CUDA编程学习 (2)——CUDA并行性模型
1. 基于 kernel 的 SPMD 并行编程
1.1 向量加法 kernel(device 代码)
// Device Code
// Compute vector sum C = A + B
// 每个 thread 执行一次成对加法
__global__ void vecAddKernel(float* A, float* B, float* C, int n)
{
int i = threadIdx.x + blockDim.x * blockIdx.x;
if(i < n) C[i] = A[i] + B[i];
}
1.2 向量加法 kernel lauch(host 代码)
// Host Code
void vecAdd(float* h_A, float* h_B, float* h_C, int n)
{
// 省略了 d_A、d_B、d_C 的 allocate 和 copy
// 运行 ceil(n/256.0) blocks,每个 block 包含 256 个 thread
// ceil 函数可确保有足够的 thread 覆盖所有元素
vecAddKernel<<<ceil(n/256.0), 256>>>(d_A, d_B, d_C, n);
}
表达 ceil 函数的等效方法:
// Host Code
void vecAdd(float* h_A, float* h_B, float* h_C, int n)
{
dim3 DimGrid((n-1)/256 + 1, 1, 1);
dim3 DimBlock(256, 1, 1);
vecAddKernel<<<DimGrid, DimBlock>>>(d_A, d_B, d_C, n);
}
1.3 CUDA 函数声明
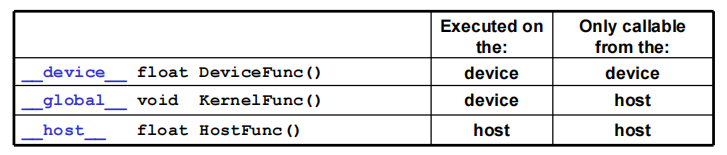
__device__:- 在 device 执行,仅从 device 调用
- 可以和
__host__同时调用,不可以和__global__同时调用
__global__:- 在 device 上执行,从 host 中调用(一些特定的 GPU 也可以从 device 上调用)
- 内核函数必须返回
void,不支持可变参数,不能成为类成员函数 - 注意用
__global__定义的 kernel 是异步的,这意味着 host 不会等待 kernel 执行完就执行下一步
__host__:- 在 host 上执行,仅从 host 上调用,一般省略不写
- 可以和
__device__,不可以和__global__同时调用,此时函数会在 device 和 host 都编译。
2. 多维 kernel 配置
2.1 多维 grid
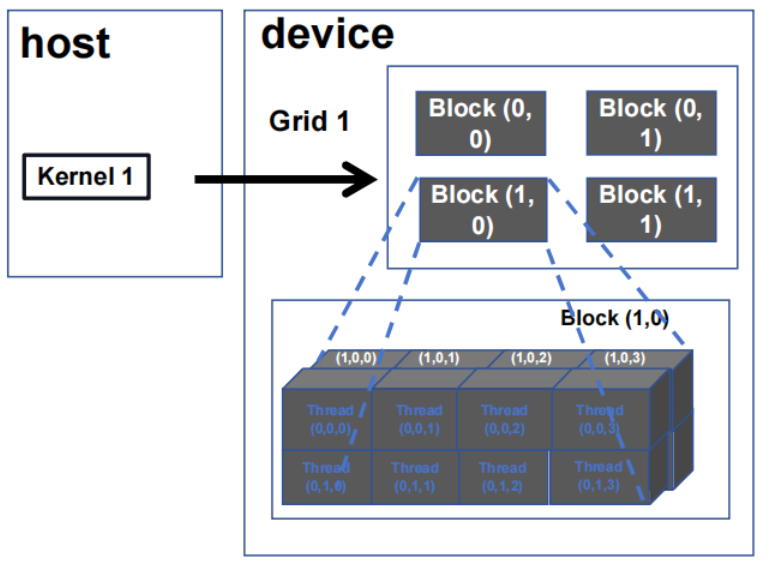
2.2 使用二维网格处理图片

在 GPU 计算中,图像被划分为多个小块,每个小块由一个 block 进行处理。每个 block 内部包含多个 thread,这些 thread 协同工作以并行处理图像数据。
2.3 C/C++ 中的行优先布局
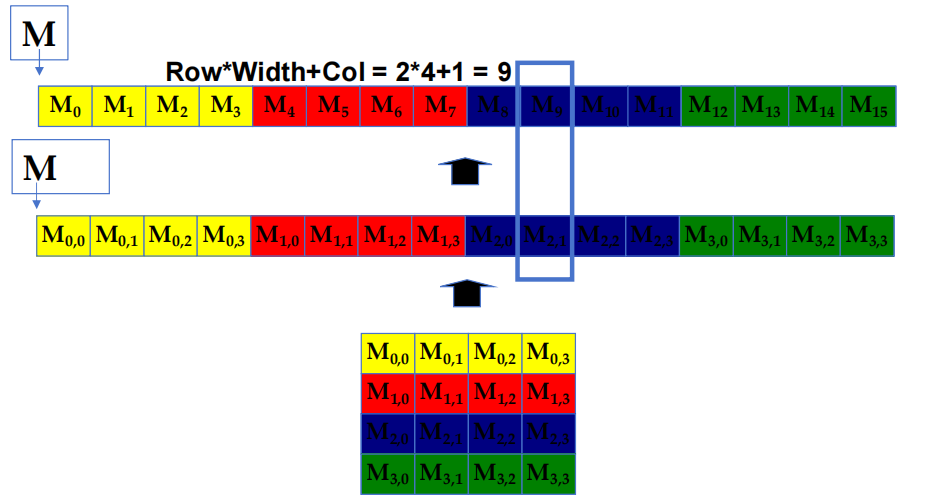
在这种布局中,矩阵中的元素按行顺序连续存储在内存中。具体来说,所有行的元素依次排列在一维的内存空间中。
例如,对于一个 4x4 的矩阵,元素 \(M_{0,0}, M_{0,1}, M_{0,2}, M_{0,3}\) 按顺序首先存储,然后是 \(M_{1,0}, M_{1,1}, M_{1,2}, M_{1,3}\),依此类推。公式 Row * Width + Col 用于计算矩阵中每个元素在一维内存数组中的线性位置。例如图中标注的元素 \(M_{2,1}\) 的位置通过公式 \(2∗4+1=9\) 计算得到。
