LLM主要架构
LLM本身基于Transformer架构
自2017年,Attention is all you need诞生起,原始的Transformer模型不同领域的模型提供了灵感和启发
基于原始的Transformer框架,衍生了一系列模型,一些模型仅仅使用encode或decoder,有些模型同时使用encoder + decoder。
Transformer 模型图:
LLM 分类一般分为三种:自编码模型(Encoder)、**自回归模型(decoder) **和 序列到序列模型(Encoder-decoder)
自编码模型(AE, AutoEncoder model)
代表模型BERT
AE模型,代表作BERT,其特点为:Encoder-Only
基本原理:在输入中随机MASK掉一部分单词,更精上下文预测这个词
AE模型通常用于内容理解任务,比如自然语言理解(NLU)中的分类任务:情感分析、提取式问答
BERT 是2018年10月由Google AI研究院提出的一种预训练模型
- BERT全称为:Bidirectional Encoder Representation from Transformers
- BERT在机器阅读理解顶级水平测试SQuAD1.1 中表现出惊人的成绩:全部两个衡量标准上全面超越人类,并且在11种不同NLP测试中创出SOTA表现,包括将GLUE基准推高至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7%(绝对改进5.6%),称为NLP发展史上里程碑式的模型成就
BERT架构
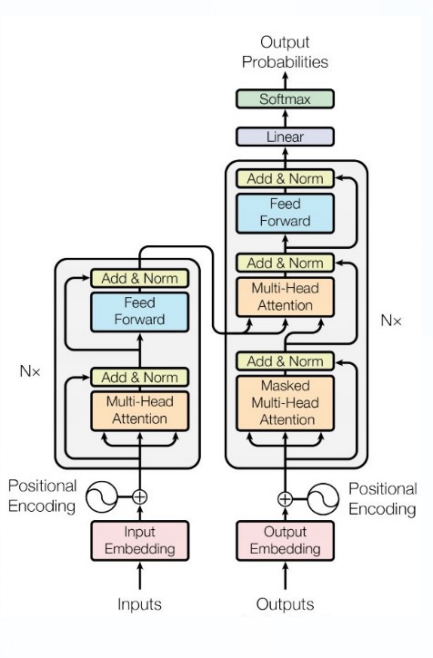
总体架构:如下图所示,最左边的就是BERT的架构图,一个典型的双向编码模型。
从上面的架构图中可以看到,宏观上BERT分为三个主要模块:
- 最底层黄色标记的Embedding模块
- 中间层蓝色标记的Transformer模块
- 最上层绿色标记的预微调模块
Embedding模块
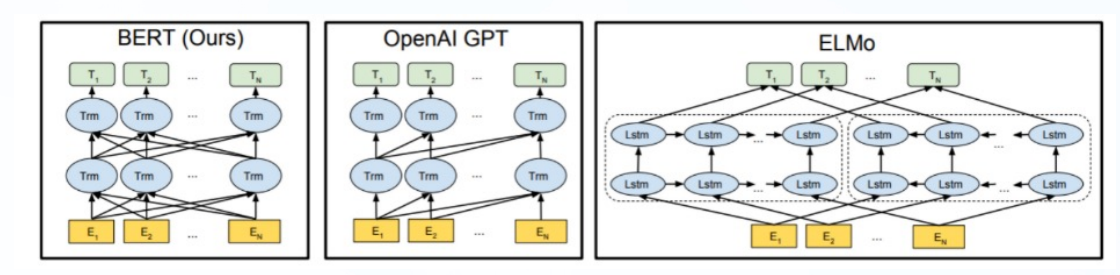
BERT中的该模块是由三种Embedding共同组成而成,如下图:
- Token Embeddings: 词嵌入向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embedding:句子分段嵌入张量,是为了服务后续的两个句子为输入的预训练任务
