python爬虫慕课基础1



test_urllib2.py
import http.cookiejar
from urllib import request url = "http://www.baidu.com"
print('第一种方法') response1 = request.urlopen(url)
print(response1.getcode())
print(len(response1.read())) print("第二种方法")
req = request.Request(url)
req.add_header("user-agent","Mozilla/5.0")
response2 = request.urlopen(req)
print(response2.getcode())
print(len(response2.read())) print('第三种方法') cj = http.cookiejar.CookieJar()
opener = request.build_opener(request.HTTPCookieProcessor(cj))
request.install_opener(opener)
response3 = request.urlopen(url)
print(response3.getcode())
print(cj)
print(response3.read())





test_bs4.py:
import re
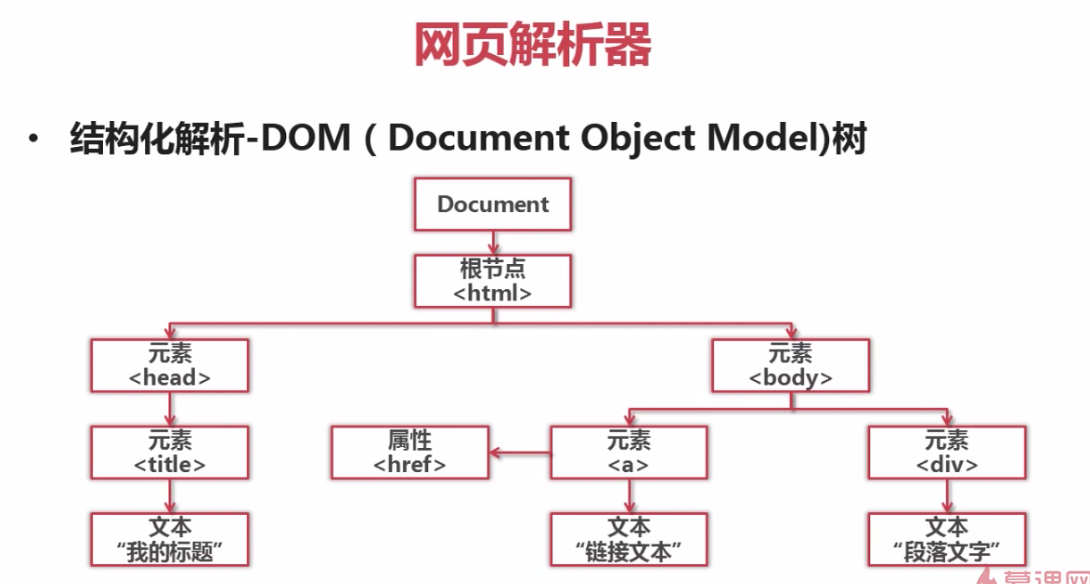
from bs4 import BeautifulSoup # 文档字符串
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
""" soup = BeautifulSoup(html_doc, 'html.parser')
# python3 缺省的编码是unicode, 再在from_encoding设置为utf8, 会被忽视掉, 故去掉,否则会报错 # 第一种方法
print('获取所有的链接')
links = soup.find_all('a')
for link in links:
print(link.name, link['href'], link.get_text()) # 第二种方法
print('获取lacie的链接')
link_node = soup.find('a', href='http://example.com/lacie')
print(link_node.name, link_node['href'], link_node.get_text()) # 第三种方法
print('正则匹配')
link_node = soup.find('a', href=re.compile(r'ill'))
print(link_node.name, link_node['href'], link_node.get_text()) # 第四种方法
print('获取p段落文字')
p_node = soup.find('p', class_='title')
print(p_node.name, p_node.get_text())
python爬虫慕课基础1的更多相关文章
- python爬虫慕课基础2
实战演练:爬取百度百科1000个页面的数据 对于新手来说,可以把spider_main.py代码中的try和except去掉,运行报错就会在控制台出现,根据错误去调试自己的程序 发现以下错误: req ...
- Python 爬虫四 基础案例-自动登陆github
GET&POST请求一般格式 爬取Github数据 GET&POST请求一般格式 很久之前在讲web框架的时候,曾经提到过一句话,在网络编程中“万物皆socket”.任何的网络通信归根 ...
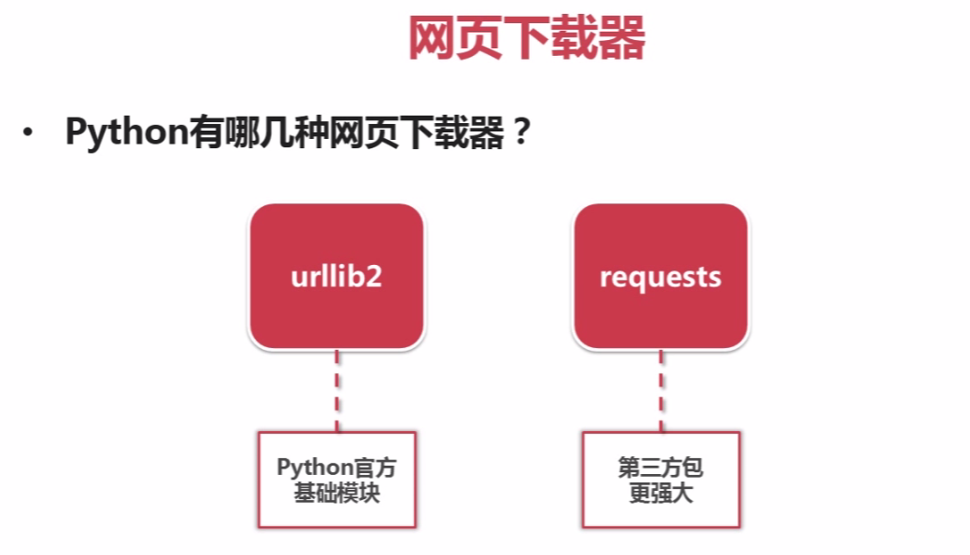
- python爬虫相关基础概念
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.但是php在实现爬虫中支持多线程和多进程方面做得不好. 2.java ...