2.4 PictureKernel 源代码
__global__ void PictureKernel(float* d_Pin, float* d_Pout, int height, int width)
{
// 计算 d_Pin 和 d_Pout 元素的 row
int Row = blockIdx.y * blockDim.y + threadIdx.y;
// 计算 d_Pin 和 d_Pout 元素的 column
int Col = blockIdx.x * blockDim.x + threadIdx.x;
// 如果在范围内,每个 thread 计算 d_Pout 的一个元素
if((Row < height) && (Col < width)){
d_Pout[Row * width + Col] = 2.0 * d_Pin[Row * width + Col]; // 将每个 pixel 值缩放 2.0
}
}
2.5 Launch PictureKernel 的 host 代码
// 假设图片大小为 m × n
// y 维度上有 m 个 pixel,x 维度上有 n 个 pixel
// 输入 d_Pin 已被 allocate 并 copy 到 device
// 输出 d_Pout 已被 allocate 到 device
dim3 DimGrid((n-1)/16 + 1, (m-1)/16 + 1, 1);
dim3 DimBlock(16, 16, 1);
PictureKernel<<<DimGrid, DimBlock>>>(d_Pin, d_Pout, m, n);
2.6 用 16×16 block 覆盖 62×76 大小的图片
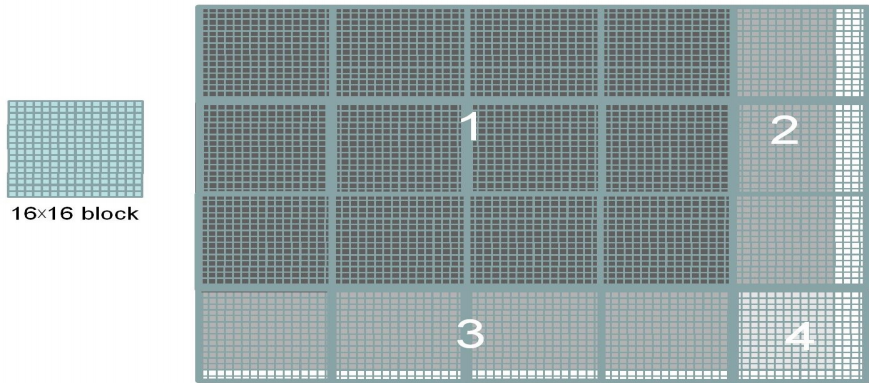
block 中并非所有 thread 都遵循相同的控制流路径。
3. 彩色-灰度图像处理示例
3.1 RGB 转换为灰度

灰度数字图像是指每个 pixel 的值只包含强度信息的图像。
- 对 \((I,J)\) 处的每个 pixel \((r,g,b)\) 进行处理:
\]
- 这只是一个点积 \(<[r,g,b],[0.21,0.71,0.07]>\),常数与输入的 RGB 空间有关。
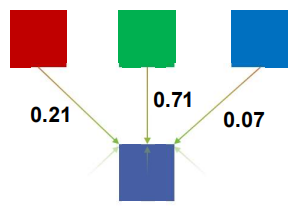
3.2 RGB 转灰度代码
# define CHANNELS 3 // 我们有 3 个与 RGB 相对应的通道
// 输入图像以无符号字符 [0, 255] 编码
__global__ void colorConvert(unsigned char* grayImage, unsigned char* rgbImage, int width, int height)
{
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
if(x < width && y < height){
// 获取灰度图像的 1D 坐标
int grayOffeset = y * width + x;
// 可以认为 RGB 图像的 columns 是灰度图像的 CHANNEL 倍
int rgbOffset = grayOffset * CHANNELS;
unsigned char r = rgbImage[rgbOffset]; // red value for pixel
unsigned char g = rgbImage[rgbOffset + 1]; // green value for pixel
unsigned char b = rgbImage[rgbOffset + 2]; // blue value for pixel
// 进行重新缩放并存储
