Empirical Evaluation of Speaker Adaptation on DNN based Acoustic Model
DNN声学模型说话人自适应的经验性评估
年3月27日
发表于:Sound (cs.SD); Computation and Language (cs.CL); Audio and Speech Processing (eess.AS)
说话人自适应时从说话人无关模型中估计一个说话人相关的声学模型,以减小训练集与测试集由于说话人差异导致的不匹配。
已经出现了许多DNN自适应方法,但是缺乏实验比较。
声学模型采用TDNN-LSTM声学模型。
自适应源时标准中文普通话声学模型
自适应目标是带口音的中文普通话声学模型
本文对三种典型的说话人自适应方法:
- LIN
- LHUC
- KLD
进行经验性评估。对上述三种模型及其组合进行了性能比较。
关于说话人口音程度对说话人自适应性能的影响,本文也进行了测试。
训练-测试不匹配:训练集不能匹配新声学环境或者不能泛化至新的说话人。
为了解决未见过说话人识别问题以及声学环境不匹配问题,提出了多种声学模型补偿和自适应方法。
DNN自适应方法可以粗略地分为三类:
- 说话人适应层插入方法
LIN、LHN、LON是最常见的说话人适应层插入方法,其中LIN最常用。
LHUC(Learning Hidden Unit Contribution)是说话人适应层插入方法地新类型,通过插入特殊的层以控制隐层的幅值(amplitude),使得SI网络参数变得说话人相关。
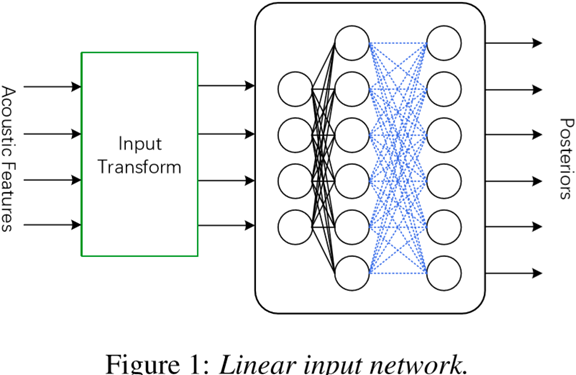
LIN的训练通常使用一个较小的学习率,如0.00001。
- 子空间方法
目标是找到一个用于自适应的低维说话人子空间。最直觉的应用是使用基于子空间的特征,如:i-Vectors,作为神经网络声学模型训练中的增补特征,或用于说话人自适应训练(SAT)。
除子空间的特征之外的另一种子空间方法,被称为:说话人编码,也是把特征用作增补[25]。
对于每个说话人,特定神经网络单元集合被链接到原始SI网络中,并进行优化。
基于i-Vector的SAT已经称为训练DNN声学模型时的小技巧,以提供较小但稳定的性能提升。
- 模型直接适应方法
一种直觉的想法是使用新的说话人数据来直接调整DNN参数。使用新数据来对SI模型进行重训练/调优是最简单的方式,又被称为重训练说话人无关(Retrained Speaker Independent,RSI)自适应。为避免过拟合,通常进行保守训练(Conservative Training),如KL散度(Kullback-Leibler Divergence)正则化[26]。通过把KL散度项添加到用于更新神经网络参数的原交叉熵代价函数中,该方法试图将适应后模型的后验分布接近于用于适应的源模型。虽然该方法十分有效,但是需要为每个说话人构建一个神经网络。
