MySQL——InnoDB存储引擎
.ibd文件结构
从 MySQL 5.6.6 版本开始,默认一个表是一个.ibd文件,关于表的所有信息都保存在这个文件里。数据库IO操作的基本单位是页,.idb的基本组成也是页,如下图所示,一个.idb是由不同功能的页组织而成的,一个页的大小是16KB,页与页之间通过双向链表连接。每一个页都有自己的页号,链表指针指向下一个页号,页号是全局分配的。
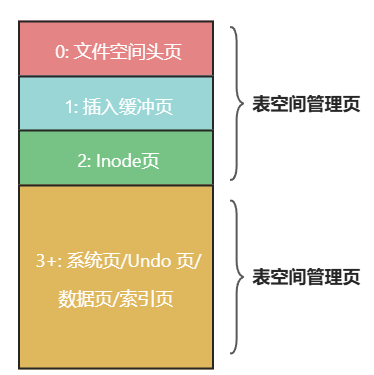
页是基本组成单位,而不是空间分配的基本单位,也不是表内所有页的管理单位。InnoDB管理磁盘空间的逻辑单位是段,用于组织索引页、数据页、Undo页等资源,每个段都会被分配一个或多个区,这些区再包含实际的页。区是InnoDB空间分配的基本单位,一个区的大小是1MB。
当我们构建一个索引会构建一个索引段,然后为索引段申请一个区的空间,这个段将记录在Inode页。Inode页记录着每一个段使用的区,以及每一个区中未被使用的页链表。
Undo段
事务会构建Undo段,但是不同于索引和索引段一一对应的关系,Undo段会产生复用,由整个InnoDB的Rollback Segment来管理,Undo段并不在我们构建的.ibd文件里,在系统表空间ibdata1.ibd里。Undo段是系统级资源,与具体的用户表无关,也不属于任何单表空间,因此由系统维护的。
页的类型
每一个页有FIL_PAGE_TYPE字段记录页的类型,下面是常见的一些页:
数据页(Data Page):存储表中的实际数据行,每个数据页包含一个页头、用户数据区域和页尾。
索引页(Index Page):存储 B+ 树索引的节点,索引页分为内部节点页和叶子节点页。
Undo 页(Undo Page):存储事务回滚所需的数据。
Redo Log 缓冲页(Redo Log Buffer Page):用于缓存 Redo Log 数据。
系统页(System Page)
表空间管理页的功能
页0 — 文件头页
FIL_PAGE_TYPE = 0x0002,主要保存表空间的元信息,包括表空间ID、页空间大小、已使用页数、空闲页链表的头指针、已分配的区信息、表空间类型、表空间是否加密、页大小(通常16KB)。简单说,页0记录表空间整体动态变化,包括已分配多少页、空闲页。
Space ID: 12
Space Size: 64 pages
Used pages: 3
Free list starts at page: 3
Next Segment ID: 2
页1 — Buffer Bitmap Page页
动态记录哪些区正在被insert buffer用来缓存二级索引插入操作,insert buffer是系统表空间ibdata1 中的专属页,所有表共享一套insert buffer机制,但每张表自己维护一个Bitmap图,记录哪些页被insert buffer操作过。
Insert Buffer Bitmap:
Extent 0: not used
Extent 1: not used
Extent 2: not used
页2 — Inode页
页2主要用来维护自由页链表,记录该空间内可用的空闲页,也用于段管理,辅助管理段的空闲情况。这个页会被InnoDB用来快速找到空闲页,以便新数据插入。
Segment 1: Primary Clustered Index
Root Page: 4
Full Extents: None
Free Extents: from page 5
构建一个段时发生了什么?
CREATE INDEX idx_user ON orders(user_id);会新建一个二级索引,新建一个索引就会分配一个新的段。
表头页从free extent list分配一个区,初始化为该二级索引段使用:
Used pages: 加64
Free list: 向后移动
Inode页新增一个段描述符,记录记录段 ID、根页页号、区列表等,通常一个新的段只会分配一个区,64页,1MB:
Segment 3:
Root Page: 200
Extents: 200~263
这64个页会构建成一个B+ Tree结构,这个在后面会仔细介绍。只是新建一个二级索引,Buffer Bitmap页不会有变化。
构建一个区时发生了什么?
