论文阅读笔记二十八:You Only Look Once: Unified,Real-Time Object Detection(YOLO v1 CVPR2015)

论文源址:https://arxiv.org/abs/1506.02640
tensorflow代码:https://github.com/nilboy/tensorflow-yolo
摘要
该文提出一种新的目标检测网络,yolo,以前的目标检测问题偏向于分类,而本文将目标检测看作是带有类别分数的回归问题。yolo从整张图上预测边界框和类别分数。是单阶段网络,可以进行端到端的训练。yolo处理速度十分迅速,每秒处理45帧图片。yolo在准确率上有待提升,但很少预测出假正的样例。
介绍
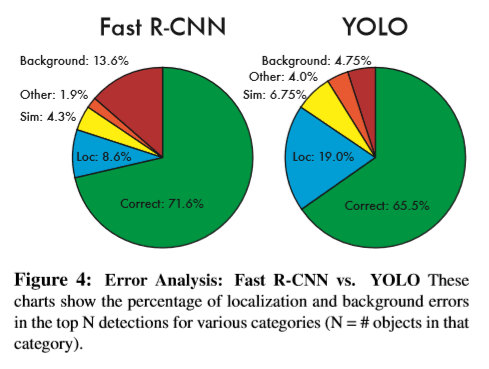
yolo的结构十分简洁,如下,一个单独的卷积网络,用于预测框的边界及每个框的类别概率 。相比传统的目标检测方式,yolo有以下几点优点:(1)速度十分快,可以适用于视频流的输入。(2)yolo对图片整体进行推理预测,而不是像基于窗口滑动的区域框的方式。由于yolo在训练和测试时是对整张图片进行分析,因此可以像编码外形信息一样对类别等抽象信息进行编码。Fast R-CNN有时会将背景误分类为目标,是因为不够多的上下文信息,而YoLo可以减少一般的这种错误情形。(3)YoLo学习的是整体的表示特征,对于新的输入,YoLOh还是有效的。
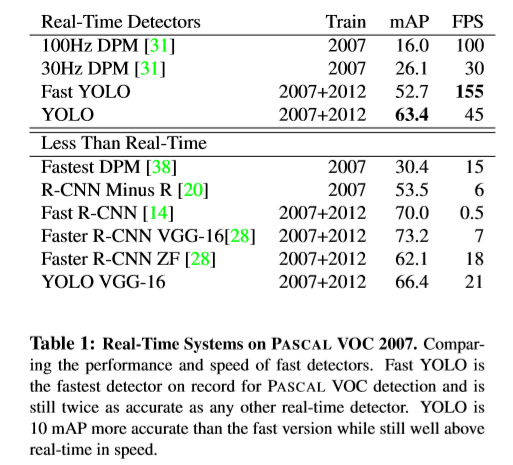
准确率上,YOLO仍有待提升,虽然速度快,但对目标尤其是小目标位置的精确定位相比最好的检测方法仍存在差距。