- Python爬虫零基础入门(系列)
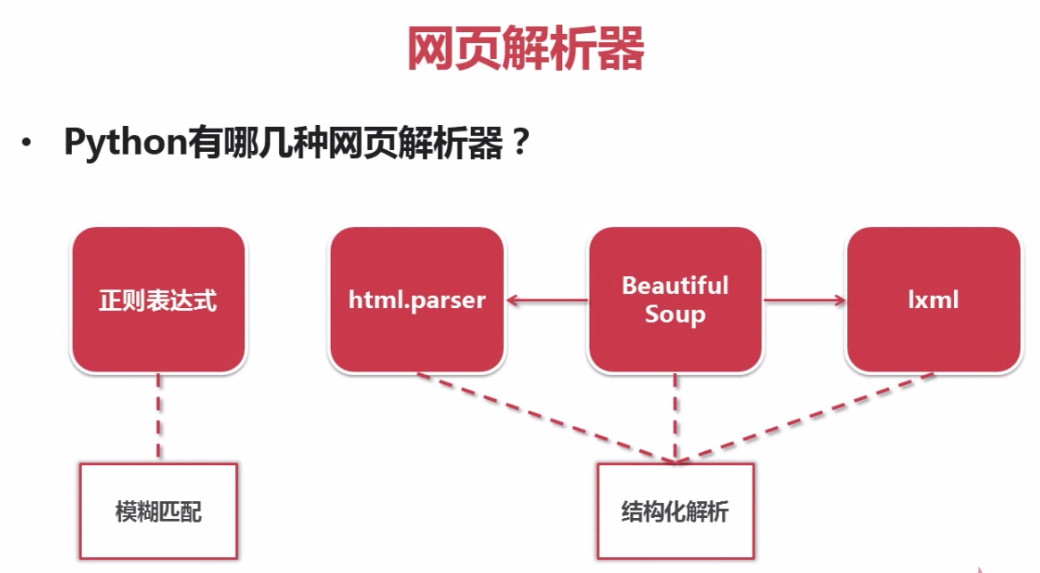
一.前言上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据.这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据. update ...
- Python爬虫-正则表达式基础
import re #常规匹配 content = 'Hello 1234567 World_This is a Regex Demo' #result = re.match('^Hello\s\d\ ...
- python爬虫之认识爬虫和爬虫原理
python爬虫之基础学习(一) 网络爬虫 网络爬虫也叫网络蜘蛛.网络机器人.如今属于数据的时代,信息采集变得尤为重要,可以想象单单依靠人力去采集,是一件无比艰辛和困难的事情.网络爬虫的产生就是代替人 ...
- Python爬虫入门(1-2):综述、爬虫基础了解
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- Python实战:爬虫的基础
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕 ...
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
随机推荐
- IDEA添加配置文件到classpath
突然发现有一种简单的办法: IDEA 的 Mark Directory as 右键项目中的一个文件夹,会出现目录[Mark Directory as]选择[Resources Root] 实现下面原文 ...
- day5 模拟用户登录
_user= "yangtuo" _passwd = " # passd_authentication = False #flag 标志位 for i in range( ...
- 使用unittest单元测试框架对加法做单元测试
import unittest from parameterized import parameterized def cacl(a, b): return a+b class MyCacl(unit ...
- 生命不息,折腾不止 ~ 旧PC改造之家庭影音
前言引入 之前把在校园陪伴多年的旧电脑由Win装成了Linux,的确不卡了,基本上日常办公也够了(大项目还是吃不消,日常捣鼓倒是够了),然后把真正的工作游戏本也改成了Linux,那么旧电脑又变成闲置机 ...
- java 不定长参数
一,不定长参数的规定 一个方法只能有一个不定长参数,并且这个不定长参数必须是该方法的最后一个参数. 示例: public class VariArgs { public static void mai ...
- A1144. The Missing Number
Given N integers, you are supposed to find the smallest positive integer that is NOT in the given li ...
- 删除文件夹下面的文件的shell命令
首先看我的文件所在目录 我想删除位于desktop下面的helloBox中的react-hello-dimple中的package.json文件,我们注意一下时间是4月18号 shell命令如下 $ ...
- double free or corruption错误
这是我自己写代码是遇到的错误,完全想不到报错和写错的地方有关联性,记录下来给别人参考. 不允许转载. WhiteBack(&cut_buff,&out_buff,5)函数内有一段 be ...
- SpringBoot文件上传
先建工程 只勾选web和freemarker模板 最后 先看一下最终目录结构 先修改pom文件,加入common-io依赖 然后修改Application.yml文件 spring: freemark ...
- IDEA2017.3.5破解
首先下载好idea, https://www.jetbrains.com/idea/download/previous.html 下载破解文件: https://pan.baidu.com/s/1tB ...