揭秘AI编排爆火真相:从"人工智障"到"真正智能"的关键一跃
当行业还在追捧大模型参数竞赛时,领先团队早已转向新战场:
AI编排(Agent Orchestration)—— 这个方向是 AI 技术“从聊天到做事”的关键突破口。

- 1.为什么说不会编排的AI永远只是玩具?
- 2.直观体验编排能带来的实际好处
- 3.数据库在其中的关键作用
- 4.不同实现方式的效果对比
1.为什么说不会编排的AI永远只是玩具?
编排的本质就是把原本“一次问答”的AI能力升级为“任务驱动、步骤执行”的AI工作流。
Agent工作流相当于让AI按照我们用户的"做事逻辑"来真正产出用户所期待的成果。
因为虽然像以DeepSeek为代表的LLM自身的思维链(CoT)已经足够强悍了,但是用户在大部分企业级应用场景下,更需要的其实是符合其具体意图的特定结果。
2.直观体验编排能带来的实际好处
最近在做一个Agent工作流的Demo展示,旨在用最简单的用例向用户展示编排的效果,以及数据库在其中的关键作用。
下面就以这个最简单的例子来直观体验下编排能够给我们带来的实际好处。
这是一个非常简单的翻译场景需求:
用户要做一个专业技术文档的翻译,如果直接丢给LLM翻译,涉及到很多用户行业内特定的术语会翻译错误,人工进行二次检查修订的工作量又很大,而存在术语翻译错误的现象是因为LLM本身并不能直接理解某个行业细分领域的专业词汇。
但其实用户自己是很清楚这些专业词汇的,信息化做的好的用户,通常已经有这样的术语表了。
我们要做的,只是要把用户需要翻译的内容先匹配用户自己的术语表,进行术语替换,然后再给到LLM,让其翻译剩余部分,最终把整合后的结果返回给用户。
为了让读者朋友们更好的理解,我这里以公开技术资料Oracle的一些产品技术白皮书举例,编排工具这里用到的是比较火且更适合新手的Dify开源版,术语表放到Oracle数据库中。
