Python基于dtw实现股票预测【多线程】
# -*- coding: utf-8 -*-
"""
Created on Tue Dec 4 08:53:08 2018 @author: zhen
"""
from dtw import fastdtw
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import threading
import time
from datetime import datetime def normalization(x): # np.std:计算矩阵的标准差(方差的算术平方根)
return (x - np.mean(x)) / np.std(x) def corrcoef(a,b):
corrc = np.corrcoef(a,b) # 计算皮尔逊相关系数,用于度量两个变量之间的相关性,其值介于-1到1之间
corrc = corrc[0,1]
return (16 * ((1 - corrc) / (1 + corrc)) ** 1) # ** 表示乘方 print("begin Main Thread")
startTimeStamp = datetime.now() # 获取当前时间
# 加载数据
filename = 'C:/Users/zhen/.spyder-py3/sh000300_2017.csv'
# 获取第一,二列的数据
all_date = pd.read_csv(filename,usecols=[0, 1], dtype = 'str')
all_date = np.array(all_date)
data = all_date[:, 0]
times = all_date[:, 1] data_points = pd.read_csv(filename,usecols=[3])
data_points = np.array(data_points)
data_points = data_points[:,0] #数据 topk = 10 #只显示top-10
baselen = 100 # 假设在50到150之间变化
basebegin = 361
basedata = data[basebegin]+' '+times[basebegin]+'~'+data[basebegin+baselen-1]+' '+times[basebegin+baselen-1]
length = len(data_points) #数据长度 # 定义自定义线程类
class Thread_Local(threading.Thread):
def __init__(self, thread_id, name, counter):
threading.Thread.__init__(self)
self.thread_id = thread_id
self.name = name
self.counter = counter
self.__running = threading.Event() # 标识停止线程
self.__running.set() # 设置为True def run(self):
print("starting %s" % self.name)
split_data(self, self.counter) # 执行代码逻辑 def stop(self):
self.__running.clear() # 分割片段并执行匹配,多线程
def split_data(self, split_len):
base = data_points[basebegin:basebegin+baselen] # 获取初始要匹配的数据
subseries = []
dateseries = []
for j in range(0, length):
if (j < (basebegin - split_len) or j > (basebegin + split_len - 1)) and j <length - split_len:
subseries.append(data_points[j:j+split_len])
dateseries.append(j) #开始位置
search(self, subseries, base, dateseries) # 调用模式匹配 # 定义结果变量
result = []
base_list = []
date_list = []
def search(self, subseries, base, dateseries):
# 片段搜索
listdistance = []
for i in range(0, len(subseries)):
tt = np.array(subseries[i])
dist, cost, acc, path = fastdtw(base, tt, dist='euclidean')
listdistance.append(dist)
# distance = corrcoef(base, tt)
# listdistance.append(distance)
# 排序
index = np.argsort(listdistance, kind='quicksort') #排序,返回排序后的索引序列
result.append(subseries[index[0]])
print("result length is %d" % len(result))
base_list.append(base)
date_list.append(dateseries[index[0]])
# 关闭线程
self.stop() # 变换数据(收缩或扩展),生成50到150之间的数据,间隔为10
loc = 0
for split_len in range(round(0.5 * baselen), round(1.5 * baselen), 10):
# 执行匹配
thread = Thread_Local(1, "Thread" + str(loc), split_len)
loc += 1
# 开启线程
thread.start() boo = 1 while(boo > 0):
if(len(result) < 10):
if(boo % 100 == 0):
print("has running %d s" % boo)
boo += 1
time.sleep(1)
else:
boo = 0 # 片段搜索
listdistance = []
for i in range(0, len(result)):
tt = np.array(result[i])
dist, cost, acc, path = fastdtw(base_list[i], tt, dist='euclidean')
# distance = corrcoef(base_list[i], tt)
listdistance.append(dist)
# 最终排序
index = np.argsort(listdistance, kind='quicksort') #排序,返回排序后的索引序列
print("closed Main Thread")
endTimeStamp = datetime.now()
# 结果集对比
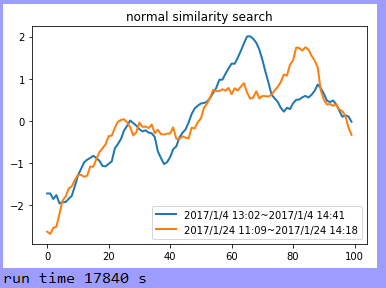
plt.figure(0)
plt.plot(normalization(base_list[index[0]]),label= basedata,linewidth='')
length = len(result[index[0]])
begin = data[date_list[index[0]]] + ' ' + times[date_list[index[0]]]
end = data[date_list[index[0]] + length - 1] + ' ' + times[date_list[index[0]] + length - 1]
label = begin + '~' + end
plt.plot(normalization(result[index[0]]), label=label, linewidth='')
plt.legend(loc='lower right')
plt.title('normal similarity search')
plt.show()