// 我们用浮点常量进行乘法运算
grayImage[grayOffset] = 0.21f*r + 0.71f*g + 0.07f*b;
}
}
4. 图像模糊示例
4.1 图像模糊

- 模糊块(Blurring Box)

4.2 作为 2D Kernel 的图像模糊代码
__global__ void blurKernel(unsigned char* in, unsigned char* out, int w, int h)
{
int Col = blockIdx.x * blockDim.x + threadIdx.x;
int Row = blockIdx.y * blockDim.y + threadIdx.y;
if(Col < w && Row < h){
int pixVal = 0;
int pixels = 0;
// 获取周围 2xBLUR_SIZE x 2xBLUR_SIZE 方框的平均值
for(int blurRow = -BLUR_SIZE; blurRow < BLUR_SIZE+1; ++blurRow){
for(int blurCol = -BLUR_SIZE; blurCol < BLUR_SIZE+1; ++blurCol){
int curRow = Row + blurRow;
int curCol = Col + blurCol;
// 验证图像像素是否有效
if(curRow > -1 && curRow < h && curCol > -1 && curCol < w){
pixVal += in[curRow * w + curCol];
pixels++; // 跟踪累计总数中的像素数
}
}
}
// 写出新的 pixel 值
out[Row * w + Col] = (unsigned char)(pixVal / pixels);
}
}
5. 线程调度(Thread Scheduling)
5.1 透明扩展性(Transparent Scalability)
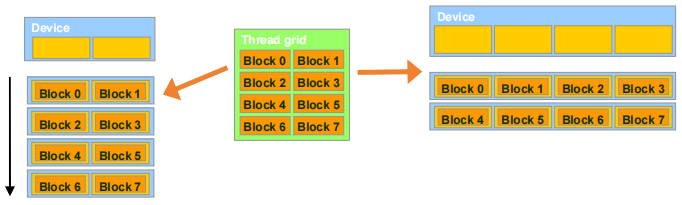
- block 是 GPU 的工作单元,它们可以在任何顺序下执行,彼此之间没有执行依赖关系。
- 硬件可随时自由地将 block 分配给任何处理器
- 一个 CUDA kernel 可以在任意数量的并行处理器上扩展,无论处理器数量如何,Block的分配是动态的
5.2 示例:执行 thread block
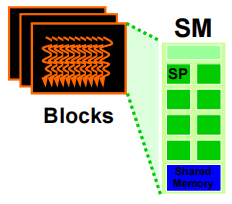
thread 按 block 粒度分配给流式多处理器(SM,Streaming Multiprocessors)
- 在资源允许的情况下,每个 SM 最多可连接 32 个 block
- Volta SM 最多可使用 2048 个 thread
- 可能是 \(256\ (threads/block)\ *\ 8\ blocks\)
- 或 \(512\ (threads/block)\ *\ 4\ blocks\) 等
SM 维护 thread / block idx #s:每个SM都会跟踪它所管理的线程和线程块索引,以便于调度和管理。
SM 管理和调度 thread 执行
5.3 作为调度单位的 Warp
- 每个 block 以 32-thread Warp 执行(每个 warp 包含 32 个线程)
- 实施决策,而非 CUDA 编程模型的一部分
- Warp 是 SM 中的调度单位
- Warp 中的 thread 以 SIMD 方式执行
- 未来的 GPU 可能会在每个 warp 中使用不同数量的 thread
5.3.1 Warp 示例
- 如果一个 SM 有 3 个 block,每个区块有 256 个 thread,那么一个 SM 有多少个 Warp?