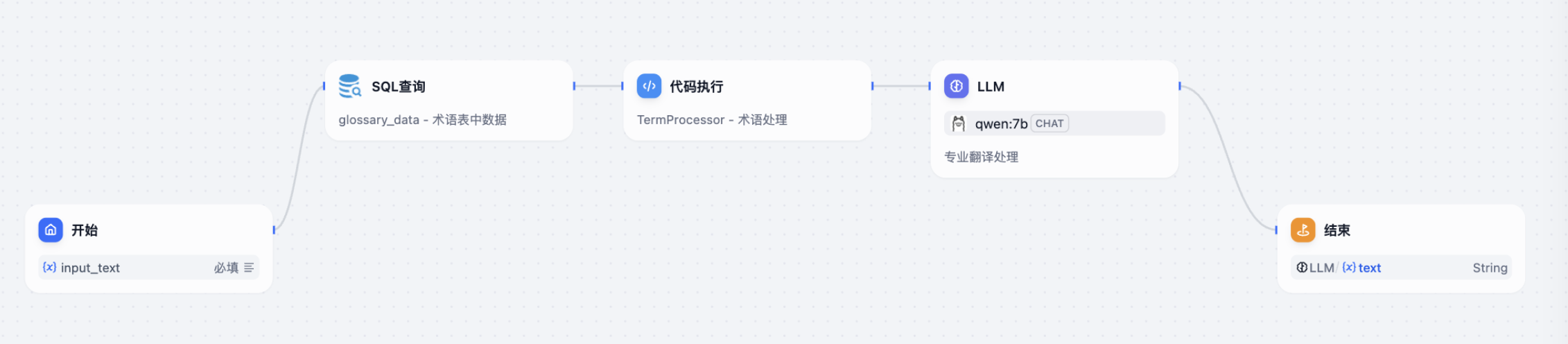
最开始我构建的工作流如上图所示,Dify的开始节点支持用户输入自己的翻译内容,SQL查询节点去Oracle数据库中查询术语表,然后直接将查询结果一股脑都给代码执行节点,通过Python来处理替换,之后给到LLM节点来进行规则翻译,最后结束节点展示翻译结果。
需要注意的是:
我选取的样例是公开技术资料,效果上其实并不如你自己企业内部的类似需求真实效果好。这是因为公开的资料LLM自己在训练时,多少已经有所感知,翻译不至于太拉胯,笔者会尽量找些明显差异点来进行展示。
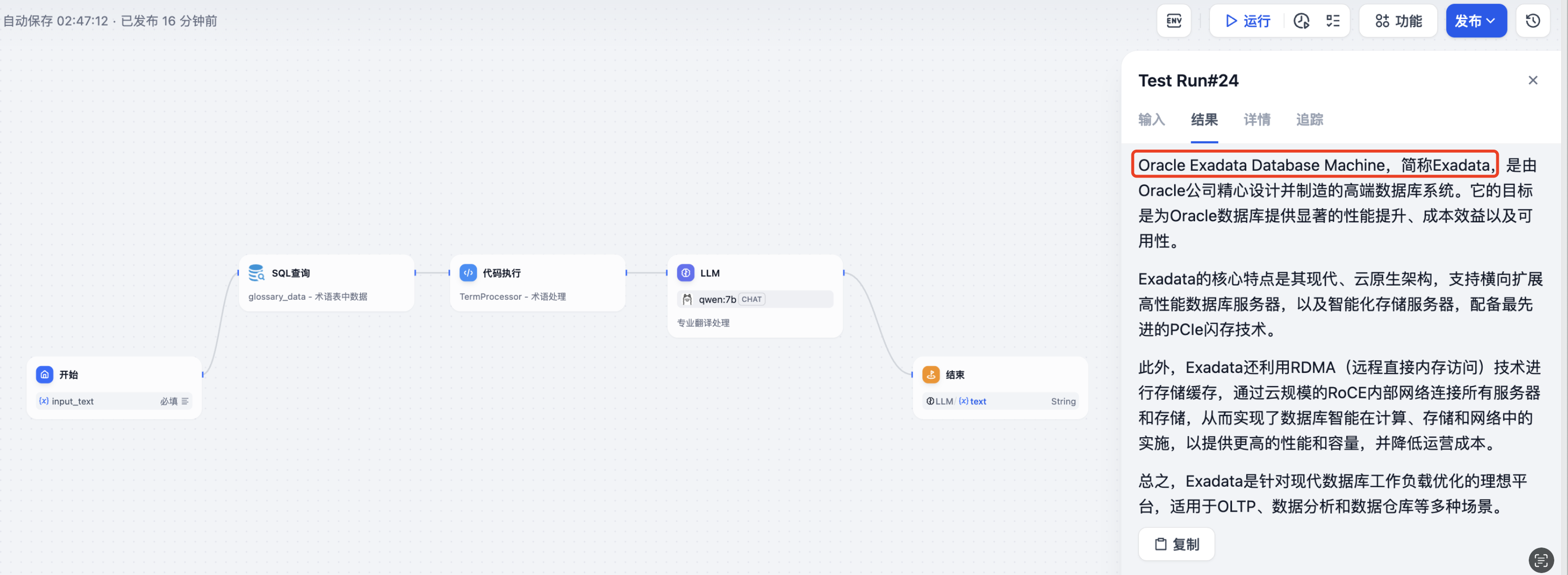
注意这里的比对要求是同样使用本地部署的qwen:7bLLM环境(因为LLM本身能力也是千差万别,所以这里先限制死LLM的变量统一,方便比对效果),我这里用一段Oracle Exadata的产品白皮书内容测试,直接丢给LLM翻译,和通过上面构建的工作流调用翻译,示例效果如下:
直接丢给LLM翻译,可以发现,会直接将Oracle Exadata Database Machine这款产品翻译为Oracle Exadata数据库机,这其实就很不专业,行业内通常要么翻译成数据库一体机,要么不翻译保留完整产品名词:

而使用通过上面构建的工作流调用翻译,就会按照术语表,保留了Oracle Exadata Database Machine这款产品名。
当然,这个术语表可以随时按需更新,比如你想把Oracle Exadata Database Machine翻译成Oracle Exadata 数据库一体机也是可以的。
3.数据库在其中的关键作用
数据库在其中到底起到什么作用呢?