方法
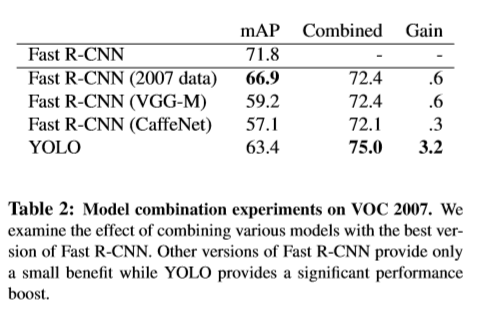
本文应用整个图片的特征预测每个边界框。可以同时预测所有类别的边界框。Yolo对整个图片和图片中的目标进行分析,YoLO的设计可以在保持较高平均准确率的基础上实时的进行预测,同时,可以进行端到端的训练。
Yolo将输入图片分为大小为SxS的格子,如果目标的中心落在了格子里,则这个格子就负责该目标的检测任务。每个网格单元预测B个边界框及对应的分数,表示该单元包含目标物体的置信度confident,同时,输出预测类别的分数。将置信度定义如下,
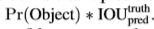
每个bounding box的预测5个值,(x,y,w,h)及confident,(x,y)为bounding box 的中心(相对于每个网格单元的偏移),预测出相对于整张图片的宽和高。
每个网格单元预测c个类别的条件概率,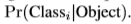 概率的计算的前提是,该网格单元包含目标物体。对于每个网格单元,不关预测出的B个bounding box,直接得到一系列类别的概率。
概率的计算的前提是,该网格单元包含目标物体。对于每个网格单元,不关预测出的B个bounding box,直接得到一系列类别的概率。
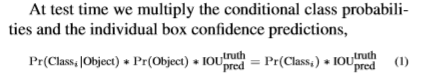
基于上式,可以得到每个框确定目标的confident 分数,同时,这个值也代表预测类别的准确率及预测框对目标物的符合程度。
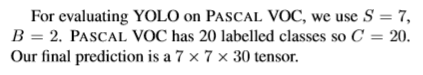
网络结构
模型为一个卷积网络,卷积层用于提取图像的特征,全连接层用于输出坐标和类别概率。该模型含有24层卷积层外加两层全连接层。结构如下
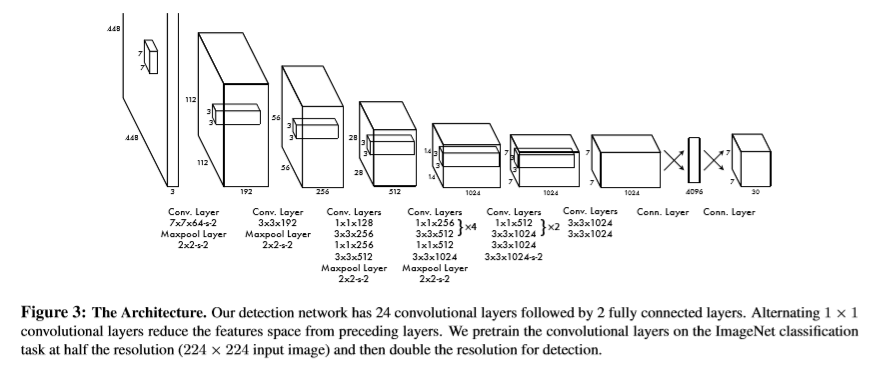
网络的训练
该文在ImageNet上预训练卷积网络,后增加4层卷积和两层全连接层,基于随机初始化操作。将预测框的宽和高用图片的原宽和高做归一化处理。将中心(x,y)作为单独网格单元的偏移量。本文对方差和误差进行优化处理,但由于参考了定位误差与类别误差,而许多bounding box中并未包含目标物,会使confidence变为0,从而对包含目标的检测误差的求导有影响,可能会导致收敛提前终止,进而 导致模型不稳定。
因此,本文增加了预测框损失的权重,而减少不包含目标的预测框损失的权重。在和平方误差中,大框和小框的误差权重是相同的。相比大框下的小偏差,小框的小偏差影响是较大的。因此,将预测边界框宽和高的平方根,而不是其直接得到的宽和高。

yolo对每个网格单元预测多个边界框,但训练时,只希望针对每个目标物体得到一个边界框预测器。该文将预测出的bounding box与ground truth IOU值最高的作为此目标的预测器。本文优化的损失函数如下:

注意:只惩罚存在目标的网格单元的类别损失和对应负责检测目标边界框预测器的框损失函数,原文如下。

为防止过拟合,本文采用dropout和数据增强操作。
yolo的限制因素
yolo对增强了预测框的空间限制,因为,每个网格单元只能预测两个边界框,及一个类别,因此,yolo对相邻目标的检测有点难度,像鸟群等小目标的检测。yolo直接从数据中学习并预测边界框,对非正常宽高比的物体检测效果不是很好,yolo网络中包含很多下采样层,对特征的学习不是很精细,对检测结果造成一定影响。对于损失函数,大物体与小物体的IOU对损失的贡献度相差不大,对于小物体,很小的IOU也会对网络造成很大影响,影响检测的结果。
实验
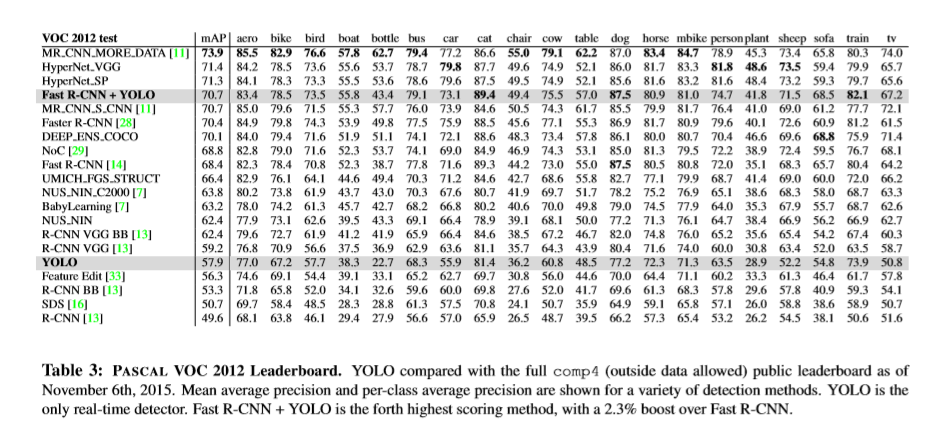