- Position Embedding: 位置编码张量
- 整个Embedding模块的输出张量就是这三个张量的直接加和结果
双向Transformer
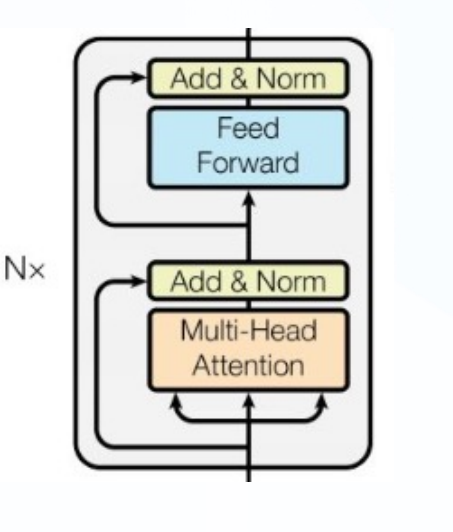
BERT中使用了经典Transformer结构中的Encoder部分,完全舍弃了Decoder部分
两大训练任务也集中体现在训练Transformer模块中
预微调模块
经过中间层Transformer的处理后,BERT的最后一层根据任务的不同需求而作不同的调整即可
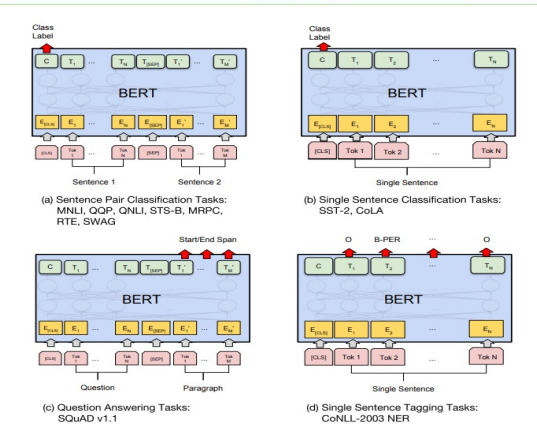
比如对于sequence-level的分类任务,BERT直接取第一个[CLS] token的final hidden state,再加一个层全连接层后进行softmax来预测最终的标签
BERT的预预测任务
Masked LM(带mask的语言模型训练),简称MLM
在原始训练文本中,随机的抽取15%的token作为参与MASK任务的对象
- 80%的概率下,用[MASK]标记替换该token
- 在10%的概率下,用一个随机的单词替换token
- 在10%的概率下,保持该token不变
Next Sentence Prediction(下一句话预测任务),简称NSP
输入句子对(A, B),模型来预测句子B是不是句子A的真实的下一句话。
- 所有参与任务训练的句子都被选中作为句子A
- 其中50%的B是原始文本中真实跟随A的下一句话(标记为IsNext,代表正样本)
- 其中50%的B是原始文本中随机抽取的一句话(标记为NotNext,代表负样本)
数据集与BERT模型的特点
数据集如下:
BooksCorpus (800M words) + English Wikipedia (2,500M words)
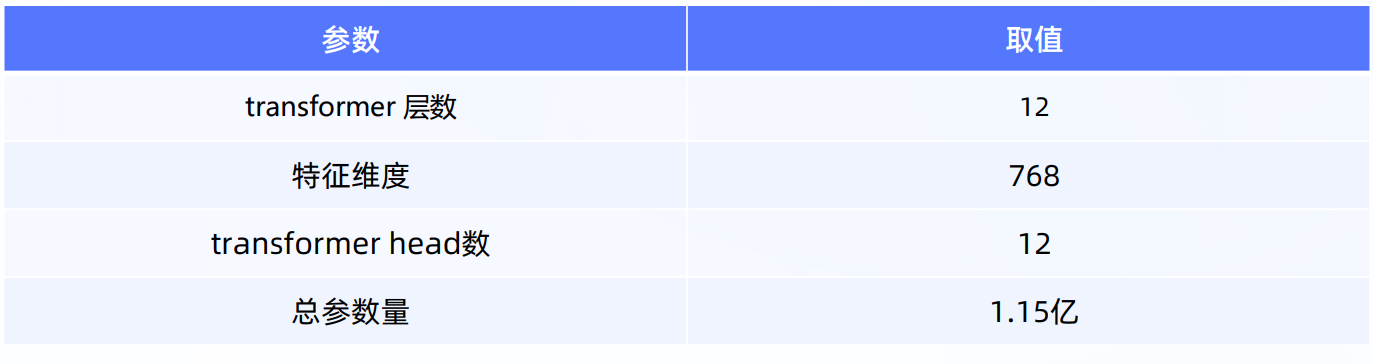
模型的一些关键参数为:
AE模型总结
- 优点
BERT使用双向Transformer,在语言理解相关的任务重表现很好
- 缺点
- 输入噪声:预训练-微调存在差异
- 更适合NLU(自然语言理解)任务,不适合用NLG(自然语言生成)任务
PS
什么是自编码?
