内存吞金兽(Elasticsearch)的那些事儿 -- 数据结构及巧妙算法
系列目录
内存吞金兽(Elasticsearch)的那些事儿 -- 认识一下
内存吞金兽(Elasticsearch)的那些事儿 -- 数据结构及巧妙算法
内存吞金兽(Elasticsearch)的那些事儿 -- 架构&三高保证
内存吞金兽(Elasticsearch)的那些事儿 -- 写入&检索原理
内存吞金兽(Elasticsearch)的那些事儿 -- 常见问题痛点及解决方案
ES 本质上是一个支持全文搜索的分布式内存数据库,特别适合用于构建搜索系统。ES 之所以能有非常好的全文搜索性能,最重要的原因就是采用了倒排索引。倒排索引是一种特别为搜索而设计的索引结构,倒排索引先对需要索引的字段进行分词,然后以分词为索引组成一个查找树,这样就把一个全文匹配的查找转换成了对树的查找,这是倒排索引能够快速进行搜索的根本原因。
倒排索引
一图胜千言

再举个例子
假设我们有这样两个商品,一个是烟台红富士苹果,一个是苹果手机 iPhone XS Max。
|
DOCID
|
SKUID
|
标题
|
|---|---|---|
| 666 | 1234 | 烟台红富士苹果 |
| 888 | 1235 | 苹果手机 iPhone XS Max |
这个表里面的 DOCID 就是唯一标识一条记录的 ID,和数据库里面的主键是类似的。
倒排索引的存储
|
TERM
|
DOCID
|
|---|---|
| 烟台 | 666 |
| 红富士 | 666 |
| 苹果 | 666,888 |
| 手机 | 888 |
| iPhone | 888 |
| XS | 888 |
| Max | 888 |
可以看到,这个倒排索引的表,它是以单词作为索引的 Key,然后每个单词的倒排索引的值是一个列表,这个列表的元素就是含有这个单词的商品记录的 DOCID。
当我们往 ES 写入商品记录的时候,ES 会先对需要搜索的字段,也就是商品标题进行分词。分词就是把一段连续的文本按照语义拆分成多个单词。然后 ES 按照单词来给商品记录做索引,就形成了上面那个表一样的倒排索引。当我们搜索关键字“苹果手机”的时候,ES 会对关键字也进行分词,比如说,“苹果手机”被分为“苹果”和“手机”。然后,ES 会在倒排索引中去搜索我们输入的每个关键字分词,搜索结果应该是:
|
TERM
|
DOCID
|
|---|---|
| 苹果 | 666,888 |
| 手机 | 888 |
666 和 888 这两条记录都能匹配上搜索的关键词,但是 888 这个商品比 666 这个商品匹配度更高,因为它两个单词都能匹配上,所以按照匹配度把结果做一个排序,最终返回的搜索结果就是:
苹果Apple iPhone XS Max
烟台红富士苹果
这个搜索过程,其实就是对上面的倒排索引做了二次查找,一次找“苹果”,一次找“手机”。注意,整个搜索过程中,我们没有做过任何文本的模糊匹配。ES 的存储引擎存储倒排索引时,肯定不是像我们上面表格中展示那样存成一个二维表,实际上它的物理存储结构和 MySQL 的 InnoDB 的索引是差不多的,都是一颗查找树。
elasticsearch中的数据结构
(当然也是lucene的数据结构
升级版倒排索引
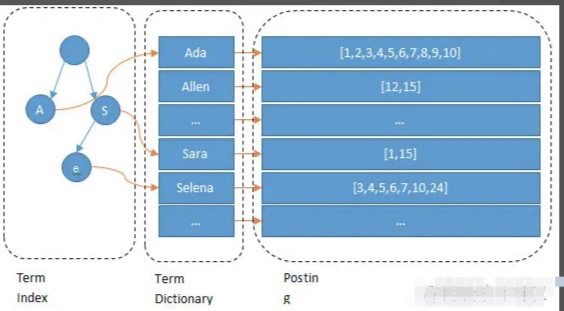
组成三部分
term dictionary
会根据分词器对文字进行分词(也就是图上所看到的Ada/Allen/Sara..),这些分词汇总起来叫做Term Dictionary
