Scrapy简单入门及实例讲解
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下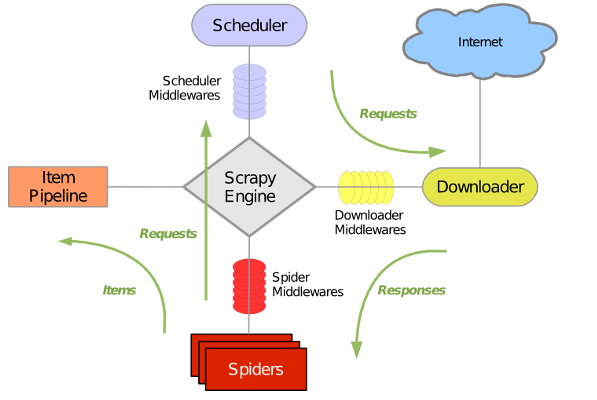
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
一、安装
1、安装wheel
pip install wheel
2、安装lxml
https://pypi.python.org/pypi/lxml/4.1.0
3、安装pyopenssl
https://pypi.python.org/pypi/pyOpenSSL/17.5.0
4、安装Twisted
https://www.lfd.uci.edu/~gohlke/pythonlibs/
5、安装pywin32
https://sourceforge.net/projects/pywin32/files/
6、安装scrapy
pip install scrapy
注:windows平台需要依赖pywin32,请根据自己系统32/64位选择下载安装,https://sourceforge.net/projects/pywin32/
二、爬虫举例
入门篇:美剧天堂前100最新(http://www.meijutt.com/new100.html)
1、创建工程
scrapy startproject movie
2、创建爬虫程序
cd movie
scrapy genspider meiju meijutt.com
3、自动创建目录及文件
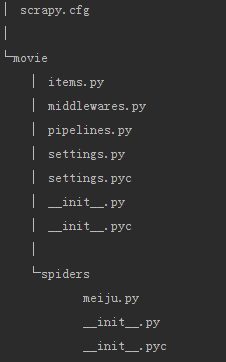
4、文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
5、设置数据存储模板
items.py
import scrapy class MovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
6、编写爬虫
meiju.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# -*- coding: utf-8 -*-
import scrapy
from movie.items import MovieItem class MeijuSpider(scrapy.Spider):
name = "meiju"
allowed_domains = ["meijutt.com"]
start_urls = ['http://www.meijutt.com/new100.html'] def parse(self, response):
movies = response.xpath('//ul[@class="top-list fn-clear"]/li')
for each_movie in movies:
item = MovieItem()
item['name'] = each_movie.xpath('./h5/a/@title').extract()[0]
yield item
7、设置配置文件
settings.py增加如下内容
ITEM_PIPELINES = {'movie.pipelines.MoviePipeline':100}
8、编写数据处理脚本
pipelines.py
class MoviePipeline(object):
def process_item(self, item, spider):
with open("my_meiju.txt",'a') as fp:
fp.write(item['name'].encode("utf8") + '\n')
9、执行爬虫
cd movie
scrapy crawl meiju --nolog
10、结果

Scrapy简单入门及实例讲解的更多相关文章
- [转]Scrapy简单入门及实例讲解
Scrapy简单入门及实例讲解 中文文档: http://scrapy-chs.readthedocs.io/zh_CN/0.24/ Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用 ...
- Scrapy简单入门及实例讲解-转载
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- 10,Scrapy简单入门及实例讲解
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- TCP入门与实例讲解
内容简介 TCP是TCP/IP协议栈的核心组成之一,对开发者来说,学习.掌握TCP非常重要. 本文主要内容包括:什么是TCP,为什么要学习TCP,TCP协议格式,通过实例讲解TCP的生命周期(建立连接 ...
- 【智能算法】粒子群算法(Particle Swarm Optimization)超详细解析+入门代码实例讲解
喜欢的话可以扫码关注我们的公众号哦,更多精彩尽在微信公众号[程序猿声] 01 算法起源 粒子群优化算法(PSO)是一种进化计算技术(evolutionary computation),1995 年由E ...
- Nodejs进阶:核心模块net入门与实例讲解
模块概览 net模块是同样是nodejs的核心模块.在http模块概览里提到,http.Server继承了net.Server,此外,http客户端与http服务端的通信均依赖于socket(net. ...
- scrapy简单入门及选择器(xpath\css)
简介 scrapy被认为是比较简单的爬虫框架,资料比较齐全,网上也有很多教程.官网上介绍了它的四种安装方法,PyPI.Conda.APT.Source,我们只介绍最简单的安装方法. 安装 Window ...
- PHP中“简单工厂模式”实例讲解
原创文章,转载请注明出处:http://www.cnblogs.com/hongfei/archive/2012/07/07/2580776.html 简单工厂模式:①抽象基类:类中定义抽象一些方法, ...
- wxPython中文教程 简单入门加实例
wx.Window 是一个基类,许多构件从它继承.包括 wx.Frame 构件.技术上这意味着,我们可以在所有的 子类中使用 wx.Window 的方法.我们这里介绍它的几种方法: * SetTitl ...
随机推荐
- Tree Traversals Again
An inorder binary tree traversal can be implemented in a non-recursive way with a stack. For example ...
- 数据库-Oracle的使用
数据库的作用不言而喻,Oracle 作为一个主流的数据库,了解更是需要的 安装好oracle之后,登录初始账号,一般而言呢,我就新建一个用户, --创建新用户,用户名为JohnWu ,密码为 root ...
- Excel 2016 密码保护破解
Excel 2016的密码保护可以区分为几个: 文件密码保护(Excel中叫做工作簿保护) 文件打开权限密码 文件修改权限密码 工作表保护 关于各个保护密码的设置方式请查阅其他资料,我的情况是之前自己 ...
- day2.jmeter简单压测,下载文件,Charles手机抓包准备
一.压测 压测衡量一个系统的好坏:1.tps每秒钟处理的事物数,2.qps响应时间 添加聚合报告,更改线程组,运行接口请求 **添加压力机 1.首先确保都在同一网段 2.其他电脑要先启动jmeter- ...
- 转:APP开发浅谈-Fiddler抓包详解
原文地址:http://www.luoxudong.com/?p=306 Fiddler抓包工具在APP开发过程中使用非常频繁,对开发者理解HTTP网络传输原理以及分析定位网络方面的问题非常有帮助.今 ...
- 对python的一些拙见
对于python,总的来说有点机缘巧合的识得了它.当我录取专业是计算机的时候,身边的一些人向我介绍了这个解释型脚本语言吧.大一自学了一部分,刚好听的网课是嵩天老师的课,这学期迫不及待地拉着舍友选了这个 ...
- 数据传输流程和socket简单操作
一.***C/S架构:客户端(client)/服务端(server)架构, B/S架构:浏览器(browser) / 服务端(server)架构 软件cs架构:浏览器,qq,微信,陌陌等等硬件cs架构 ...
- Oracle 生成Guid;Oracle 生成多个Guid;Oracle 生成带''-"的Guid
Oracle 生成Guid select sys_guid() from dual Oracle 生成多个Guid Oracle 生成带''-"的Guid , ) , ) || '-' || ...
- 63.1拓展之box-shadow属性
效果地址:https://scrimba.com/c/cQpyKbUp 效果图: HTML code: <div class="loader"></div> ...
- Open SuSE 设置开关机时自动执行脚本
在open SuSE中,有两个文件是用于存放开机自动执行命令的.这两个文件分别是: /etc/init.d/before.local /etc/init.d/after.local /etc/init ...