当段的空闲页不够时,就会向Segment Manager发起区分配请求,Space Manager会从它所在的.ibd文件的表头页的free extent list中取新的extent。如果free list中还有空闲的extent,就会分配给整个段,同时更新Inode页和表头页。如果没有,则会触发.ibd 文件物理扩展,扩充新的区。最终,三大管理页会发生修改。
表头页free extent list减少一个区,已用pages增加64;Inode页的对应段free extent list增加新分配的区,full extent list增加已经写满的区。Bitmap页不会发生变化。
构建一个页时发生了什么?
只是构建了一个新的页,表头页和Bitmap页不会发生变化。Inode页中,段内部的free page bitmap会标记页已经使用,段的空闲页计数减少,区的状态仍然标记为free。
插入一条二级索引会发生什么?
有一张表:
CREATE TABLE orders (
order_id BIGINT PRIMARY KEY,
user_id BIGINT,
status VARCHAR(20),
INDEX idx_user (user_id)
) ENGINE=Inn
当执行INSERT INTO orders VALUES (1, 1001, 'PAID');时,会先插入主键索引,直接写入数据页中。接着寻找二级索引的目标页,计算user_id = 1001应该插入的二级索引B+Tree位置,如果页在内存中,直接修改页,不再内存中,会将这条插入记录:
表空间 ID、索引 ID、页号、插入的 user_id=1001、order_id=1
写入系统表空间的Insert Buffer Tree,同时更新.ibd文件的第1页:
extent 5: 被 Insert Buffer 缓存
等到有访问查询到这个页时,再真正的更新索引页。
页结构
数据页代表的这块16KB大小的存储空间可以被划分为多个部分,不同部分有不同的功能,各个部分如图所示:
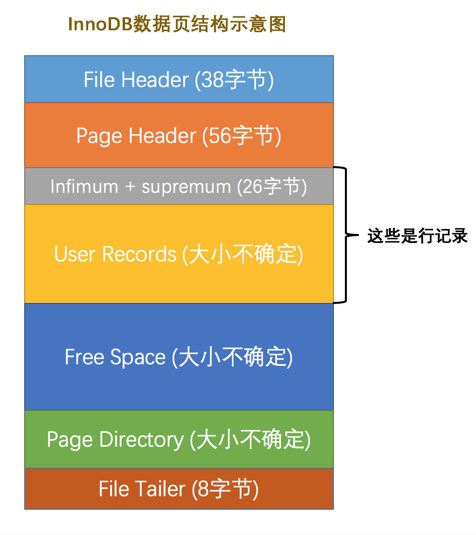