答:在输入中随机MASK掉一部分单词,根据上下文预测找个词BERT模型的核心架构?
答:Transformer的Encoder模块BERT的预训练任务?
答:MLM和NSP
自回归模型(AR, AutoRegresive model)
代表模型GPT
AR模型,代表作GPT,其特点为:Decoder-Only
基本原理:从左往右学习的模型,只能利用上文或者下文的信息。
AR模型通常用于生成式任务,在长文本的生成能力很强,比如自然语言生成(NLG)领域的任务:摘要、翻译或抽象问答
2018年6月,OpenAI公司发表论文"Improving Language Understanding by Generative Pre-training"(用生成式预训练提高模型的语言理解力),推出了具有1.17亿个参数的GPT(Generative Pre-training,生成式预训练)模型
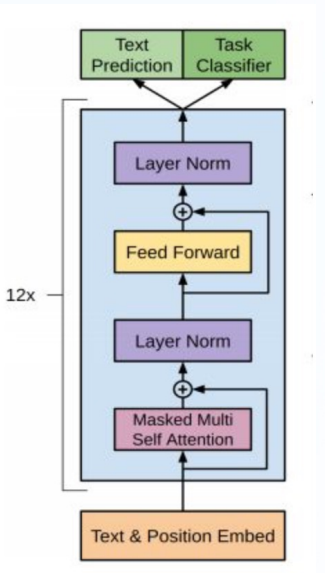
GPT模型架构
三个语言模型的对比架构图,中间为GPT
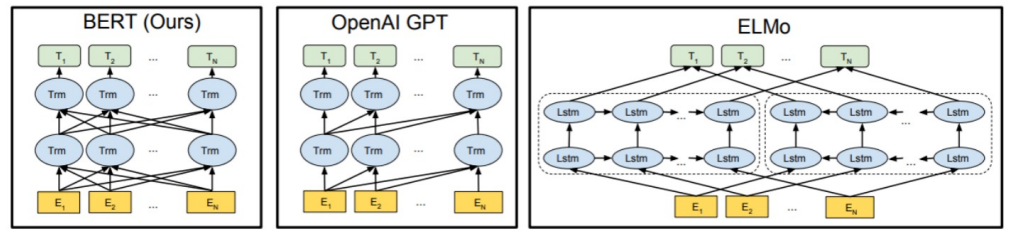
从上图可看到GPT采用的是 单向Transformer模型,例如给定一个句子\([u_1, u_2, ..., u_n]\) ,GPT在预测单词\(u_i\)的时候只会利用\([u_1, u_2, ...,u_{(i-1)}]\) 的信息,而BERT会同时利用上下文的信息\([u_1, u_2, ...,u_{(i-1)}, u_{i+1},...,u_n]\)
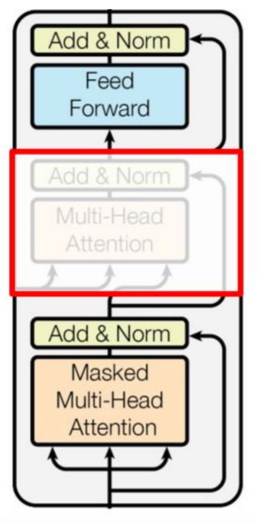
GPT采用了Transformer的Decoder模块,但GPT的Decoder Block和经典Transformer Decoder Block 有所不同
GPT中取消了第二个encoder-decoder attention子层,只保留Masked Multi-Head Attention层和Feed Forward层
PS:
注意:对比于经典的Transformer架构,解码器模块采用了6个Decoder Block;GPT的架构中采用了12个Decoder Block。
GPT训练过程
GPT的训练包括两个阶段过程:1.无监督的预训练语言模型;2.有监督的下游任务fine-tunning
