基于pandas的数据清洗 -- 缺失值(空值)的清洗
开发环境
- anaconda
- 集成环境:集成好了数据分析和机器学习中所需要的全部环境
- 安装目录不可以有中文和特殊符号
- jupyter
- anaconda提供的一个基于浏览器的可视化开发工具
丢失数据的类型
- 原始数据中会存在两种缺失值(空值)
- None
- np.nan(NaN)
两种丢失数据的区别
import pandas as pd
from pandas import DataFrame
import numpy as np
type(None)
NoneType
type(np.nan)
float
为什么在数据分析中需要用到的是浮点类型的空而不是对象类型?
- 数据分析中会常常使用某些形式的运算来处理原始数据,如果原数数据中的空值为NAN的形式,则不会干扰或者中断运算。
- NAN可以参与运算的
- None是不可以参与运算
np.nan + 1
nan
None + 1
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-5-3fd8740bf8ab> in <module>
----> 1 None + 1
TypeError: unsupported operand type(s) for +: 'NoneType' and 'int'
在pandas中如果遇到了None形式的空值则pandas会将其强转成NAN的形式。
df = DataFrame(data=np.random.randint(0,100,size=(7,5)))
df.iloc[2,3] = None
df.iloc[4,2] = np.nan
df.iloc[5,4] = None
df
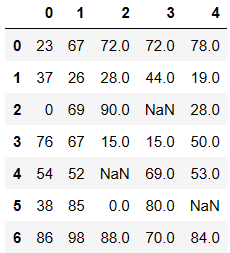
pandas处理空值操作
- isnull
- notnull
- any
- all
- dropna
- fillna
方式1:对空值进行过滤(删除空所在的行数据)
- isnull --> any
- notnull --> all
df.isnull()
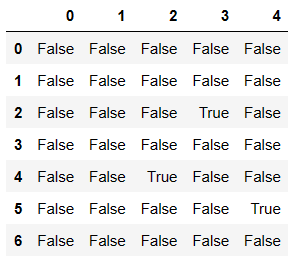
# 哪些行中有空值
# any(axis=1)检测哪些行中存有空值
df.isnull().any(axis=1) # any会作用isnull返回结果的每一行
# true对应的行就是存在缺失数据的行
0 False
1 False
2 True
3 False
4 True
5 True
6 False
dtype: bool
df.notnull()
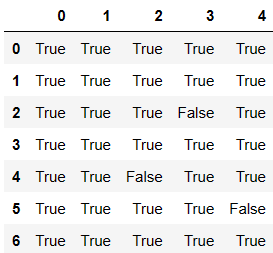
df.notnull().all(axis=1)
0 True
1 True
2 False
3 True
4 False
5 False
6 True
dtype: bool
# 将布尔值作为源数据的行索引
df.loc[df.notnull().all(axis=1)]
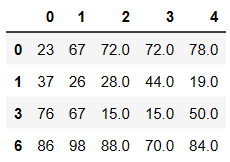
# 获取空对应的行数据
df.loc[df.isnull().any(axis=1)]
# 获取空对应行数据的行索引
indexs = df.loc[df.isnull().any(axis=1)].index
indexs
Int64Index([2, 4, 5], dtype='int64')
df.drop(labels=indexs,axis=0)
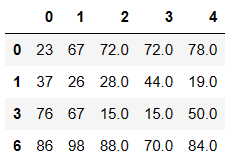
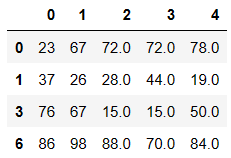
方式2:dropna 直接将缺失的行或者列进行删除
df.dropna(axis=0)
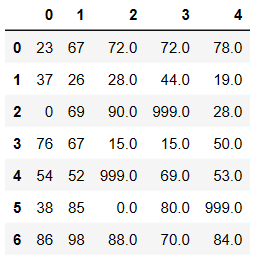
# 对缺失值进行覆盖 fillna
df.fillna(value=999) # 使用指定值将源数据中所有的空值进行填充
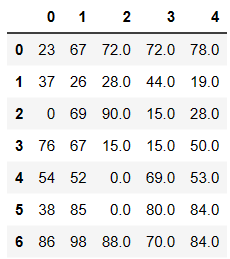
# 使用空的近邻值进行填充
# method=ffill向前填充,bfill向后填充
df.fillna(axis=0,method='bfill')
dropna和fillna的选用
- 什么时候用dropna什么时候用fillna?