KLD正则化
L2正则化项使得自适应后模型参数与SI模型参数相接近。
对于声学模型训练,需要最小化交叉熵:
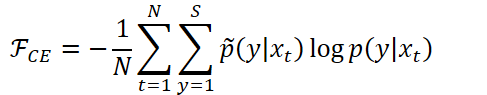

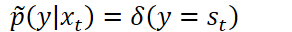

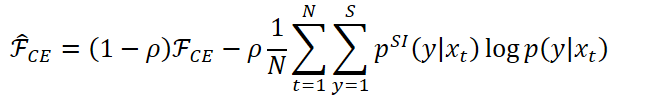
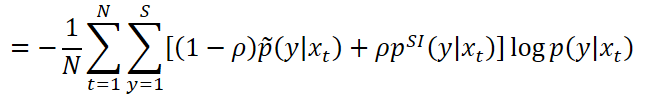
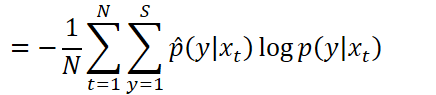
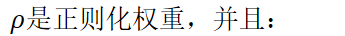


LHUC(学习性隐层单元贡献)
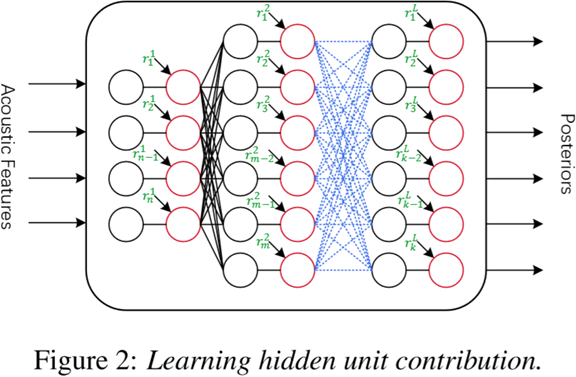

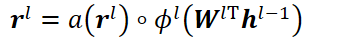

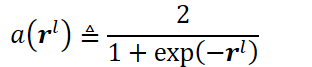
以限制r的元素取值为[0, 2]。

Previous studies on LHUC [22] have demonstrated that adapting more layers in the network can get continuously better accuracy. Hence we inserted LHUC parameters after each hidden layers.
实验
实验基于i-Vector与cMLLR(fMLLR)特征训练的SAT-DNN(TDNN-LSTM)声学模型。
[25] O. Abdel-Hamid and H. Jiang, "Fast speaker adaptation of hybrid nn/hmm model for speech recognition based on discriminative learning of speaker code," in Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on. IEEE, 2013, pp. 7942–7946.
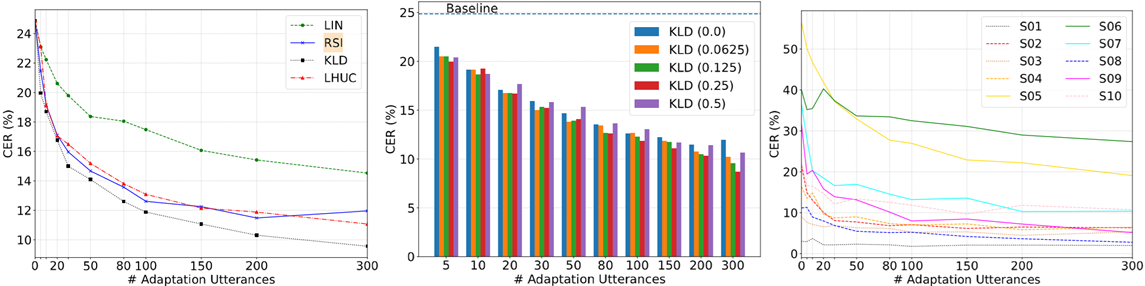
三种方法的组合:
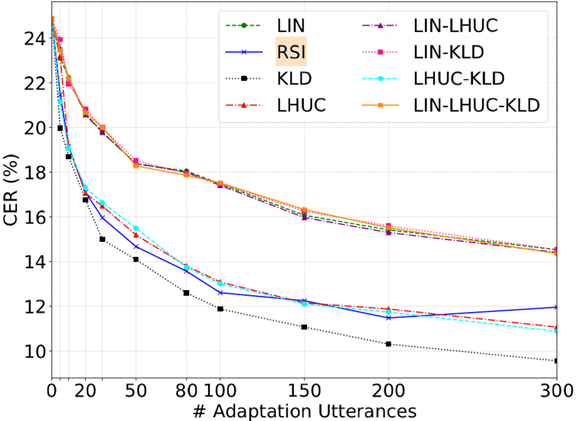
组合并不能带来性能提升。
