SciTech-BigDataAIML-LLM-Transformer Series-$\large Supervised\ Statistical\ Model$监督学习的统计模型+$\large Transformer+Self Attention$的核心原理及实现
SciTech-BigDataAIML-LLM-Transformer Series>

\(\large Supervised\ Statistical\ Model\):
\(\large Transformer+Self Attention\)
\(\large Supervised\ Model\): Supervised by \(\large Training\ Data\).
\(\large Statistical\ Model\): mainly using Probability+Statistics methods.
both \(\large Transformer\) and \(\large Self Attention\) are $ Supervised\ Statistical\ Model $
分“训练(学习)阶段”和“预测(应用)阶段”:
训练阶段: 在 "大量训练数据" 上 "学习总结事实规律"(确定模型参数),
主流用统计概率分析方法.
例如: \(\large Self Attention\) 训练时确定最好的模型参数\(\large W^q,\ W^k, W^v\).预测阶段: 可重复使用的应用"预先总结的(训练数据的)事实规律"进行快捷高效的预测.
例如: \(\large Self Attention\) 预测时,直接用训练好的 \(\large W^q,\ W^k, W^v\) 高效预测 .
\(\large Transformer\) 及 \(\large Self Attention\) 都是 \(\large Supervised\ Statistical\ Model\)
是对"大量预训练数据", 用"统计概率分析等方法", 学习总结"事实规律"(确定模型参数),
以能可重复使用的应用"预先总结的事实规律"进行快捷高效的预测的模型.\(\large Self Attention\)预测时的"乱序计算出稳定" \(\large Attention\ Score\ Vector\) "能力
- \(\large Self Attention\)预测用 \(\large Parameter\) 是"稳定不变"预先训练好存在模型的.
即: 计算Word Sequence任意两个"Word"的\(\large Attention\ Score\)时, 用的 \(\large W^q,\ W^k, W^v\) 是稳定不变的训练好的模型参数. - 任意乱序计算稳定的" \(\large Attention\ Score\ Vector\) " 能力:
"Word Sequence"任意重排, 得到同一 \(\large Attention\ Score\ Vector\)(如果不嵌入 \(\large PE位置信息\)).
- \(\large Self Attention\)预测用 \(\large Parameter\) 是"稳定不变"预先训练好存在模型的.
\(\large Transformer\)的核心原理:
是组合使用多种"数学驱动"的先进技术:- \(\large Self Attention\),
- \(\large PE(Positional\ Encoding)\),
- \(\large WE(Word\ Embedding)\).
实现以下多种优点:
- 解耦"Long Sequence"(长序列)的"强顺序依赖(Word的前后位置)",
- 可并行计算 \(\large Attention\ Score\ Vector\),
- 可伸缩性\(\large Scalability\).
\(\large Mathmatical\ Definition\)
\(\ of\ the\ Self Attention\)
Given \(\text{ a sequence of input tokens }\):
\]
, its \(Self-Attention\) outputs $\text {a sequence of the same length} \(:
\) Y_1,\ Y_2, \cdots ,\ Y_n$, where:
\ Y_i \in R^d,\ 1 \leq d \leq n, d is the dimension number of each input token $$
, where
(11.6.1)
according to the definition of attention pooling in (11.1.1). Using multi-head attention, the following code snippet computes the self-attention of a tensor with shape (batch size, number of time steps or sequence length in tokens,
). The output tensor has the same shape.
\(\large Self-Attention\) 的优点 与缺点
\(\large Self-Attention\) 的缺点:
- 小模型时, 开销较大。
- Word之间没有"顺序关系":
打乱一句Word Seq.后, \(\large Self-Attention\)仍是计算每两个Word的\(\large Attention\ Score\)。
Transformer 是用上PE(Positional Encoding), 使得每一Word(Embedding)"都嵌入有位置顺序信息"(在 \(\large Self-Attention\) 并行计算 \(\large Attention\ Score\) 时)。
而且能并行计算 \(\large Attention\ Score\), 不必串行(一定计算完前一Word才能计算当前Word).