优化手段
该部分的词会非常非常多,所以es内部对其进行了排序,使用二分查找法来查,故而就不需要遍历整个词集
posting list
通过分词找到对应的记录,这些文档ID保存在PostingList
优化手段
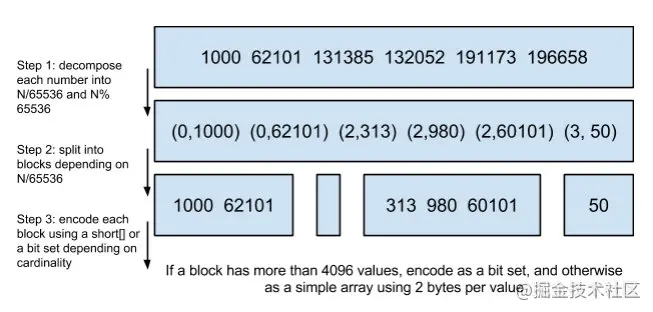
为节约磁盘空间和快速得出交并集结果 。使用FOR以及RBM编码技术对内容压缩
FOR原理

RBM原理
term index
由于Term Dictionary的词实在太多了,不可能把Term Dictionary所有的词都放在内存中,于是elastic还抽了一层叫做Term Index,这层只存储 部分 词的前缀,Term Index会存在内存中(检索会特别快)
这里遗留一个问题,如果Term Index树还是很大怎么办?
找的时候咋找
字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。大大减少了磁盘随机读的次数
优化手段
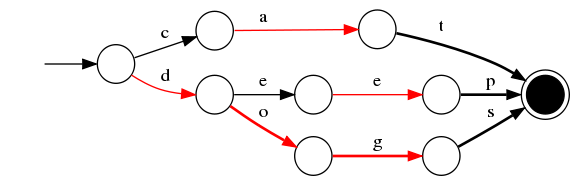
为节省内存 ,该部分在内存中是以FST(https://cs.nyu.edu/~mohri/pub/fla.pdf)的形式保存的
- 1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
- 2)查询速度快。O(len(str))的查询时间复杂度。
更多优化
当对多个字段进行检索时,利用了bitmap按位与进行归并优化(本身也是用bitmap的方式进行了存储
# 假设条件为name=fsdm and age=18取出来的数据如下 |
注:在特定场景非bitmap存储时,使用跳表来进行联合查询
为啥快
- 磁盘东西尽量搬内存
- 各种奇技淫巧算法
- 苛刻态度使用内存
内存吞金兽(Elasticsearch)的那些事儿 -- 数据结构及巧妙算法的更多相关文章
- 内存吞金兽(Elasticsearch)的那些事儿 -- 认识一下
背景及常见术语 背景 Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene 基础之上. Lucene 可以说是当下最先进.高性能.全功能的搜索引擎库- ...
- 内存吞金兽(Elasticsearch)的那些事儿 -- 常见问题痛点及解决方案
1.大数据量的查询效率如何保证: 查询的流程:往 ES 里写的数据,实际上都写到磁盘文件里去了,查询的时候,操作系统会将磁盘文件里的数据自动缓存到 Filesystem Cache 里面去 最佳的情况 ...
- VUE温习:内存泄漏、Vue.$set、key作用与虚拟diff算法
一.内存泄漏 1.指令绑定了事件,却没有解绑事件,容易产生内存泄漏.(曾经遇到过的案例) 2.v-if指令产生内存泄漏,比如v-if删除了父级元素,却没有删除父级元素里的dom片段 3.跳转到别的路由 ...
- Plan B
王兴曾经说过: 2019 年是过去 10 年中最差的一年,也是未来 10 年中最好的一年. 之前我希望王兴预判错了,但现在我发现这位掌控着生活消费类数据的大佬应该不是扯淡. 今年的内部和外部环境真的很 ...
- Elasticsearch内存分配设置详解
Elasticsearch默认安装后设置的内存是1GB,对于任何一个现实业务来说,这个设置都太小了.如果你正在使用这个默认堆内存配置,你的集群配置可能会很快发生问题. 这里有两种方式修改Elastic ...