比如我们上面提到的术语表,用户通常都是会把这样一张表存在数据库中,也方便不定期进行内容的更新。
但是上面的工作流其实还是有一个致命的缺点,就是不管用户的输入是什么,SQL查询节点都会把整张术语表直接返回给下一个代码执行节点做解析,虽然功能能够实现,但在处理效率、安全性方面都面临着巨大的风险。
那能不能把这个代码执行处理逻辑放到数据库中来实现呢?
答案当然是可以的!
起初因为SQL查询这个节点测试走了些弯路,所以才有了上面借助Python处理的传统工作流设计,后来测试发现其可以支持函数调用后,问题就变得更加简单高效了。
只需直接在库内封装一个函数,实现功能,把输入文本匹配用户术语表的工作直接交给这个库内函数来做。
这样,SQL查询这个节点只需要调用这个库内函数,设置传入用户输入的参数,也就是要翻译的文本内容,直接返回匹配的结果,然后直接交给LLM来做后面的翻译工作,直接砍掉了复杂的Python处理环节,简化了工作流。

另外提下,测试过程中发现本地7b的模型能力还是比较弱,表现时好时坏,不是很稳定。
有条件的用户还是尽可能使用更大参数量的模型,或者选择API调用,比如官方的DeepSeek。
4.不同实现方式的效果对比
下面以这个Demo为例,简单总结下这三种不同的实现方式。
三种翻译方案核心对比
| 方案维度 | 直接调用LLM | Python+术语表 | 数据库+术语表 |
|---|---|---|---|
| 术语准确性 | 随机性大,易现"数据库机"等错误 | 可解决基础术语问题 | 专业术语精准锁定 |
| 实现复杂度 | 零开发成本 | 需编写复杂处理逻辑 | 声明式配置即可完成 |
| 处理效率 | 多次交互,反复编写提示词调整 | Python处理全部术语有性能瓶颈 | 利用数据库原生计算优势,还可使用全文索引提速 |
| 安全可靠性 | 存在数据泄露风险 | 需自行实现安全机制 | 库内处理天然隔离 |
| 扩展可能性 | 无法叠加其他能力 | 需额外开发对接模块 | 原生支持多模态协同,可提供RESTful API |
当AI技术通过更多人参与的编排更进一步时,会有大量越来越复杂的智能体出现,随着最近的MCP和A2A协议的重磅推出,AI发展将会日新月异,也切身感受到我们离AI的“真正智能”那一天更近了。
揭秘AI编排爆火真相:从"人工智障"到"真正智能"的关键一跃的更多相关文章
- 把python学的让自己成为智障的day14
智障的第14天,今天还是装饰器,这也是这个难点,装饰器也是函数的其中一种,所以需要有返回值才能返回到之后要执行的函数中,当然,作为函数可以在其中带上参数,装饰器只是比较特殊,自然也可以带参数,目前来说 ...
- 0122(本来是想ak的但是因为智障只拿了200。)
今天考了一场小测试,额,非常非常水,但是智障的我才A掉两道题. T1: 1.暑假作业 (mtime.pas/c/cpp) [问题描述] 暑假作业是必须要写的,越到假期结束前,写作业的效率就越高,小 ...
- 一个智障安装了一天的python和graphlab的血泪史
大概的过程是这样的: 先装了python3.6.1.,然后发现搞错了Σ(  ̄□ ̄||),是32 bit的,卸了重装python 3.6.1 (64bit). 然后装easy_install.pip.i ...
- 插头DP智障操作合集
今天一共四道插头DP[其实都差不多],智障错误出了不下五个:D 来,让我好好数落我自己一下 直接写代码注释里吧 Eat the Trees #include<iostream> #incl ...
- 学习人工智还死拽着Python不放?大牛都在用Anaconda5.2.0
前言 最近有很多的小白想学习人工智能,可是呢?依旧用Python在学习.我说大哥们,现在都什么年代了,还在把那个当宝一样拽着死死不放吗?懂的人都在用Anaconda5.2.0,里面的功能可强大多了,里 ...