从图中可以看出,一个InnoDB数据页的存储空间大致被划分成了7个部分,有的部分占用的字节数是确定的,有的部分占用的字节数是不确定的。下面我们用表格的方式来大致描述一下这7个部分都存储一些什么内容:
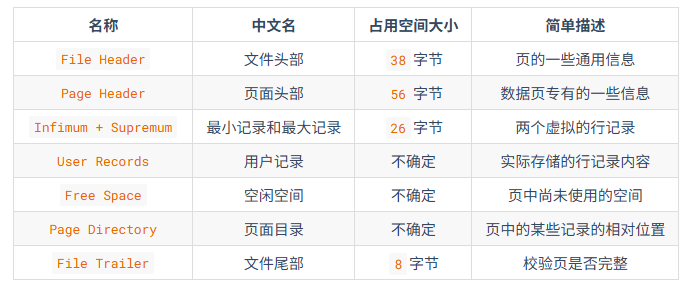
我们自己存储的记录会按照我们指定的行格式存储到User Records部分。但是在一开始生成页的时候,其实并没有User Records这个部分,每当我们插入一条记录,都会从Free Space部分,也就是尚未使用的存储空间中申请一个记录大小的空间划分到User Records部分,当Free Space部分的空间全部被User Records部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了。
页的7个部分,可以被划分为三个部分。
第一部分:文件头和文件尾
文件头描述页的通用信息,页号、页的类型、两个双向指针(各4字节)、校验和(防止信息被更改)、页面被最后修改时对应的日志序列位置。文件尾维护同样的校验和以及页面被最后修改时对应的日志序列位置。
第二部分:空闲空间、用户记录、最大最小记录
用户记录的格式将在下一个章节中介绍,这里只需要知道,用户记录是单项的,每一天指向下一个用户记录。最大和最小记录是伪记录,类似于我们写链表时的哨兵,最小记录是链表头,最大记录是单项链表尾。不论我们怎么对页中的记录做增删改操作,InnoDB始终会维护一条记录的单链表,链表中的各个节点是按照主键值由小到大的顺序连接起来的。
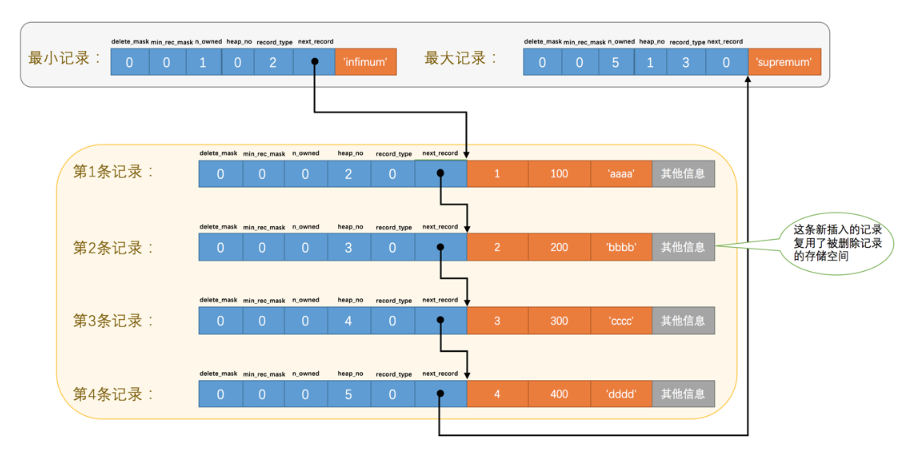
第三部分:页头、页目录
单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。因此在页结构中专门设计了页目录这个模块,专门给记录做一个目录,通过二分查找法的方式进行检索,提升效率。
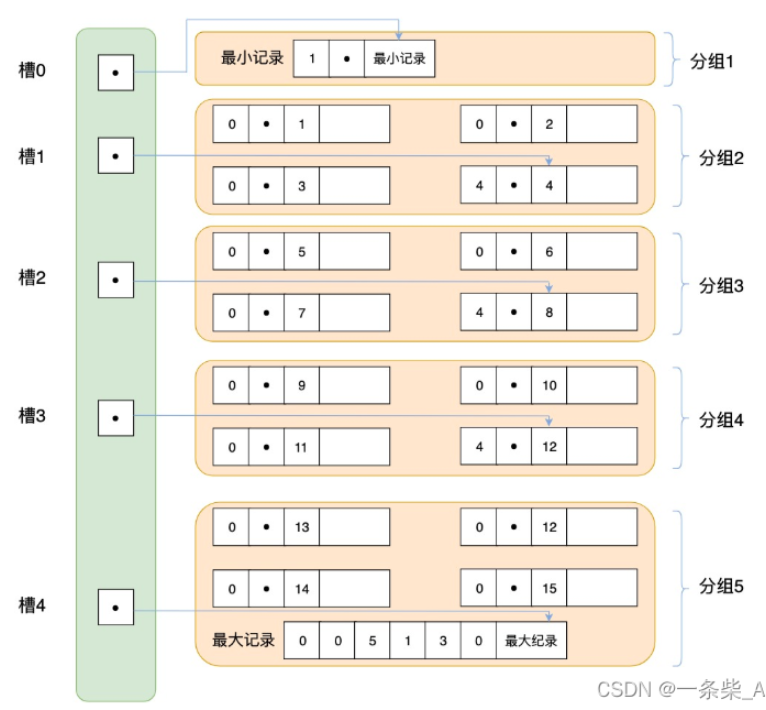
为了方便二分查找,页目录采用分组的方式,一个组就是一个槽,每一个槽尽量平分。第一个槽只有一条最小伪记录,最后一条加上了最大伪记录。每一个槽的最后一条记录,标记了整个槽有多少条记录。