无监督的预训练语言模型
- 给定句子\(U = [u_1, u_2, ..., u_n]\),GPT训练语言模型时的目标是最大化下面的似然函数:
\]
上述公式具体来说是要预测每个词\(u_i\)的概率,这个概率是基于它前面\(u_{i-k}\)到\(u_{i-1}\)个词,以及模型\(\Theta\),这里的k代表上文的窗口大小,理论上,k取的越大,模型所能获取的上文信息越充足,模型的能力越强。
GPT是一个单向语言模型,模型对输入U进行特征嵌入得到Transformer第一层的输入\(h_0\),再经过多层Transformer特征编码,使用最后一层的输出即可得到当前预测的概率分布,计算过程如下:
\]
$W_p$代表单词的位置编码,形状是[max_seq_len, embedding_dim],
$W_e$的形状为$[vocab\_size, embedding\_dim]$
- 得到输入张量\(h_0\)后,要将\(h_0\)传入GPT的Decoder Block中,依次得到\(h_t\):
\]
- 最后通过得到的\(h_t\)来预测下一个单词:
\]
有监督的下游任务fine-tunning
- GPT预训练后,会针对具体的下游任务队模型进行微调
微调采用的是 有监督学习,训练样本包括单词序列\([x_1, x_2, ..., x_n]\)和label y
GPT微调的目标任务:根据单词序列\([x_1, x_2, ..., x_n]\)预测标签y
\]
其中,\(W_y\)表示预测输出的矩阵参数,微调任务的目标是最大化下面的函数:
\]
综合两个阶段的目标任务函数,可知GPT的最终优化函数为:
\]
整体训练过程架构图
根据下游任务适配的过程分两步:
- 根据任务定义不同输入
- 对不同任务增加不同的分类层
具体定义可以参见下图:
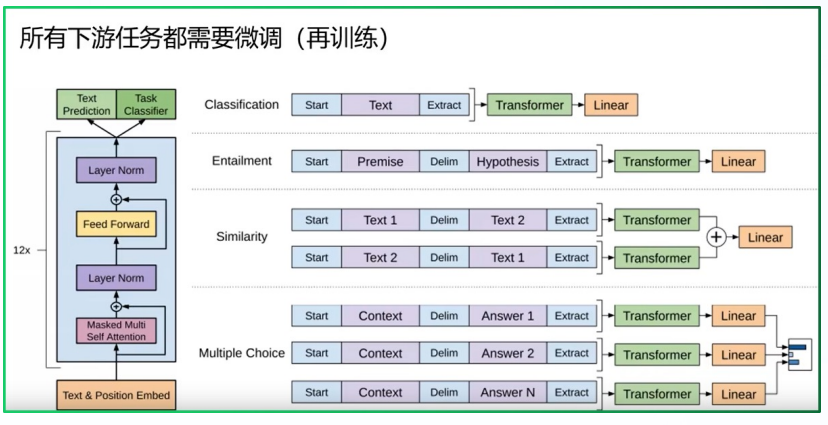
- 对不同任务增加不同的分类层
GTP数据集
GPT使用了BooksCorpus数据集,文本大小约5GB,包含7400W+的句子。这个数据集由7000本独立的、不同风格类型的书籍组成,选择该部分数据集的原因:
- 书籍文本包含大量高质量长句,保证模型学习长距离信息依赖
- 书籍未开源公布,所以很难在下游数据集上见到,更能体验模型的泛化能力
GPT模型的特点
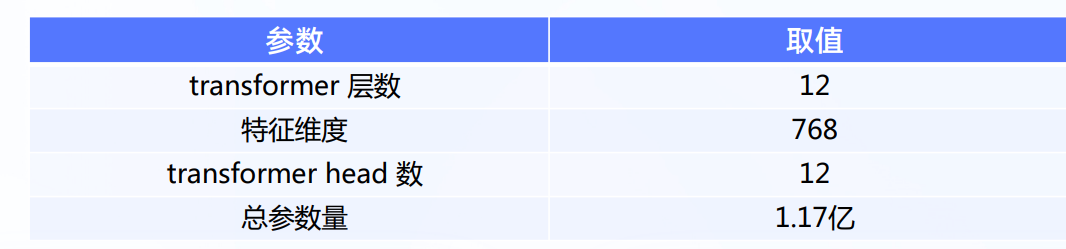
