Forward团队-爬虫豆瓣top250项目-开发文档
项目地址:https://github.com/xyhcq/top250
我在本次项目中负责写爬虫中对数据分析的一部分,根据马壮分析过的html,我来进一步写代码获取数据,具体的功能及实现方法我已经写在了注释里:
首先,通过访问要爬的网站,并将网站保存在变量里,为下一步数据分析做准备
def getData(html):
# 分析代码信息,提取数据
soup = BeautifulSoup(html, "html.parser")
这时,如果我们print soup,是会在窗口上显示出网站的源代码的。
先把第一部电影信息的源代码放这,便于理解

首先,我们要爬取电影名字,我们经过分析(网页代码层次还是比较清晰的)
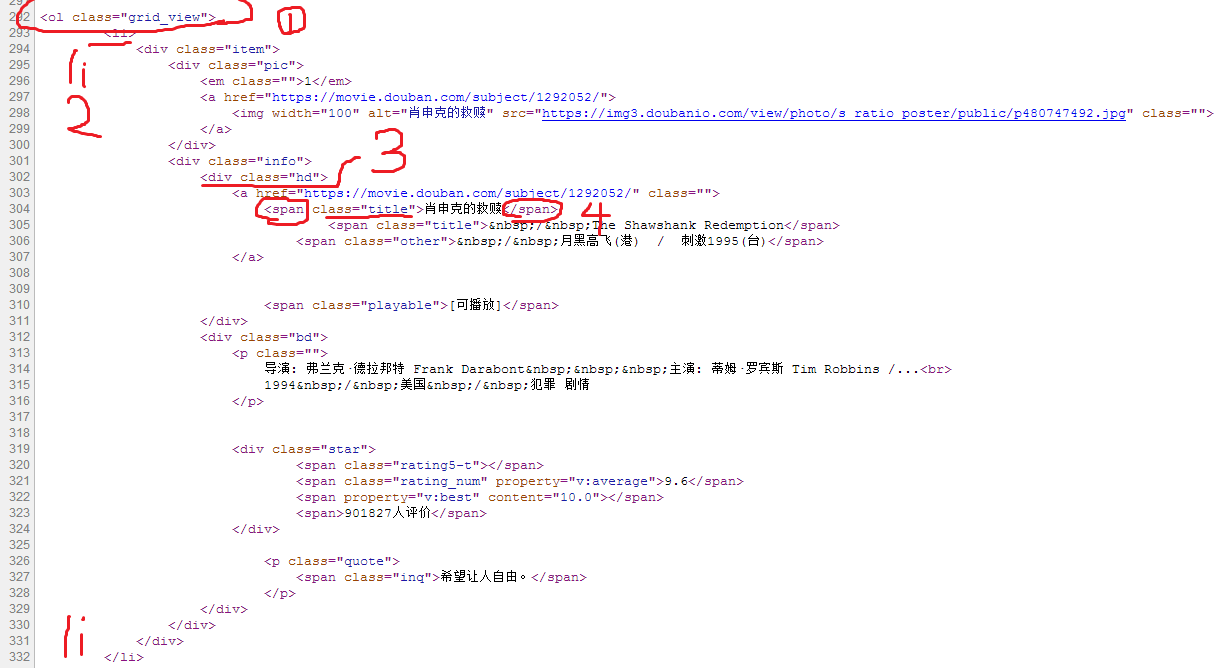
然后就可以写出爬取名字的部分了,
# 找到第一个class属性值为grid_view的ol标签
movieList=soup.find('ol',attrs={'class':'grid_view'}) # 找到所有的li标签
for movieLi in movieList.find_all('li'):
# 找到第一个class属性值为hd的div标签
movieHd=movieLi.find('div',attrs={'class':'hd'})
# 找到第一个class属性值为title的span标签 # 获取电影名字
movieName=movieHd.find('span',attrs={'class':'title'}).getText()
print movieName
经过运行,名字也确实能爬去并显示了,然后我们还是按照这种找标签的方法,以此类推,就能抓取其他的信息了:
# 获取电影链接
movieUrl=movieHd.find('a class="" href="')
print movieUrl # 获取电影导演/演员
movieBd = movieLi.find('div', attrs={'class': 'bd'})
movieSF=movieBd.find('p',attrs={'class':''}).getText()
print movieSF # 获取电影的评分
movieScore=movieLi.find('span',attrs={'class':'rating_num'}).getText()
print movieScore #获取电影的评论数
movieEval=movieLi.find('div',attrs={'class':'star'})
movieEvalNum=re.findall(r'\d+',str(movieEval))[-1]
print movieEvalNum
这里要说一下,如果找不到标签,有时候程序会卡住不动,排查发现问题出在简评上,所以;
# 获取电影短评
movieQuote = movieLi.find('span', attrs={'class': 'inq'})
# 有的电影没有短评,为防止报错,加次
if(movieQuote):
print movieQuote.getText()
else:
print ('没有短评!')