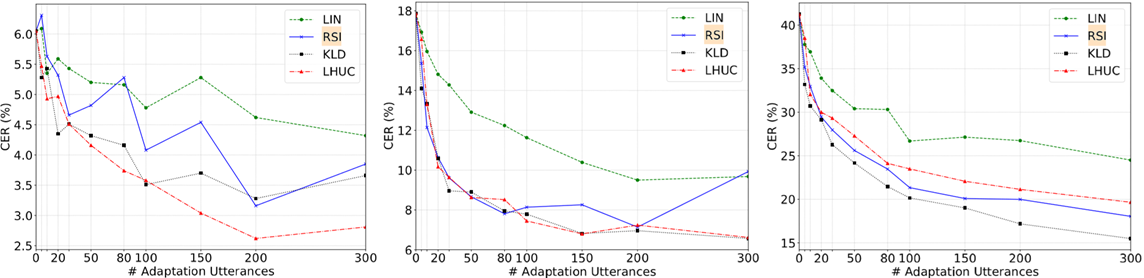
时,RSI就会出现偏差。
或10个话语)反而不如基线,本文实验表明即使使用少量数据也能带来不错的性能提升。我们认为,这是因为测试说话人口音很重,即SI数据与目标说话人数据之间的差异十分明显。
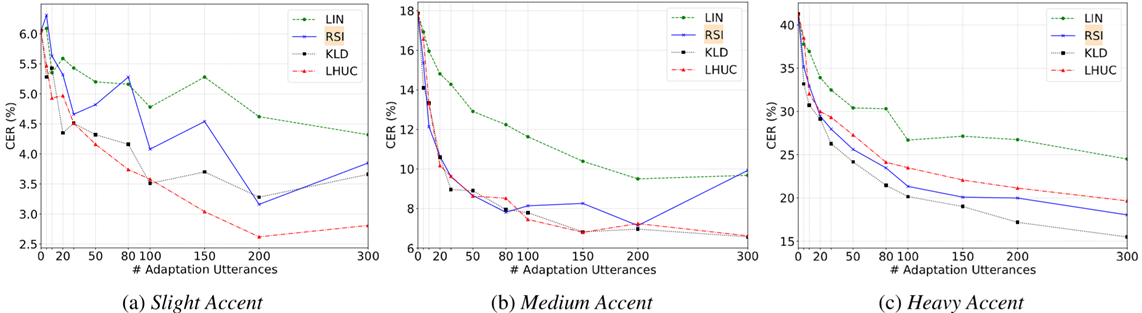
使用不同ρ值[0.0625,0.5]进行比较也表明,即使对于不同大小的适应数据,即使ρ较小,也可以获得合理的CER减少。对于大数据集和小数据据,中等权重(例如,0.25)最优;对于中等大小数据集,较小正则化权重(例如,0.0625)最优。我们还比较了不同口音说话人的性能。图3c的结果显示KLD适用于每个测试说话人,并且在SI模型中具有最高CER的说话人(即,S5,具有最重的口音)实现了最大的CER减少。但随着适应数据的增加,每个说话人的增益越来越小。
Empirical Evaluation of Speaker Adaptation on DNN based Acoustic Model的更多相关文章
- Utterance-Wise Recurrent Dropout And Iterative Speaker Adaptation For Robust Monaural Speech Recognition
单声道语音识别的逐句循环Dropout迭代说话人自适应 WRBN(wide residual BLSTM network,宽残差双向长短时记忆网络) [2] J. Heymann, L. Dr ...
- An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling 2018-0 ...
- Predicting effects of noncoding variants with deep learning–based sequence model | 基于深度学习的序列模型预测非编码区变异的影响
Predicting effects of noncoding variants with deep learning–based sequence model PDF Interpreting no ...
- 论文翻译:2020_Generative Adversarial Network based Acoustic Echo Cancellation
论文地址:http://www.interspeech2020.org/uploadfile/pdf/Thu-1-10-5.pdf 基于GAN的回声消除 摘要 生成对抗网络(GANs)已成为语音增强( ...