模型的一些关键参数为:
优点
- GPT在9个任务上的表现sota
- 更易于并行化
缺点
- GPT语言模型是单向的
- 针对不同的任务,需要不同数据集进行模型微调,相对比较麻烦
PS
什么是自回归模型?
答:从左往右学习的模型,只能利用上文或下文的信息GPT模型的核心架构?
答:transformer 的Decoder模块(去除中间的第二个子层)GPT的预训练任务?
答:无监督的预训练 和 有监督任务的微调
序列到序列模型(Sequence to Sequence Model)
代表模型T5
encoder-decoder模型同时使用编码器和解码器,它将每个task视作序列到序列的转换/生成(比如,文本到文本,文本到图像或图像到文本的多模态任务)。Encoder-decoder模型通常用于需要内容理解和生成的任务如机器翻译
T5由谷歌提出,该模型的目的是构建任务统一框架:将所有NLP任务都视为文本转换任务
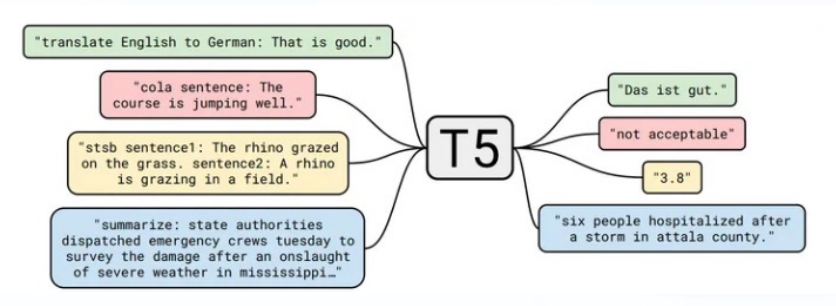
通过这样的方式就能将NLP任务转换为Text-to-Text形式,也就可以用同样的模型,同样的损失函数,同样的训练过程,同样的解码过程来完成所有NLP任务。
T5模型架构与训练过程
T5模型结构与原始的Transformer基本一致,除了做了以下几点改动:
采用了简化版的Layer Normalization,去除了Layer Norm的bias;将Layer Norm放在残差连接外面
位置编码:T5使用了一种简化版的相对位置编码,即每个位置编码都是一个标量,被加在logits上用于计算注意力权重。各层共享位置编码,但是在同一层内,不同的注意力头的位置编码都是独立学习的。
自监督预训练
采用类似于Bert模型的MLM预训练任务
多任务预训练
除了使用大规模数据进行无监督预训练,T5模型还可以利用任务的标注数据进行有监督的多任务预训练,例如SQuAD问答和机器翻译等任务
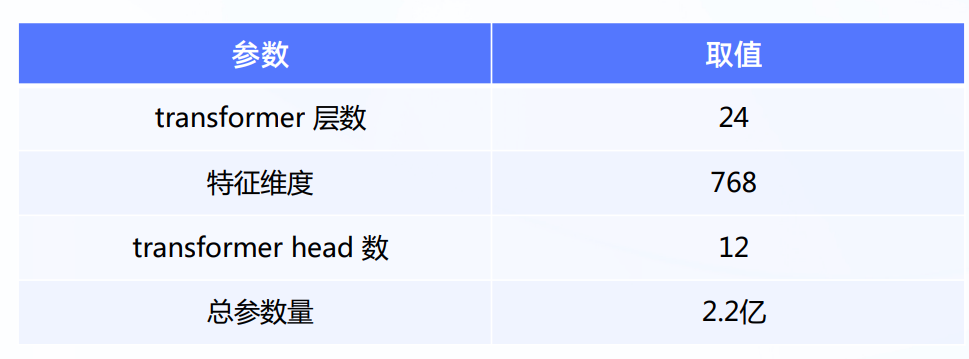
T5数据集与模型的特点
- T5 数据集
作者对公开爬取的页面数据集Common Crawl进行过滤,去掉一些重复的、低质量的、看起来像代码的文本等,并且最后只保留英文文本,得到数据集 C4:the Colossal Clean Crawled Corpus - 模型的一些关键参数:
PS