\(\large Self-Attention\) 的优点:
- 解决了"长序列依赖", 支持 "变长"的特长序列。
- 可\(\large Parallel\) (并行)计算 \(\large Attention\ Score\), 易 \(\large Scaleability\)。
大模型时,特别的合适。
![]()
- \(\large Self-Attention\)的\(\large W^q,\ W^k, W^v\) 都是统计分析"预训练数据"总结的规律.
也就是, 用"不同统计分布"的"预训练数据", 就可"训练出"对应行为的统计监督模型。
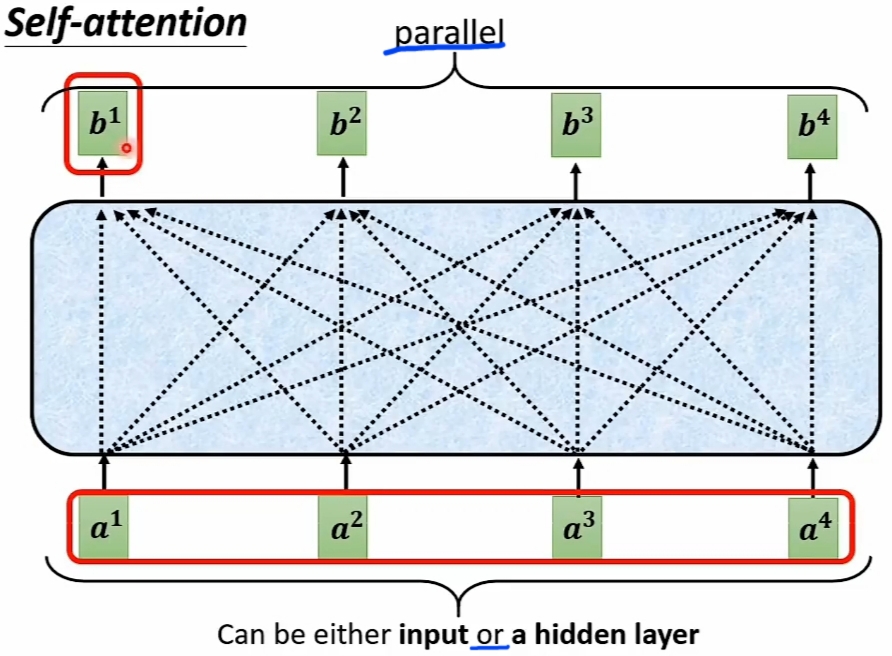
统计模型一旦设计好, 就可以"只更新 预训练数据", 而不必修改 模型. - \(\large Input\)可以是\(\large 模型Input\), 也可是\(\large Hidden\ Layers\)(隐藏层,非Input或Output).
- \(\large Seq2Seq\)模式: \(\large Output\)是 "模型决定可变长度的" 的 \(\large Output\ Sequence\).
1. Vectorize(向量化) and Matrixize(矩阵化) 不同的\(\large Input\) 数据
常用的数据类型有Text/Picture/Audio/Video/Graph:如社交网与分子图
Attention(注意力) 与 Self-Attention(自注意力)
1. 传统"\(\large Stepping\ Slip\ Window\)"采样方法
\(\large Input\) 为"变长"Matrix(Vector Sequence)时,
"\(\large Stepping\ Slip\ Window\)"(步进式滑动窗口)采样,
采集 \(\large COM(Co-Occurrence\ Matrix)\) 及\(\large Context\)的方式,
只能增大\(\large Length\ of\ Slip\ Window\) 以适应"变长"\(\large Input\).
不易实现"\(\large Scaleability\)可伸缩性.

Google的 \(\large Transformer\) 及 \(\large Self-Attention\) 易实现 \(\large Scaleability\).