每个分组中的记录条数是有规定的:对于最小记录所在的分组只能有 1 条记录,最大记录所在的分组拥有的记录条数只能在 1~8 条之间,剩下的分组中记录的条数范围只能在是 4~8 条之间。
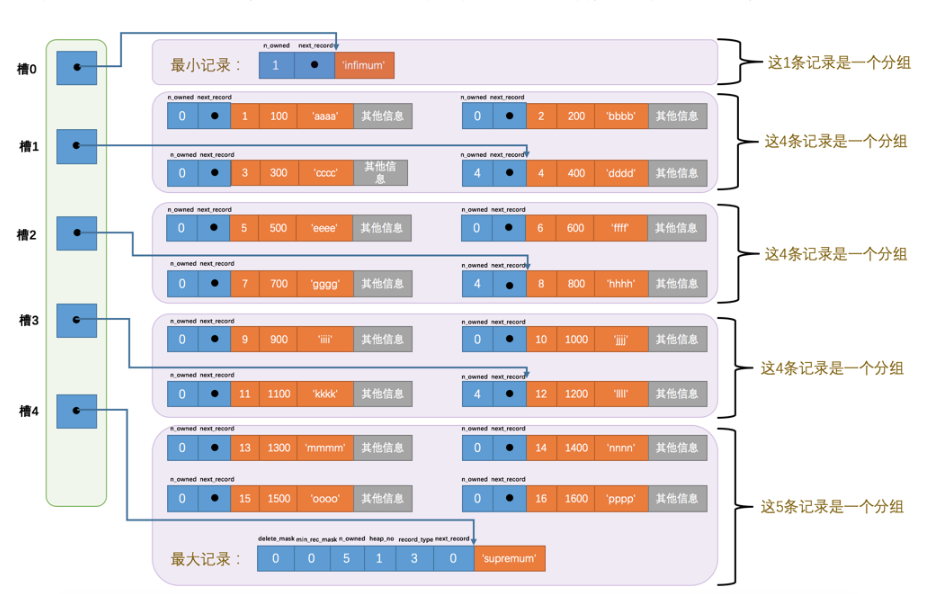
在一个数据页中查找指定主键值的记录的过程分为两步:1. 通过二分法确定该记录所在的槽,并找到该槽中主键值最小的那条记录。2. 通过记录的next_record属性遍历该槽所在的组中的各个记录。
行记录结构
mysql> CREATE TABLE record_format_demo (
-> c1 VARCHAR(10),
-> c2 VARCHAR(10) NOT NULL,
-> c3 CHAR(10),
-> c4 VARCHAR(10)
-> ) CHARSET=ascii ROW_FORMAT=COMPACT;
Query OK, 0 rows affected (0.03 sec)
在创建一个表时,我们可以指定表的行格式。InnoDB存储引擎到现在为止设计了4种不同类型的行格式,分别是Compact、Redundant、Dynamic和Compressed行格式,在MySQL 5.1版本中,默认设置为Compact行格式。
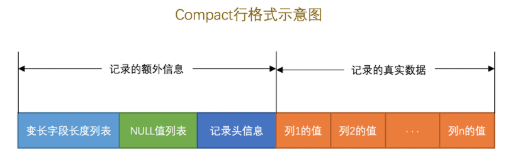
变长字段长度列表
MySQL有一些变长的数据类型,变长字段中储存多少字节的数据是不固定的,所以储存真实数据时要将数据占用的字节数页储存起来。把所有变长字段的真实数据占用的字节长度都存放在记录的开头部位,从而形成一个变长字段长度列表,各变长字段数据占用的字节数按照列的顺序逆序存放。
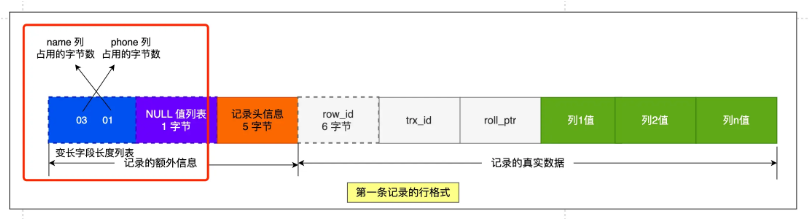
一个字段长度可能是一个字节,也可能是两个字节,具体看变长字段的类型。变长字段长度列表中只存储值为 非NULL的列内容占用的长度,值为NULL的列的长度是不储存的。
NULL值列表
也是逆序排序的,只有没有被NOT NULL修饰的列才会有NULL值。NULL值列表是一个bit map,所以的NULL值得bit位紧凑排列,不足一个字节会在前面补零补成一个字节。