- elasticsearch.in.sh优化内存
elasticsearch.in.sh文件主要是内存优化 ES_MIN_MEM=24g(24g是物理内存的一半) ES_MAX_MEM=24g ES调优: 1.Java层面的调优,加大JVM的可用内存 ...
- ElasticSearch优化系列二:机器设置(内存)
预留一半内存给Lucene使用 一个常见的问题是配置堆太大.你有一个64 GB的机器,觉得JVM内存越大越好,想给Elasticsearch所有64 GB的内存. 当然,内存对于Elasticsear ...
- [翻译]Elasticsearch重要文章之二:堆内存的大小和swapping
Elasticsearch默认安装后设置的内存是1GB,对于任何一个业务部署来说,这个都太小了.如果你正在使用这些默认堆内存配置,你的集群配置可能有点问题. 这里有两种方式修改Elasticsearc ...
- Elasticsearch内存分配设置详解(转)
Elasticsearch默认安装后设置的内存是1GB,对于任何一个现实业务来说,这个设置都太小了.如果你正在使用这个默认堆内存配置,你的集群配置可能会很快发生问题.这里有两种方式修改Elastics ...
- 关于ElasticSearch的堆内存设置与优化
1.什么是堆内存?Java 中的堆是 JVM 所管理的最大的一块内存空间,主要用于存放各种类的实例对象.在 Java 中,堆被划分成两个不同的区域:- 新生代 ( Young ).- 老年代 ( Ol ...
随机推荐
- Sql高级
sql高级 1. 索引与视图 常见的数据结构 栈:先进后出 队列:先进先出 数组:查询快,根据下标查询 链表:分为双链表与单链表.单链表指向下一个数据的存储位置:双链表指向前一个与下一个数据的存储位置 ...
- Docker Compose容器编排--项目五
一.Docker Compose概念 Docker Compose (可简称Compose)是一个定义与运行复杂应用程序的 Docker 工具,是 Docker 官方 编排(Orchestration ...
- Paimon lookup store 实现
Lookup Store 主要用于 Paimon 中的 Lookup Compaction 以及 Lookup join 的场景. 会将远程的列存文件在本地转化为 KV 查找的格式. Hash htt ...
- SICTF 2024 Round4 Crypto
SICTF-Round4--Crypto SignBase task: U0lDVEZ7ODI5MGYwZWYtNzAyYi00NTZmLTlmZjYtNGRhZjhhYTIzNWU1fQ== exp ...
- Ubuntu使用dpkg查看与修改architecture的用法
dpkg是Debian的包管理器,因为Ubuntu是Debian的变体,在Ubuntu下也有这个工具. 两个常用的命令是: dpkg -i package-file和dpkg -r package 分 ...
- .NET操作Excel高效低内存的开源框架 - MiniExcel
.Net平台上对Excel进行操作主要有两种方式.第一种,把Excel文件看成一个数据库,通过OleDb的方式进行读取与操作:第二种,调用Excel的COM组件.两种方式各有特点. 今天给大家介绍第三 ...
- 4.使用二进制方式搭建K8S集群
使用二进制方式搭建K8S集群 注意 [暂时没有使用二进制方式搭建K8S集群,因此本章节内容不完整... 欢迎小伙伴能补充~] 准备工作 在开始之前,部署Kubernetes集群机器需要满足以下几个条件 ...
- 3. jenkins的管理
1. jenkins的插件管理 Jenkins本身不提供很多功能,我们可以通过使用插件来满足我们的使用.例如从Gitlab拉取代码,使用Maven构建项目等功能需要依靠插件完成.接下来演示如何下载 ...
- axios获取上传进度报错xhr.upload.addEventListener is not a function
错误问题 Vue:xhr.upload.addEventListener is not a function 这个问题是因为mockjs改动了axios里面XMLHttpRequest对象致使的 根据 ...
- KnowledgeManagement
知识管理建议 总则 总参 从无知到有知 资料收集的习惯 发表是最好的记忆 Wiki 使用 建议: Blog 写作 Discuss 搜索技巧 回复:Yibie的知识管理流程与工具选择 一.个人知识管理的 ...