情况 进展 前端:布局,内容等方面基本完成. 后端:基本功能基本实现. 计划:准备进行前后端对接,进行测试 问题 有部分代码冗余,需要着手修改 心得 团队分工明确,互相协作,开发进度比预想的要 ...
- Python排序算法——选择排序
有趣的事,Python永远不会缺席! 如需转发,请注明出处:小婷儿的python https://www.cnblogs.com/xxtalhr/p/10787340.html 一.选择排序(Sele ...
- zookeepeer使用java api
一.引入依赖 <!-- https://mvnrepository.com/artifact/org.apache.zookeeper/zookeeper --> <dependen ...
- display:inline-block 来解决盒子高度不一样,造成的盒子浮动
<style> ul{ width: 320px; //给父元素添加这两个属性 font-size: 0px; text-align: center/left; } li{ width: ...
- python读取/创建XML文件
Python中定义了很多处理XML的函数,如xml.dom,它会在处理文件之前,将根据xml文件构建的树状数据存在内存.还有xml.sax,它实现了SAX API,这个模块牺牲了便捷性,换取了速度和减 ...
- (Beta)Let's-M2后分析报告
设想和目标 1. 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述? 在M1阶段我们对用户需求进行了调研,同时M1阶段我们的开发目标就是为了解决用户发起.参与.查看.搜 ...
- MySQL中myisam与innodb的区别
1. myisam与innodb的5点不同 1>.InnoDB支持事物,而MyISAM不支持事物 2>.InnoDB支持行级锁,而MyISAM支持表级锁 3>.InnoDB支持MV ...
- Effective java 43返回零长度的数组或者集合而不是null
- HDU 2003 求绝对值
http://acm.hdu.edu.cn/showproblem.php?pid=2003 Problem Description 求实数的绝对值. Input 输入数据有多组,每组占一行,每行 ...
- java依赖的斗争:依赖倒置、控制反转和依赖注入
控制反转(Inversion Of Controller)的一个著名的同义原则是由Robert C.Martin提出的依赖倒置原则(Dependency Inversion Principle),它的 ...