\(\large Self-Attention\)自注意力机制
- \(\large Self-Attention\) 可与 \(\large FC\)(全连接层) 多层交替堆叠使用
![]()

\(\large Self-Attention\)的目标:
计算 变长 \(\large Vector\ Seq.\) 的任何两个 \(\large Vector\) 的 \(\large Attention(Relevant)\ Score\):
\(\large Self-Attention\)自注意力的实现
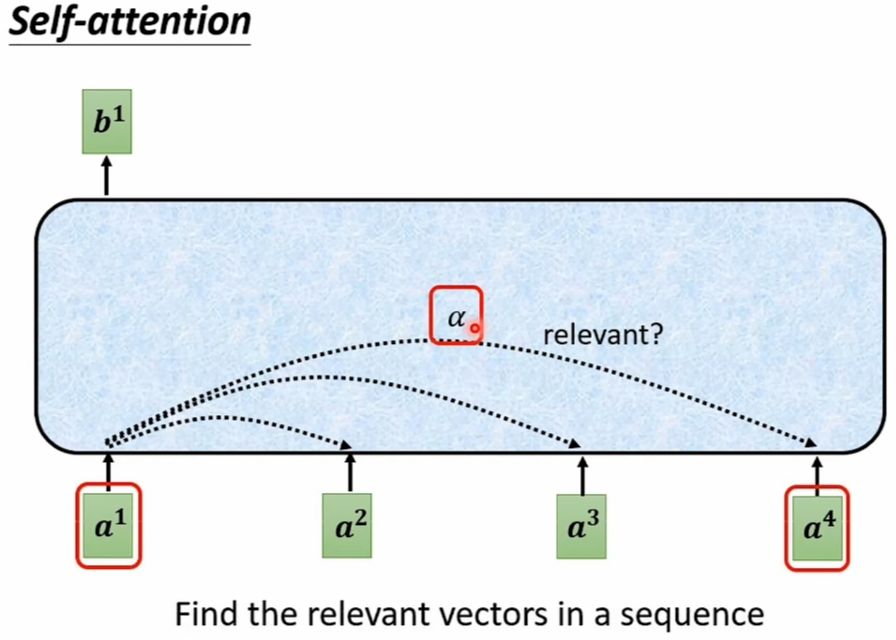
- 中心任务是 "Find the relevant vectors in a sequence":
![]()
- \(\large Self-Attention\)的\(\large Dot-Product\) 与 \(\large Additive\) 实现,常用前一种。
![]()
- \(\large Self-Attention\) 的 \(\large Dot-Product\) 实现精解
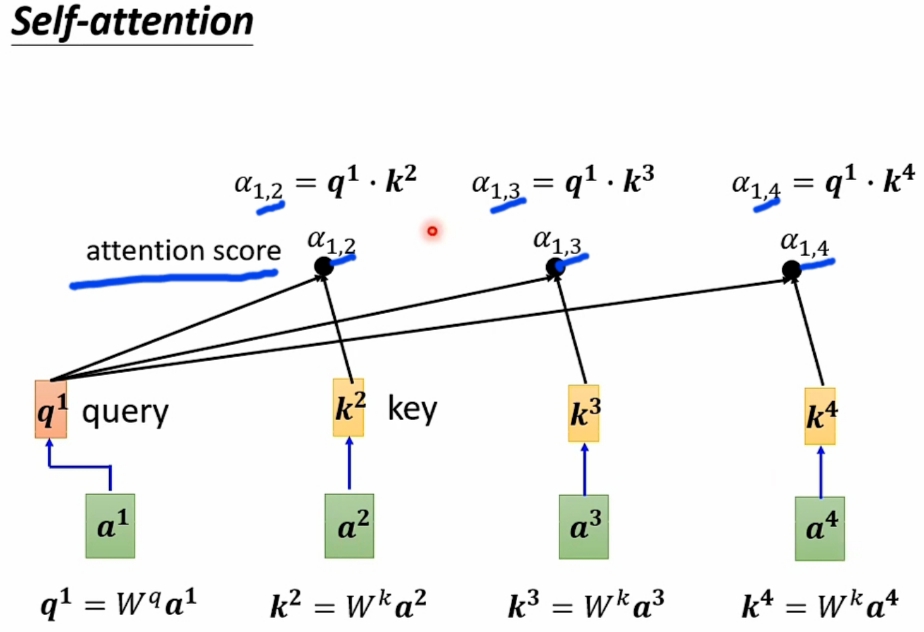
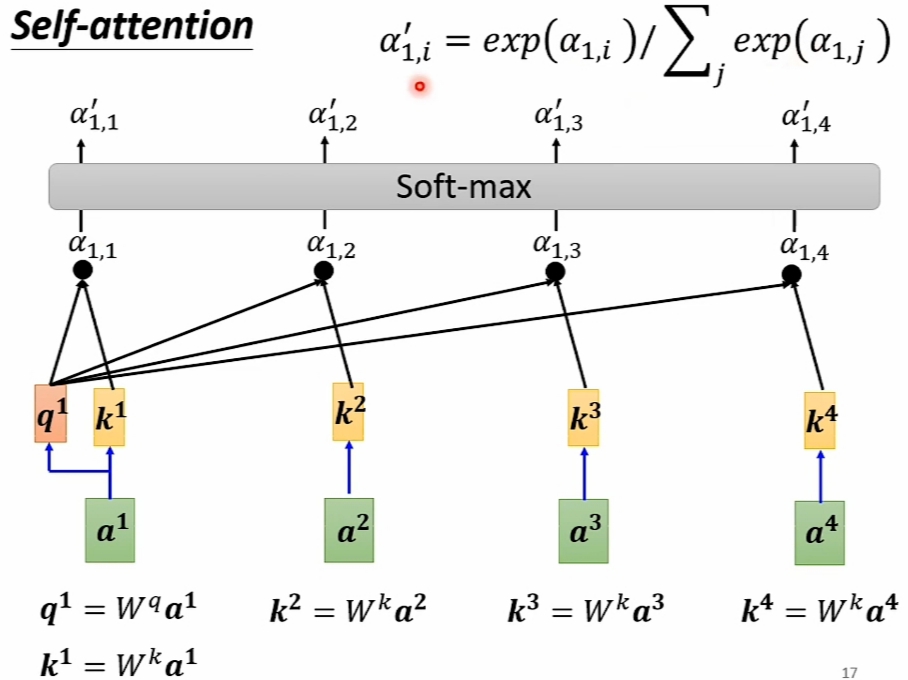
\(\large Hypothesis\) :- \(\large Input\ Vector\ Sequence\) 是\(\large [a^1, a^2, a^3, a^4]\)
- 求解的 \(\large Output\ Vector\ Sequence\) 设为:
\(\large [\alpha_{1,1}, \alpha_{1,2}, \alpha_{1,3}, \alpha_{1,4}, \
\alpha_{2,1},\alpha_{2,2},\alpha_{2,3},\alpha_{2,4}, \
\alpha_{3,1}, \alpha_{3,2},\alpha_{3,3},\alpha_{3,4}, \
\alpha_{4,1}, \alpha_{4,2},\alpha_{4,3},\alpha_{4,4}]\) - 以求解\(\large [\alpha_{1,1}, \alpha_{1,2}, \alpha_{1,3}, \alpha_{1,4}]\)为例:
![]()
![]()
![]()
![]()



SciTech-BigDataAIML-LLM-Transformer Series-$\large Supervised\ Statistical\ Model$监督学习的统计模型+$\large Transformer+Self Attention$的核心原理及实现的更多相关文章
- machine learning model(algorithm model) .vs. statistical model
https://www.analyticsvidhya.com/blog/2015/07/difference-machine-learning-statistical-modeling/ http: ...
- 《统计推断(Statistical Inference)》读书笔记——第6章 数据简化原理
在外行眼里统计学家经常做的一件事就是把一大堆杂七杂八的数据放在一起,算出几个莫名其妙的数字,然后再通过这些数字推理出貌似很靠谱的结论,简直就像是炼金术士用“贤者之石”把一堆石头炼成了金矿.第六章,应该 ...
- [MetaHook] Load large texture from model
We need hook "GL_LoadTexture" engine function. GL_LOADTEXTURE_SIG from hw.dll(3266) engine ...
- 王树森Transformer学习笔记
目录 Transformer Attention结构 Self-Attention结构 Multi-head Self-Attention BERT:Bidirectional Encoder Rep ...
- Could not find a transformer to transform "SimpleDataType{type=org.mule.transport.NullPayload
mule esb报错 com.isoftstone.esb.transformer.Json2RequestBusinessObject.transformMessage(Json2RequestBu ...