在5.7版本及以前,表结构的信息,谁是非NULL列等会保存在.frm文件中。在MySQL 8.0,InnoDB会把表的完整元数据以内部系统表的形式存储在共享表空间 (ibdata) 或每张表的.ibd里。8.0版本开始所有表共用一个 “数据字典表”,存储在InnoDB内部表里,不允许用户直接修改。
记录头信息
由五个字节组成,不同的位有不同的含义,其中有几个重要二进制位:
n_owned:4位,当前的记录拥有的记录数,在上一个部分中介绍的每一个槽的记录数。heap_no:13位,当前的记录在记录堆中的位置信息。record_type:3位,0表示普通记录,1表示B+树非叶子节点记录,2和3是最小最大记录。next_record:16位,记录下一条数据的相对位置。
隐藏列
上述的记录头之后就是真实数据,MySQL会为每个记录默认的添加一些列(也称为隐藏列),具体的列如下:
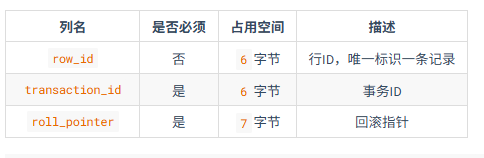
隐藏列会给对应的列一些额外的说明,比如是不是主码,row_id用来标记谁是主码。
数据页组织结构——B+树
在开始前,需要强调的是,并不是所有的数据页都是B+树,不同的索引类型底层的页组织方式也不一样,主键索引、唯一索引、普通索引是B+树,其它的索引类型有自己的底层结构,数据页的组织方式除了B+树,还有HASH和FUL-TEXT。
为什么使用B+树作为索引?
数据库的基本任务是增删改查,想要减少查找带来的时间,那么最好的结构就是树,将查找时间压缩到对数级别。而红黑树由于是二叉树,所以层数很容易过高,每一层都是一次IO操作,因此更为合适的树结构是B树。B+树在B树的基础上做了升级,非叶子节点不再储存实际数据,只储存索引,只有叶子节点才存放数据。叶子节点之间形成了一个有序链表。
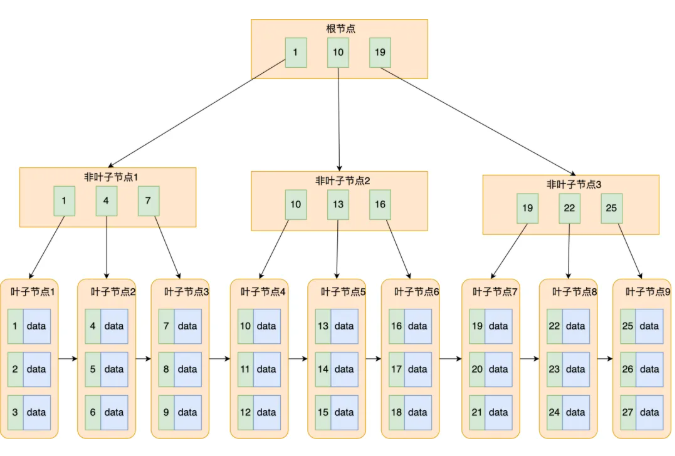
这样做的优势就是,当进行插入和删除操作时,只会从叶子节点删除,而不会像B树一样进行节点的分裂和融合。B+树叶子节点的链表使迭代器的访问更方便。
B+树可以有效减小层高,每一个节点的最大子节点树大于100,千万级别的数据只需要34层,也就是只需要34次的IO操作。
Hash表不适合做范围查询,进行一次Hash运算也是有时间成本的,因此B+树要更好。