- 尽量使用dropna
- 如果删除成本比较高,则使用fillna
方式3:使用空值对应列的均值进行空值填充
for col in df.columns:
# 检测哪些列中存有空值
if df[col].isnull().sum() > 0: # 说明df[col]中存有空值
mean_value = df[col].mean()
df[col] = df[col].fillna(value=mean_value)
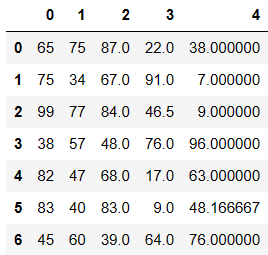
df
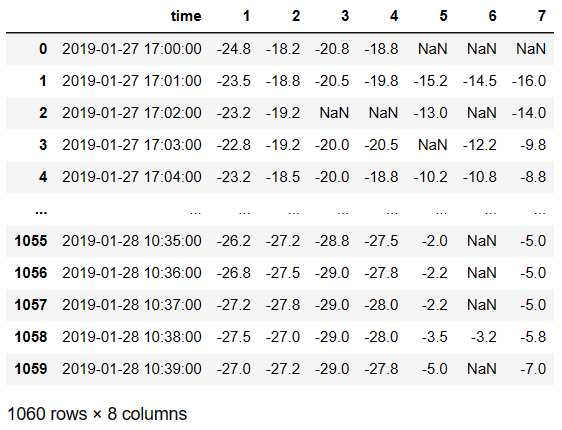
面试题
- 数据说明:
- 数据是1个冷库的温度数据,1-7对应7个温度采集设备,1分钟采集一次。
- 数据处理目标:
- 用1-4对应的4个必须设备,通过建立冷库的温度场关系模型,预估出5-7对应的数据。
- 最后每个冷库中仅需放置4个设备,取代放置7个设备。
- f(1-4) --> y(5-7)
- 数据处理过程:
- 1、原始数据中有丢帧现象,需要做预处理;
- 2、matplotlib 绘图;
- 3、建立逻辑回归模型。
- 无标准答案,按个人理解操作即可。
- 测试数据为testData.xlsx
data = pd.read_excel('./data/testData.xlsx').drop(labels=['none','none1'],axis=1)
data
data.shape
(1060, 8)
# 删除空对应的行数据
data.dropna(axis=0).shape
(927, 8)
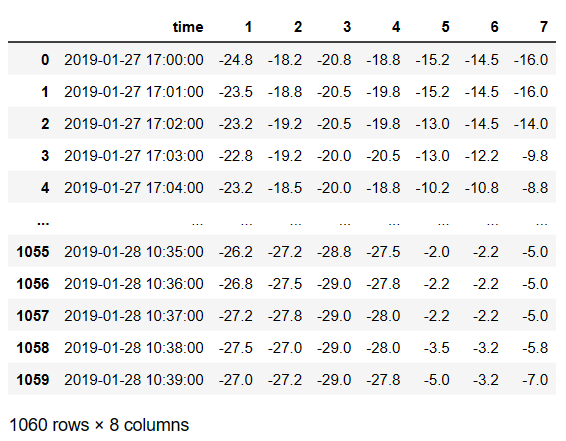
# 填充
data.fillna(method='ffill',axis=0).fillna(method='bfill',axis=0)
基于pandas的数据清洗 -- 缺失值(空值)的清洗的更多相关文章
- 数据分析03 /基于pandas的数据清洗、级联、合并
数据分析03 /基于pandas的数据清洗.级联.合并 目录 数据分析03 /基于pandas的数据清洗.级联.合并 1. 处理丢失的数据 2. pandas处理空值操作 3. 数据清洗案例 4. 处 ...
- pandas 之 数据清洗-缺失值
Abstract During the course fo doing data analysis and modeling, a significant amount of time is spen ...
- 【转载】使用pandas进行数据清洗
使用pandas进行数据清洗 本文转载自:蓝鲸的网站分析笔记 原文链接:使用python进行数据清洗 目录: 数据表中的重复值 duplicated() drop_duplicated() 数据表中的 ...