参考
[1] M. B. Blaschko and C. H. Lampert. Learning to localize objects with structured output regression. In Computer Vision– ECCV 2008, pages 2–15. Springer, 2008. 4
[2] L. Bourdev and J. Malik. Poselets: Body part detectors trained using 3d human pose annotations. In International Conference on Computer Vision (ICCV), 2009. 8
[3] H. Cai, Q. Wu, T. Corradi, and P. Hall. The crossdepiction problem: Computer vision algorithms for recognising objects in artwork and in photographs. arXiv preprint arXiv:1505.00110, 2015. 7
论文阅读笔记二十八:You Only Look Once: Unified,Real-Time Object Detection(YOLO v1 CVPR2015)的更多相关文章
- 论文阅读笔记四十八:Bounding Box Regression with Uncertainty for Accurate Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1809.08545.pdf github:https://github.com/yihui-he/KL-Loss 摘要 大规模的目标检测数据集在 ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
- 论文阅读笔记五十八:FoveaBox: Beyond Anchor-based Object Detector(CVPR2019)
论文原址:https://arxiv.org/abs/1904.03797 摘要 FoveaBox属于anchor-free的目标检测网络,FoveaBox直接学习可能存在的图片种可能存在的目标,这期 ...
- 论文阅读笔记二十九:SSD: Single Shot MultiBox Detector(ECCV2016)
论文源址:https://arxiv.org/abs/1512.02325 tensorflow代码:https://github.com/balancap/SSD-Tensorflow 摘要 SSD ...
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- 论文阅读笔记二十四:Rich feature hierarchies for accurate object detection and semantic segmentation Tech report(R-CNN CVPR2014)
论文源址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn 摘要 在PASCAL VOC数据集上,最好的方法的思路是将低级信息与较高层次的上下文信息进 ...
- 论文阅读笔记三十八:Deformable Convolutional Networks(ECCV2017)
论文源址:https://arxiv.org/abs/1703.06211 开源项目:https://github.com/msracver/Deformable-ConvNets 摘要 卷积神经网络 ...
- 论文阅读笔记二十六:Fast R-CNN (ICCV2015)
论文源址:https://arxiv.org/abs/1504.08083 参考博客:https://blog.csdn.net/shenxiaolu1984/article/details/5103 ...
- 论文阅读笔记二十二:End-to-End Instance Segmentation with Recurrent Attention(CVPR2017)
论文源址:https://arxiv.org/abs/1605.09410 tensorflow 代码:https://github.com/renmengye/rec-attend-public 摘 ...
随机推荐
- Javascript - ExtJs - Toolbar - 工具栏
Toolbar组件 创建工具栏 Toolbar类是一种子组件,它不能独立存在,需要依附在其它组件上面.很多容器组件都具备tbar(顶部工具栏).bbar(底部工具栏)的配置,所以可以像下面那样使用它. ...
- CSS 模块的侦测
CSS 的规格发展太快,新的模块层出不穷.不同浏览器的不同版本,对 CSS 模块的支持情况都不一样.有时候,需要知道当前浏览器是否支持某个模块,这就叫做“CSS模块的侦测”. 一个比较普遍适用的方法是 ...
- Dotest-两张图告诉你,为什么要测试兼容性?
这就是为什么要测试兼容性的原因:如下图:一个是IE浏览器.一个是Google浏览器
- 遗传算法selection总结-[Fitness, Tournament, Rank Selection]
假设个体(individual)用\(h_i\)表示,该个体的适应度(fitness)为\(Fitness(h_i)\),被选择的概率为\(P(h_i)\). 另外假设种群(population)的个 ...
- openstack Q版部署-----nova服务配置-控制节点(5)
一.创建数据库(控制节点) 创建数据库以及用户: CREATE DATABASE nova_api; CREATE DATABASE nova; CREATE DATABASE nova_cell0; ...
- CF1100D Dasha and Chess
题目地址:CF1100D Dasha and Chess 这是我的第一道交互题 思路不难,主要讲讲这条语句: fflush(stdout); stdout是标准输出的意思.因为有时候,我们输出到std ...
- MySQL用source命令导入不记入binlog中【原创】
试验环境,MySQL主主复制 主库10.72.16.112 从库10.72.16.50 一直有个疑问,利用sql_log_bin=0可以临时在客户端停止将操作记入binlog中,如果使用source命 ...
- VC操作excel
http://www.cnblogs.com/witxjp/archive/2010/06/05/1752181.html 最近在做个数据库程序,因为有些数据用户要求导出到Excel文件显示(需要 ...
- zabbix3.0.4利用iostat工具监控centos主机磁盘IO
该监控基于iostat,然后iostat 命令用来监视系统输入/输出设备负载 1.安装IOSTAT工具 # yum install sysstat -y 测试iostat 查看所有硬盘io # ios ...
- mybatis:访问静态变量或方法
访问方法: <if test="@com.csget.constant.ConstantApp@getUser('mobile')== 'kf'"> <![CDA ...