- python 人工智论
https://www.zhihu.com/question/21395276 基于python深度学习库DeepPy的实现:GitHub - andersbll/neural_artistic_st ...
- AI+教育落地,百度大脑如何让校园更智能?
人工智能作为影响社会底层技术革命逐渐向传统行业渗透,“AI+”已经替代“互联网+”成为创业创新的新引擎,出人意料的是,在AI在教育业的率先落地并且相当火爆. 现在,人工智能教育已成为从业者心目中的“教 ...
- OI回忆录——一个过气OIer的智障历程
初中 初一参加学校信息学选修课,一周一节课,学pascal. 初一寒假(大约是)入选(其实是钦定吧)当时加上我只有3人的校队(我当然是最弱的一个. 当时甚至有幸得到叉姐授课(现在才知道这是多么难得的机 ...
- Get Luffy Out * HDU - 1816(2 - sat 妈的 智障)
题意: 英语限制了我的行动力....就是两个钥匙不能同时用,两个锁至少开一个 建个图 二分就好了...emm....dfs 开头low 写成sccno 然后生活失去希望... #include & ...
- Go Deeper HDU - 3715(2 - sat 水题 妈的 智障)
Go Deeper Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total S ...
随机推荐
- TDGO(灯塔狩猎者)—一款分布式灯塔信息收集工具
GitHub: https://github.com/lxflxfcl/DTGO 作者语:嘘,我正在狠狠鞭打你的灯塔 DTGO (灯塔收割者) 是一个用于批量管理和监控资产灯塔系统任务的图形化工具.它 ...
- java内部类与单例模式
java中不允许外部类使用 private,protected 修饰 所谓的外部类:就是在源码中直接声明的类 所谓的内部类: 就是类中声明的类,内部类可以使用 public, private, pro ...
- 【忍者算法】LeetCode必刷100题:一份来自面试官的算法地图(题解持续更新中)
(本文字数2900,阅读大约需15分钟) 上一篇文章我们讨论了如何科学地刷题,今天我要带大家深入了解这100道精选题目背后的分类逻辑.作为一名面试官,我希望通过这篇文章,为大家绘制一张完整的算法知识地 ...
- idea插件仓库连接不到网络
IDEA的插件中心连不上网 打开:设置-插件 选择:设置按钮-HTTP代理设置 勾选自动设置 输入 https://plugins.jetbrains.com/或者 http://127.0.0.1: ...
- 在阿里云ECS上一键部署DeepSeek-R1
DeepSeek-R1 是一款开源模型,也提供了 API(接口)调用方式.据 DeepSeek介绍,DeepSeek-R1 后训练阶段大规模使用了强化学习技术,在只有极少标注数据的情况下提升了模型推理 ...
- changeServer.sh一键切换服务器脚本
直接看改进版2.0 切换服务器,免密登录vi changeServer.sh #!/bin/bash #authe by wangxp export IFCFG=/etc/sysconfig/netw ...
- Codeforces Round 999 比赛记录
前情提要 这个菜鸡CF上了 \(\color{darkcyan}Specialist\),心情大好,正好赶上放假,决定打一场CF. 赛时记录 A 上来脑子抽了,吃了一发罚时.发现写错了一种情况,改过来 ...
- MySQL - [08] 存储过程
题记部分 一.什么是存储过程 存储过程是事先经过编译并存储在数据库中的一段SQL语句的集合,调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效 ...
- CF2018C Tree Pruning
分析 好像官方题解是反向求解的,这里提供一个正向求解的思路,即直接求出最后所有叶节点到根的距离相同为 \(x\) 时需要删除的结点数 \(ans_x\) . 如果我们最后到根的相同距离为 \(x\), ...
- 基于项目的协同过滤推荐算法(Item-Based Collaborative Filtering Recommendation Algorithms)
前言 协同过滤推荐系统,包括基于用户的.基于项目的息肉通过率等,今天我们读一篇基于项目的协同过滤算法的论文. 今天读的论文为一篇名叫<基于项目的协同过滤推荐算法>(Item-Based C ...