- 基于pandas python的美团某商家的评论销售数据分析(可视化)
基于pandas python的美团某商家的评论销售数据分析 第一篇 数据初步的统计 本文是该可视化系列的第二篇 第三篇 数据中的评论数据用于自然语言处理 导入相关库 from pyecharts i ...
- 用pandas进行数据清洗(二)(Data Analysis Pandas Data Munging/Wrangling)
在<用pandas进行数据清洗(一)(Data Analysis Pandas Data Munging/Wrangling)>中,我们介绍了数据清洗经常用到的一些pandas命令. 接下 ...
- python – 基于pandas中的列中的值从DataFrame中选择行
如何从基于pandas中某些列的值的DataFrame中选择行?在SQL中我将使用: select * from table where colume_name = some_value. 我试图看看 ...
- 数据分析04 /基于pandas的DateFrame进行股票分析、双均线策略制定
数据分析04 /基于pandas的DateFrame进行股票分析.双均线策略制定 目录 数据分析04 /基于pandas的DateFrame进行股票分析.双均线策略制定 需求1:对茅台股票分析 需求2 ...
- 使用pandas进行数据清洗
本文转载自:蓝鲸的网站分析笔记 原文链接:使用python进行数据清洗 目录: 数据表中的重复值 duplicated() drop_duplicated() 数据表中的空值/缺失值 isnull() ...
- 基于pandas python的美团某商家的评论销售(数据分析)
数据初步的分析 本文是该系列的第一篇 数据清洗 数据初步的统计 第二篇 数据可视化 第三篇 数据中的评论数据用于自然语言处理 from pyecharts import Bar,Pie import ...
- 数据分析---用pandas进行数据清洗(Data Analysis Pandas Data Munging/Wrangling)
这里利用ben的项目(https://github.com/ben519/DataWrangling/blob/master/Python/README.md),在此基础上增添了一些内容,来演示数据清 ...
随机推荐
- SpringBoot进阶教程(八十四)spring-retry
在日常的一些场景中, 很多需要进行重试的操作.而spring-retry是spring提供的一个基于spring的重试框架,某些场景需要对一些异常情况下的方法进行重试就会用到spring-retry. ...
- .NET 响应式编程 System.Reactive 系列文章(三):Subscribe 和 IDisposable 的深入理解
.NET 响应式编程 System.Reactive 系列文章(三):Subscribe 和 IDisposable 的深入理解 引言:为什么理解 Subscribe 和 IDisposable 很重 ...
- Solution -「牛客 31454H」Permutation on Tree
\(\mathscr{Description}\) Link. 给定一棵含有 \(n\) 个点的有根外向树, 对于所有满足树形拓扑关系的结点遍历顺序 \(p_{1..n}\) 求出 \(\su ...
- 推荐4款基于.NET开源、功能强大的CMS建站系统
前言 CMS系统作为一种强大的内容管理工具,在数字化时代发挥着越来越重要的作用.无论是个人博客还是大型企业官网,选择一个合适的CMS都能极大地提高效率和用户体验.今天大姚给大家推荐4款基于.NET开源 ...
- WPF刮刮乐
WPF刮刮乐 <Window x:Class="WpfApp2.MainWindow" xmlns="http://schemas.microsoft.com/wi ...
- C# 获取系统声卡音频数据,并绘制波形
//by wgscd //date:2022/11/7 UI: <Path Stroke="Red" Data="{Binding path}" Rend ...
- XXL-JOB原理--定时任务框架简介
一.完整介绍地址:官方介绍 https://www.xuxueli.com/xxl-job/#/?id=%E4%B8%80%E3%80%81%E7%AE%80%E4%BB%8B 二.最新版本架构图: ...
- 2020年最新Redis面试题-copy
什么是Redis Redis(Remote Dictionary Server) 是一个使用 C 语言编写的,开源的(BSD许可)高性能非关系型(NoSQL)的键值对数据库. Redis 可以存储键和 ...
- STM32IO口模拟IIC时序
正点原子IIC讲解:https://www.bilibili.com/video/BV1o8411n7o9/?spm_id_from=333.337.search-card.all.click& ...
- react报错Can't resolve 'react' in 'E:\reactweb\preact\my-app\node_modules\react-dom\cjs'
执行如下: npm install -g react npm install react --save 类似这种依赖项(react,react-dom 等)报错,哪个报错执行哪个即可 执行上述两句就 ...