print('run time', (endTimeStamp-startTimeStamp).seconds, "s")
结果:
has running 100 s
has running 200 s
has running 300 s
has running 400 s
has running 500 s
has running 600 s
has running 700 s
has running 800 s
has running 900 s
has running 1000 s
has running 1100 s
has running 1200 s
has running 1300 s
has running 1400 s
has running 1500 s
has running 1600 s
has running 1700 s
has running 1800 s
has running 1900 s
has running 2000 s
has running 2100 s
has running 2200 s
has running 2300 s
has running 2400 s
has running 2500 s
has running 2600 s
has running 2700 s
has running 2800 s
has running 2900 s
has running 3000 s
has running 3100 s
has running 3200 s
has running 3300 s
has running 3400 s
has running 3500 s
has running 3600 s
has running 3700 s
has running 3800 s
has running 3900 s
has running 4000 s
has running 4100 s
has running 4200 s
has running 4300 s
has running 4400 s
has running 4500 s
has running 4600 s
has running 4700 s
has running 4800 s
has running 4900 s
has running 5000 s
has running 5100 s
has running 5200 s
has running 5300 s
has running 5400 s
has running 5500 s
has running 5600 s
has running 5700 s
has running 5800 s
has running 5900 s
has running 6000 s
has running 6100 s
has running 6200 s
has running 6300 s
has running 6400 s
has running 6500 s
has running 6600 s
has running 6700 s
has running 6800 s
has running 6900 s
has running 7000 s
has running 7100 s
has running 7200 s
has running 7300 s
has running 7400 s
has running 7500 s
has running 7600 s
has running 7700 s
has running 7800 s
has running 7900 s
has running 8000 s
has running 8100 s
has running 8200 s
has running 8300 s
has running 8400 s
has running 8500 s
has running 8600 s
has running 8700 s
has running 8800 s
has running 8900 s
has running 9000 s
has running 9100 s
has running 9200 s
has running 9300 s
has running 9400 s
has running 9500 s
has running 9600 s
has running 9700 s
has running 9800 s
has running 9900 s
has running 10000 s
has running 10100 s
has running 10200 s
has running 10300 s
has running 10400 s
has running 10500 s
has running 10600 s
has running 10700 s
has running 10800 s
has running 10900 s
has running 11000 s
has running 11100 s
has running 11200 s
has running 11300 s
has running 11400 s
has running 11500 s
has running 11600 s
has running 11700 s
has running 11800 s
has running 11900 s
has running 12000 s
has running 12100 s
has running 12200 s
has running 12300 s
has running 12400 s
has running 12500 s
has running 12600 s
has running 12700 s
has running 12800 s
has running 12900 s
has running 13000 s
has running 13100 s
has running 13200 s
has running 13300 s
has running 13400 s
has running 13500 s
has running 13600 s
has running 13700 s
has running 13800 s
has running 13900 s
has running 14000 s
has running 14100 s
has running 14200 s
has running 14300 s
has running 14400 s
result length is 1
result length is 2
has running 14500 s
has running 14600 s
has running 14700 s
has running 14800 s
result length is 3
has running 14900 s
has running 15000 s
result length is 4
has running 15100 s
has running 15200 s
has running 15300 s
has running 15400 s
result length is 5
has running 15500 s
has running 15600 s
has running 15700 s
has running 15800 s
has running 15900 s
has running 16000 s
has running 16100 s
has running 16200 s
result length is 6
has running 16300 s
has running 16400 s
has running 16500 s
has running 16600 s
result length is 7
result length is 8
has running 16700 s
result length is 9
result length is 10
closed Main Thread
Python基于dtw实现股票预测【多线程】的更多相关文章
- 深度学习RNN实现股票预测实战(附数据、代码)
背景知识 最近再看一些量化交易相关的材料,偶然在网上看到了一个关于用RNN实现股票预测的文章,出于好奇心把文章中介绍的代码在本地跑了一遍,发现可以work.于是就花了两个晚上的时间学习了下代码,顺便把 ...