聚簇索引和二级索引
两者的区别在于,主键索引的叶子节点存放的是完整的数据,而二级索引的叶子节点存放的是主键值。如果使用二级索引索引主键值,那么就不会再去主键索引进行二次索引,就叫做覆盖索引。
还有一个比较特殊的索引,联合索引,建议去小林coding看。
由二级索引页组成的B+树
二级索引段里一整个段就是一个B+树,不管是非叶子页还是叶子页都使用统一的页面结构,只是里面的记录不一样,区分就在于之间提到的记录头中的record_type属性,当值为1时就是一个目录项。
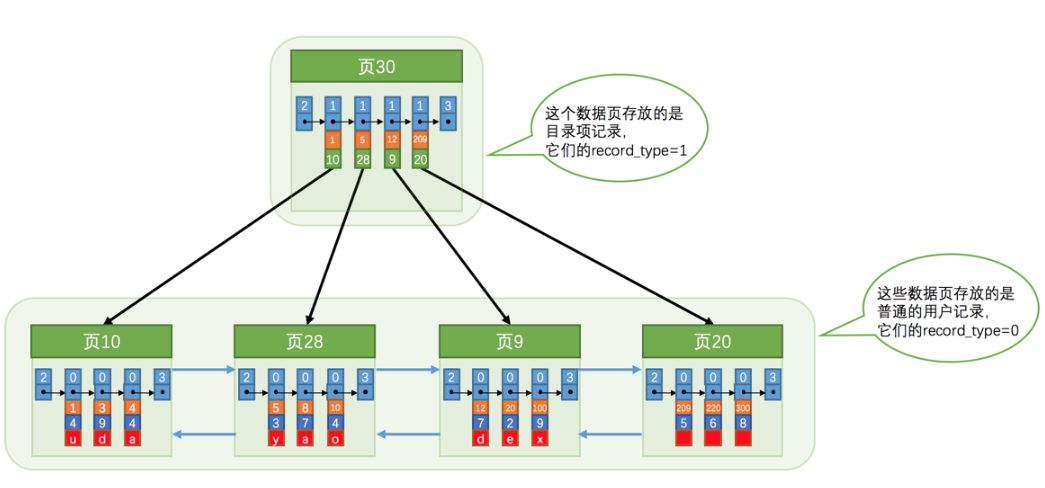
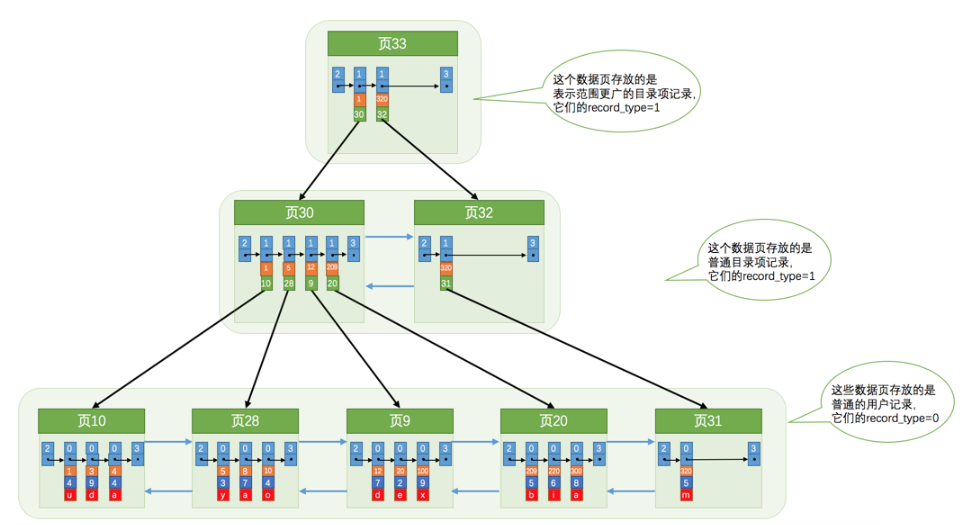
一次二次索引,就是根据我们索引属性的值,通过页的目录项二分查找定位到记录的位置,再通过记录位置找到其记录所在的下一个页,重复查找直到找到我们索引的数据的主码。
再根据主码,去聚簇索引所在的段中,进入第一个根页面进行查找。
参考资料
MySQL——InnoDB存储引擎的更多相关文章
- 浅析Mysql InnoDB存储引擎事务原理
浅析Mysql InnoDB存储引擎事务原理 大神:http://blog.csdn.net/tangkund3218/article/details/47904021
- MySQL InnoDB存储引擎体系架构 —— 索引高级
转载地址:https://mp.weixin.qq.com/s/HNnzAgUtBoDhhJpsA0fjKQ 世界上只两件东西能震撼人们的心灵:一件是我们心中崇高的道德标准:另一件是我们头顶上灿烂的星 ...
- MySQL InnoDB存储引擎
200 ? "200px" : this.width)!important;} --> 介绍 本篇文章是对Innodb存储引擎的概念进行一个整体的概括,innodb存储引擎的 ...
- mysql innodb存储引擎介绍
innodb存储引擎1.存储:数据目录.有配置参数为“ innodb_data_home_dir ” .“ innodb_data_file_path ” 和 “innodb_log_group_ho ...