- 论文阅读笔记六十四: Architectures for deep neural network based acoustic models defined over windowed speech waveforms(INTERSPEECH 2015)
论文原址:https://pdfs.semanticscholar.org/eeb7/c037e6685923c76cafc0a14c5e4b00bcf475.pdf 摘要 本文研究了利用深度神经网络 ...
- What are the differences between an LES-SGS model and a RANS based turbulence model?
The biggest difference between LES and RANS is that, contrary to LES, RANS assumes that \(\overline{ ...
- pytorch --Rnn语言模型(LSTM,BiLSTM) -- 《Recurrent neural network based language model》
论文通过实现RNN来完成了文本分类. 论文地址:88888888 模型结构图: 原理自行参考论文,code and comment: # -*- coding: utf-8 -*- # @time : ...
- 论文翻译:2020_Acoustic Echo Cancellation Based on Recurrent Neural Network
论文地址:https://ieeexplore.ieee.org/abstract/document/9306224 基于RNN的回声消除 摘要 本文提出了一种基于深度学习的语音分离技术的回声消除方法 ...
- 机器学习进阶-目标追踪-SSD多进程执行 1.cv2.dnn.readnetFromCaffe(用于读取已经训练好的caffe模型) 2.delib.correlation_tracker(生成追踪器) 5.cv2.writer(将图片写入视频中) 6.cv2.dnn.blobFromImage(图片归一化) 10.multiprocessing.process(生成进程)
1. cv2.dnn.readNetFromCaffe(prototxt, model) 用于进行SSD网络的caffe框架的加载 参数说明:prototxt表示caffe网络的结构文本,model ...
随机推荐
- OpenLayers学习笔记(四)— QML显示html中openlayers地图的坐标
GitHub:八至 作者:狐狸家的鱼 本文链接:实现QML中显示html中地图的坐标 如何QML与HTML通信已经在这篇文章 QML与HTML通信之画图 详细讲述了 1.HTML var coord; ...
- 【洛谷P2257】YY的GCD
题目大意:有 \(T\) 个询问,每个询问给定 \(N, M\),求 \(1\le x\le N, 1\le y\le M\) 且 \(gcd(x, y)\) 为质数的 \((x, y)\) 有多少对 ...
- 用标准C编写COM dll
参考资料: 用标准C编写COM(一)COM in plain C,Part1 (http://blog.csdn.net/wangqiulin123456/article/details/809235 ...
- vue层级关系的数据管理
项目背景:为一些有层级关系的数据管理做一套后台管理系统,例如一个小区,里面是有许多楼,楼里有许多层,每一层有许多不同的房······,现在就是要实现对这些数据进行增删改查操作. 1.Tree(树形组件 ...
- JS怎么判断一个对象是否为空
昨天面试的时候被问到的问题.只怪自己根基不牢,没有回答好 甚至说出了“判断这个obj是否和{}相等”这样鱼蠢的答案(/(ㄒoㄒ)/~~)引用类型怎么可以直接判断==或者===呢?! 今天中秋佳节,宝宝 ...
- 牛客网 2018年东北农业大学春季校赛 I题 wyh的物品
链接:https://www.nowcoder.com/acm/contest/93/I 来源:牛客网 时间限制:C/C++ 5秒,其他语言10秒空间限制:C/C++ 262144K,其他语言5242 ...
- gradle 的jar下载到哪里了
很好奇 gradle 的jar下载到哪里了,好顿翻,原来在C:\Users\(你的用户名)\.gradle\caches\modules-2\files-2.1目录下,使用gradle引用lib会先查 ...
- maomao的每日动向
\(2019.02.04\) \(Nothing\) \(to\) \(do\). \(2019.02.05\) - 早上睡到\(12\)点 - 中午下午:吃饭串门拜年 - 晚上:吹爆<流浪地球 ...
- 解决openoffice进程异常退出的办法
步骤1 编写脚本 openoffice.sh #!/usr/bin/bash OPENOFFICEPID=`ps -ef|grep "/opt/openoffice4/program/sof ...
- 1053. Path of Equal Weight (30)
Given a non-empty tree with root R, and with weight Wi assigned to each tree node Ti. The weight of ...