- python基于LeanCloud的短信验证
python基于LeanCloud的短信验证 1. 获取LeanCloud的Id.Key 2. 安装Flask框架和Requests库 pip install flask pip install re ...
- Python:使用threading模块实现多线程编程
转:http://blog.csdn.net/bravezhe/article/details/8585437 Python:使用threading模块实现多线程编程一[综述] Python这门解释性 ...
- Python基于共现提取《釜山行》人物关系
Python基于共现提取<釜山行>人物关系 一.课程介绍 1. 内容简介 <釜山行>是一部丧尸灾难片,其人物少.关系简单,非常适合我们学习文本处理.这个项目将介绍共现在关系中的 ...
- Python 基于Python实现的ssh兼sftp客户端(上)
基于Python实现的ssh兼sftp客户端 by:授客 QQ:1033553122 实现功能 实现ssh客户端兼ftp客户端:实现远程连接,执行linux命令,上传下载文件 测试环境 Win7 ...
- 基于Echarts的股票K线图展示
发布时间:2018-10-31 技术:javascript+html5+canvas 概述 基于echarts的股票K线图展示,只需引用单个插件,通过简单配置,导入数据,即可实现炫酷复杂的K线 ...
- 百万年薪python之路 -- 并发编程之 多线程 二
1. 死锁现象与递归锁 进程也有死锁与递归锁,进程的死锁和递归锁与线程的死锁递归锁同理. 所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因为争夺资源而造成的一种互相等待的现象,在无外力的作用 ...
- Python基于socket模块实现UDP通信功能示例
Python基于socket模块实现UDP通信功能示例 本文实例讲述了Python基于socket模块实现UDP通信功能.分享给大家供大家参考,具体如下: 一 代码 1.接收端 import ...
- Python基于正则表达式实现文件内容替换的方法
Python基于正则表达式实现文件内容替换的方法 本文实例讲述了Python基于正则表达式实现文件内容替换的方法.分享给大家供大家参考,具体如下: 最近因为有一个项目需要从普通的服务器移植到SAE,而 ...
随机推荐
- Spring boot @EnableScheduling 和 @Scheduled 注解使用例子
前言 Spring Boot提供了@EnableScheduling和@Scheduled注解,用于支持定时任务的执行,那么接下来就让我们学习下如何使用吧: 假设我们需要每隔10秒执行一个任务,那么我 ...
- 字体反爬--css+svg反爬
这个验证码很恶心,手速非常快才能通过.. 地址:http://www.dianping.com/shop/9964442 检查一下看到好多字没有了,替代的是<x class="xxx& ...
- leetcode — spiral-matrix-ii
import java.util.ArrayList; import java.util.Arrays; import java.util.List; /** * Source : https://o ...
- [CF286E] Ladies' shop
Description 给出 \(n\) 个 \(\leq m\) 且不同的数 \(a_1,\dots,a_n\),现在要求从这 \(n\) 个数中选出最少的数字,满足这 \(n\) 个数字都可以由选 ...
- Perl的列表和数组
列表和数组 列表 使用括号包围的元素,括号中的元素使用逗号隔开的是列表. 列表中的元素可以是字符串.数值.undef或它们的混合. 列表中的字符串元素需要使用引号包围. 空列表是括号中什么都没有的列表 ...
- Logback中如何自定义灵活的日志过滤规则
当我们需要对日志的打印要做一些范围的控制的时候,通常都是通过为各个Appender设置不同的Filter配置来实现.在Logback中自带了两个过滤器实现:ch.qos.logback.classic ...
- 反爬虫——使用chrome headless时一些需要注意的细节
以前我们介绍过chrome headless的用法(https://www.cnblogs.com/apocelipes/p/9264673.html). 今天我们要稍微提一下其中一个细节. 反爬和w ...
- 一个word文档中,多个表格的批量调整(根据窗口调整表格和添加表格水平线)
Sub 自动调整所有表格() ' ' 自动调整所有表格 宏 ' 'Application.Browser.Target = wdBrowseTable For i = 1 To ActiveDocum ...
- Asp.net连接数据库的配置方法
1.Sqlserver数据库连接 <connectionStrings> <add name="Conn" connectionString="serv ...
- Android Studio 活动的生命周期
Activity 类中定义了7个回调方法,覆盖了活动的活动周期的每一环节 onCreate() 活动第一次创建的时候调用 onStart() 这个活动由不可见变为可见的时候调用 onResume() ...