- MySQL InnoDB存储引擎中的锁机制
1.隔离级别 Read Uncommited(RU):这种隔离级别下,事务间完全不隔离,会产生脏读,可以读取未提交的记录,实际情况下不会使用. Read Committed (RC):仅能读取到已提交 ...
- MySQL InnoDB存储引擎undo redo解析
本文介绍MySQL数据库InnoDB存储引擎重做日志漫游 00 – Undo Log Undo Log 为了实现事务原子,在MySQL数据库InnoDB存储引擎,还使用Undo Log(简称:MVCC ...
- MySQL InnoDB 存储引擎探秘
在MySQL中InnoDB属于存储引擎层,并以插件的形式集成在数据库中.从MySQL5.5.8开始,InnoDB成为其默认的存储引擎.InnoDB存储引擎支持事务.其设计目标主要是面向OLTP的应用, ...
- 设置mysql InnoDB存储引擎下取消自动提交事务
mysql 存储引擎中最长用的有两种,MyISAM 存储引擎和InnoDB存储引擎. 1.MyISAM 存储引擎 不支持事务,不支持外键,优势是访问速度快: 2.InnoDB存储引擎 支持事务,一般项 ...
- mysql innodb存储引擎和一些参数优化
mysql 的innodb存储引擎是事务性引擎,支持acid.innodb支持版本控制和高并发的技术是svcc:需要重点注意:myisam只缓存索引,innodb缓存索引和数据:
- MySQL Innodb 存储引擎学习篇
master thread的县城优先级别最高.其内部由几个循环(loop)组成:主循环(loop).后台循环(background loop).刷新循环(flush loop).暂停循环(suspen ...
随机推荐
- "油猴脚本""篡改猴"领域的一些基本常识
本文简要介绍本人对"油猴脚本","篡改猴"领域的一些见解,内容注定不可能一步到位和事无巨细,欢迎各位仁人志士对我批评指正,提出意见建议.另外转载前请务必注明作者 ...
- Cannot find one or more components.
场景重现 有那么一天重启了下电脑, 打开 Microsoft SQL Server Management Studio 2016, 没有出现腻歪的用户界面, 反而出现如下异常: 错误原因 谁造呢? 有 ...
- useDeferredValue的作用
前言 useDeferredValue是react18新增的一个用于优化性能的一个hook,它的作用是延迟获取一个值,实际开发中的常规用法与我们之前所用的防抖和节流很相似,但是也有一定的区别.本篇文章 ...
- Codeforces Round 971 (Div. 4)
C. The Legend of Freya the Frog 因为是从x开始跳,贪心的取肯定是直接用max(a,b)/d向上取整然后再乘2,但是要注意,如果再x到达之前,y已经是到达了,也就是某次以 ...
- mybatis报错Cause: java.lang.IllegalArgumentException: invalid comparison: java.util.ArrayList and java
原因 传入参数为List<String>不能用lists != '' 判断 解决 将lists != '' 的判断去掉或者改为lists .size>0 其他 如果是Integer类 ...
- AI 辅助开发实战分享:解决Selenium自动化设置Ant时间组件难题
AI 辅助开发实战分享:解决Selenium自动化设置Ant时间组件难题 在软件开发这一块,自动化那可是提高效率.少出错的关键.不过呢,在实际搞自动化开发的时候,开发者们常常会碰到各种各样的麻烦和障碍 ...
- Docker开启远程守护进程访问
默认情况下,Docker守护进程监听Unix套接字上的连接,以接受来自本地客户端的请求.通过将Docker配置为侦听IP地址和端口以及Unix套接字,可以允许Docker接受来自远程主机的请求.有关此 ...
- Java对象相等判断
你是谁啊?你是不是我??(⊙_⊙)? 我们知道比较对象相等可以使用equal方法(来自Object对象的方法) 但是你打开Object的equal方法你会发现: public boolean equa ...
- 【HUST】网安|编译原理|期末复习概念梳理笔记
纯自用,仅概念无题型,配合课本<编译原理 第4版>(ISBN: 978-7-121-31930-3)理解. 参考文献:刘铭. 编译原理 第4版. 北京:电子工业出版社, 2018.06. ...
- tcpdump工具
监视指定的网络接口/网卡 tcpdump -i eth100 通过网卡eth100监视主机的数据包 tcpdump -i eth100 host 190.160.35.11 截获本地发送到目标主机19 ...