- Transformer【Attention is all you need】
前言 Transfomer是一种encoder-decoder模型,在机器翻译领域主要就是通过encoder-decoder即seq2seq,将源语言(x1, x2 ... xn) 通过编码,再解码的 ...
- (转)The Evolved Transformer - Enhancing Transformer with Neural Architecture Search
The Evolved Transformer - Enhancing Transformer with Neural Architecture Search 2019-03-26 19:14:33 ...
- 详解Transformer模型(Atention is all you need)
1 概述 在介绍Transformer模型之前,先来回顾Encoder-Decoder中的Attention.其实质上就是Encoder中隐层输出的加权和,公式如下: 将Attention机制从Enc ...
- 一文看懂Transformer内部原理(含PyTorch实现)
Transformer注解及PyTorch实现 原文:http://nlp.seas.harvard.edu/2018/04/03/attention.html 作者:Alexander Rush 转 ...
- ABBYY PDF Transformer+安装教程
ABBYY PDF Transformer+是一个新的全功能PDF文档工具,涵盖整个文档生命周期所涉及的各项功能,包括创建.讨论.批准.保护.转换成可编辑格式的PDF文件.文件合并.文本和图像的提取等 ...
随机推荐
- python 3 No module named ‘Crypto‘ 解决方案
pip3 install pycryptodome pip3 install crypto Pip3 install pycrypto 本机(mac)环境的解决方案: pip3 uninstall p ...
- 分享5款开源、美观的 WinForm UI 控件库
前言 今天大姚给大家分享5款开源.美观的 WinForm UI 控件库,助力让我们的 WinForm 应用更好看. WinForm WinForm是一个传统的桌面应用程序框架,它基于 Windows ...
- 工具分享 | SBSCAN 一款专注于Spring框架的渗透测试工具
0x00 工具介绍 SBSCAN是一款专注于spring框架的渗透测试工具,可以对指定站点进行springboot未授权扫描/敏感信息扫描以及进行spring相关漏洞的扫描与验证. 0x01 下载链 ...
- 信息资源管理综合题之“QS认证是什么标准 和 如何证明已通过QS 和 可否建立自己的生产标准”
一.案例:自2003年起,我国开始对大米.食用植物油等食品进行了一种新的管理制度:食品质量安全市场准入制度,到目前为止,所有经过加工的食品,生产地址在国内的产品全部必须申请生产许可证,经过强制性的检验 ...
- 从 UEFI 启动到双系统——记一次双系统 Linux 分区迁移
前言 我的台式电脑上,装了 Windows 和 Linux 双系统. 我有两块 1 TB 硬盘,就把它们叫作硬盘 0 和硬盘 1 吧.最开始的时候,硬盘 0 上装了 Windows 系统,而我的数据分 ...
- MFC窗口闪烁问题
本文引自:<VC窗口闪烁问题的解决> 概述 一般的windows复杂的界面需要使用多层窗口而且要用贴图来美化,所以不可避免在窗口移动或者改变大小时候出现闪烁. 闪烁产生的原因 原因一: 如 ...
- Third Maximum Number——LeetCode⑬
//原题链接https://leetcode.com/problems/third-maximum-number/ 题目描述 Given a non-empty array of integers, ...
- Java安全01——URLDNS链分析与利用
URLDNS链分析与利用 作用 URLDNS 利用链只能发起 DNS 请求,不能执行命令,所以用于漏洞的检测 不限制JDK版本,使用Java内置类,无第三方依赖要求 可以进行无回显探测 利用链 利 ...
- 实现一个前端动态模块组件(Vite+原生JS)
1. 引言 在前面的文章<使用Vite创建一个动态网页的前端项目>中我们实现了一个动态网页.不过这个动态网页的实用价值并不高,在真正实际的项目中我们希望的是能实现一个动态的模块组件.具体来 ...
- 第9讲、深入理解Scaled Dot-Product Attention
Scaled Dot-Product Attention是Transformer架构的核心组件,也是现代深度学习中最重要的注意力机制之一.本文将从原理.实现和应用三个方面深入剖析这一机制. 1. 基本 ...