什么是序列到序列模型?
答:同时使用编码器和解码器,它将每个task视作序列到序列的转换/生成T5模型的核心架构?
答: TransformerT5的预训练任务?
答: 采用类似于Bert模型的MLM预训练任务和多任务预训练
LLM主要架构的更多相关文章
- MySQL高级知识- MySQL的架构介绍
[TOC] 1.MySQL 简介 概述 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,目前属于Oracle公司. MySQL是一种关联数据库管理系统,将数据保存在不同的表中,而 ...
- node服务的监控预警系统架构
需求背景 目前node端的服务逐渐成熟,在不少公司内部也开始承担业务处理或者视图渲染工作.不同于个人开发的简单服务器,企业级的node服务要求更为苛刻: 高稳定性.高可靠性.鲁棒性以及直观的监控和报警 ...
- 如何一步一步用DDD设计一个电商网站(二)—— 项目架构
阅读目录 前言 六边形架构 终于开始建项目了 DDD中的3个臭皮匠 CQRS(Command Query Responsibility Segregation) 结语 一.前言 上一篇我们讲了DDD的 ...
- 浅谈 jQuery 核心架构设计
jQuery对于大家而言并不陌生,因此关于它是什么以及它的作用,在这里我就不多言了,而本篇文章的目的是想通过对源码简单的分析来讨论 jQuery 的核心架构设计,以及jQuery 是如何利用javas ...
- 【深入浅出jQuery】源码浅析--整体架构
最近一直在研读 jQuery 源码,初看源码一头雾水毫无头绪,真正静下心来细看写的真是精妙,让你感叹代码之美. 其结构明晰,高内聚.低耦合,兼具优秀的性能与便利的扩展性,在浏览器的兼容性(功能缺陷.渐 ...
- DDD CQRS架构和传统架构的优缺点比较
明天就是大年三十了,今天在家有空,想集中整理一下CQRS架构的特点以及相比传统架构的优缺点分析.先提前祝大家猴年新春快乐.万事如意.身体健康! 最近几年,在DDD的领域,我们经常会看到CQRS架构的概 ...
- Microservice架构模式简介
在2014年,Sam Newman,Martin Fowler在ThoughtWorks的一位同事,出版了一本新书<Building Microservices>.该书描述了如何按照Mic ...