Forward团队-爬虫豆瓣top250项目-开发文档的更多相关文章
- 《Forward团队-爬虫豆瓣top250项目-开发文档》
码云地址:https://github.com/xyhcq/top250 模块功能:获取豆瓣top250网页的源代码,并分析. def getHTMLText(url,k): # 获取网页源代码 tr ...
- Forward团队-爬虫豆瓣top250项目-设计文档
组长地址:http://www.cnblogs.com/mazhuangmz/p/7603594.html 成员:马壮,李志宇,刘子轩,年光宇,邢云淇,张良 设计方案: 1.能分析HTML语言: 2. ...
- 《Forward团队-爬虫豆瓣top250项目-设计文档》
成员:马壮,李志宇,刘子轩,年光宇,邢云淇,张良 设计方案: 1.能分析HTML语言: 2.提取重要数据,并保存为文本文档: 3.用PY代码调取文本文档的数据: 4.编写提取部分数据的python代码 ...
- 爬虫豆瓣top250项目-开发文档
项目托管平台地址:https://github.com/gengwenhao/GetTop250.git 负责内容:1.使用python的request库先获取网页内容下来 2.再使用一个好用的lxm ...
- Forward团队-爬虫豆瓣top250项目-项目总结
托管平台地址:https://github.com/xyhcq/top250 小组名称:Forward团队 组长:马壮 成员:李志宇.刘子轩.年光宇.邢云淇.张良 我们这次团队项目内容是爬取豆瓣电影T ...
- Forward团队-爬虫豆瓣top250项目-最终程序
托管平台地址:https://github.com/xyhcq/top250 小组名称:Forward团队 小组成员合照: 程序运行方法: 在python中打开程序并运行:或者直接执行程序即可运行 程 ...
- Forward团队-爬虫豆瓣top250项目-项目进度
项目地址:https://github.com/xyhcq/top250 我们的项目是爬取豆瓣top250的电影的信息,在做这个项目前,我们都没有经验,完全是从零开始,过程中也遇到了很多困难,不过我们 ...
- Forward团队-爬虫豆瓣top250项目-模块测试
项目托管平台地址:https://github.com/xyhcq/top250 模块测试:爬虫对信息的处理部分 测试方法: 实际运行一下代码: 可以看见,信息都已经爬取出来了 其他补充说明: 原本系 ...
- Forward团队-爬虫豆瓣top250项目-模块开发过程
项目托管平台地址:https://github.com/xyhcq/top250 开发模块功能: 爬虫对信息的处理部分 开发时间:5天的下午空余时间(每天大约1小时,边学模块的使用边开发) 实现了:爬 ...
随机推荐
- windows操作系统python selenium webdriver安装
这几天想搞一个爬虫,就来学习一下selenium,在网上遇见各种坑,特写一篇博文分享一下selenium webdriver的安装过程. 一.安装selenium包 pip install selen ...
- PHP 构造方法 __construct()和PHP 析构方法 __destruct()
PHP 构造方法 __construct() 允许在实例化一个类之前先执行构造方法. 构造方法 构造方法是类中的一个特殊方法.当使用 new 操作符创建一个类的实例时,构造方法将会自动调用,其名称必须 ...
- Android判断一个点是否在矩形区域内
个人遇到的问题判断按钮的点击事件还是滑动事件 private boolean button1Down = false; private boolean button2Down = false; pri ...
- ambiguous
ambiguous - 必应词典 美[æm'bɪɡjuəs]英[æm'bɪɡjuəs] adj.模棱两可的:含混不清的:多义的:不明确的 网络含糊的:模糊的:暧昧的 搭配ambiguous answe ...
- command not found解决方案
如果新装的系统,运行一些很正常的诸如:shutdown,fdisk的命令时,悍然提示:bash:command not found.那么 首先就要考虑root 的$PATH里是否已经包含了这些环境变量 ...
- 再次认识void
重新认识void 在初学c/c++时感觉void是一个很不起眼的关键字.因为在c++中我使用的还是比较少的.但是到了Linux中,不论是在内核源码中还是在程序编写的过程中有关void与*的组合随处可见 ...
- Ubuntu 16.04 安装Kinect V2驱动
1.下载源代码 git clone https://github.com/OpenKinect/libfreenect2.git 2.依赖项安装 sudo apt-get install build- ...
- 20164319 刘蕴哲 Exp1 PC平台逆向破解
[实践内容概述] 本次实践的对象是一个名为pwn1的linux可执行文件. 该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串. 该程序同时包含另一个代码片段,ge ...
- JAVA常用注解
摘自:https://www.cnblogs.com/guobm/p/10611900.html 摘要:java引入注解后,编码节省了很多需要写代码的时间,而且精简了代码,本文主要罗列项目中常用注解. ...
- 关于TCP窗口大小
窗口字段 TCP Window字段用于接收端通知发送端:接收端当前能够接收的字节数(即当前允许发送端发送的字节数).在TCP Header中占有16bit长度,如下所示 0 1 2 3 0 1 2 3 ...