- 谈一下关于CQRS架构如何实现高性能
CQRS架构简介 前不久,看到博客园一位园友写了一篇文章,其中的观点是,要想高性能,需要尽量:避开网络开销(IO),避开海量数据,避开资源争夺.对于这3点,我觉得很有道理.所以也想谈一下,CQRS架构 ...
- Windows平台分布式架构实践 - 负载均衡
概述 最近.NET的世界开始闹腾了,微软官方终于加入到了对.NET跨平台的支持,并且在不久的将来,我们在VS里面写的代码可能就可以通过Mono直接在Linux和Mac上运行.那么大家(开发者和企业)为 ...
- 架构设计:远程调用服务架构设计及zookeeper技术详解(下篇)
一.下篇开头的废话 终于开写下篇了,这也是我写远程调用框架的第三篇文章,前两篇都被博客园作为[编辑推荐]的文章,很兴奋哦,嘿嘿~~~~,本人是个很臭美的人,一定得要截图为证: 今天是2014年的第一天 ...
随机推荐
- 朋友说喊搞个简单的微信对接的封装搞外包,不要那么多的方法拿来就用的的那种,来看看Simple.Wechat吧
不知道大家有没有和我朋友一样,很多时候做外包总免不了去对接微信,最简单的微信用户信息获取.微信支付.微信模板消息发送,要是不熟悉总是要去找这个那个的包,但是人家的包封装的又丰富,又不想去看,本文将给大 ...
- HTTP - [01] 简介
HTTP本身是不安全的,因为传输的数据未经加密,可能会被窃听或篡改.为了解决这个问题,引入了HTTPS,即在HTTP上加入SSL/TLS协议,为数据传输提供了加密和身份验证. 一.概述 HTTP( ...
- Spark - 面试题
Spark是什么?答案:Apache Spark是一个快速.通用的大数据处理引擎,它提供了大规模数据集的内存计算和分布式计算能力.Spark可以处理各种数据源,如HDFS.Hive.Cassandra ...
- C# WebClient调用WebService
WebClient调用WebService (文末下载完整代码) 先上代码: object[] inObjects = new[] { "14630, 14631" }; Http ...
- SQL注入之WAF绕过注入
绕过WAF: WAF防御原理: 简单来说waf就是解析http请求,检测http请求中的参数是否存在恶意的攻击行为,如果请求中的参数和waf中的规则库所匹配,那么waf则判断此条请求为攻击行为并进行阻 ...
- 解决Mac M芯片 Wireshark 运行rvictl -s 后,出现Starting device failed
前言 mac os big sur 之后,苹果系统的安全性能提升,导致 rvictl -s 创建虚拟网卡失败. $ rvictl -s 000348120-001621w21184C01E boots ...
- 手把手教你安装TrueNas(基础篇)
玩过蜗牛星际,体验过黑群晖系统崩掉导致里面珍藏12t大姐姐全没了(此处有哭声),我技术又菜,自己恢复是不可能恢复的,装的盗版系统,又不可能联系群晖官方售后恢复.于是乎就想要一个稳定.开 ...
- UNIX 系统
UNIX 系统的历史,UNIX 是操作系统的开山鼻祖,是操作系统的发源地,后来的 Windows 和 Linux 都参考了 UNIX. 有人说,这个世界上只有两种操作系统: UNIX 和类 UNIX ...
- Delphi 中拖动无边框窗口的5种方法
1.MouseMove事件中加入: // ReleaseCapture; // Perform(WM_SYSCOMMAND, $F017 , 0); 2.MouseDown事件中加入: // POST ...
- Open R1 项目进展第一期
DeepSeek R1 发布已经两周了,而我们启动 open-r1 项目--试图补齐它缺失的训练流程和合成数据--也才过了一周.这篇文章简单聊聊: Open-R1 在模仿 DeepSeek-R1 流程 ...