- 每个 block 分为 \(256/32 = 8\) 个 Warp
- 共有 \(8 * 3 = 24\) 个 Warp
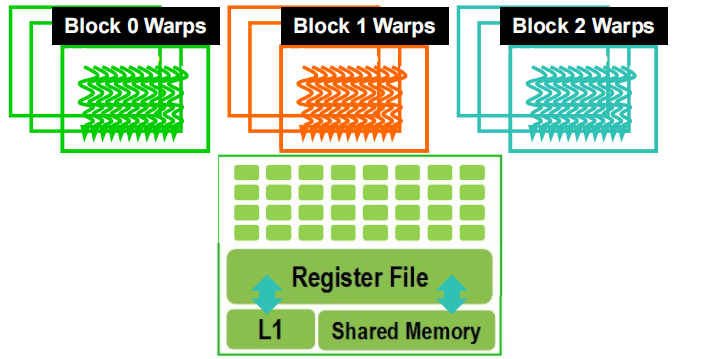
5.4 线程调度
- SM 实现零开销 Warp 调度
- 下一条指令的操作数已准备就绪的 Warp 可执行(如果数据未准备好(例如由于内存延迟),该 warp 将会停滞,SM 会调度另一个 warp 执行)
- 符合条件的 warp 会根据优先调度策略被选择执行
- 当一个 warp 被选中执行时,warp 内的所有线程执行相同的指令(这是因为 GPU 采用 SIMT(单指令多线程) 模型,虽然每个线程处理的数据可能不同,但它们共享相同的指令流,使得并行执行更加高效。)
5.5 block 粒度考虑因素
- 对于使用多个 block 进行矩阵乘法运算的 Volta,每个 block 应该有 \(4*4\)、\(8*8\) 还是 \(30*30\) 个 thread?
- 对于 \(4*4\),每个 block 有 16 个 thread。每个 SM 最多可容纳 2048 个 thread,也就是 128 个 block。然而,每个 SM 最多只能容纳 32 个 block,因此每个 SM 只能容纳 512 个 thread!
- 对于 \(8*8\),每个 block 有 64 个 thread。由于每个 SM 最多可容纳 2048 个 thread,因此它最多可容纳 32 个 block 并实现满负荷运行,除非有其他资源方面的考虑因素。
- 对于 \(30*30\),每个 block 将有 900 个 thread。对于 Volta 来说,一个 SM 只能容纳 2 个 block,因此只能使用 \(1800/2048\) 个 SM thread 容量。
参考文献
[1] CUDA编程入门极简教程 - 知乎 (zhihu.com)
CUDA编程学习 (2)——CUDA并行性模型的更多相关文章
- CUDA编程学习笔记1
CUDA编程模型是一个异构模型,需要CPU和GPU协同工作. host和device host和device是两个重要的概念 host指代CPU及其内存 device指代GPU及其内存 __globa ...
- CUDA编程学习相关
1. CUDA编程之快速入门:https://www.cnblogs.com/skyfsm/p/9673960.html 2. CUDA编程入门极简教程:https://blog.csdn.net/x ...
- CUDA编程学习(一)
/****c code****/ #include<stdio.h> int main() { printf("Hello world!\n); ; } /****CUDA co ...
- cuda编程学习6——点积dot
__shared__ float cache[threadPerBlock];//声明共享内存缓冲区,__shared__ __syncthreads();//对线程块中的线程进行同步,只有都完成前面 ...
- cuda编程学习5——波纹ripple
/共有DIM×DIM个像素,每个像素对应一个线程dim3 blocks(DIM/16,DIM/16);//2维dim3 threads(16,16);//2维kernel<<<blo ...
- cuda编程学习4——Julia
书上的例子编译会有错误,修改一下行即可. __device__ cuComplex(float a,float b):r(a),i(b){} /* ========================== ...
- cuda编程学习3——VectorSum
这个程序是把两个向量相加 add<<<N,1>>>(dev_a,dev_b,dev_c);//<N,1>,第一个参数N代表block的数量,第二个参数1 ...
- cuda编程学习2——add
cudaMalloc()分配的指针有使用限制,设备指针的使用限制总结如下: 1.可以将其传递给在设备上执行的函数 2.可以在设备代码中使用其进行内存的读写操作 3.可以将其传递给在主机上执行的函数 4 ...
- cuda编程学习1——hello world!
将c程序最简单的hello world用cuda编写在GPU上执行,以下为代码: #include<iostream>using namespace std;__global__ void ...
- CUDA编程学习笔记2
第二章 cuda代码写在.cu/.cuh里面 cuda 7.0 / 9.0开始,NVCC就支持c++11 / 14里面绝大部分的语言特性了. Dim3 __host__ __device__ dim3 ...
随机推荐
- Visual Studio C++ 安装以及使用教程
官网下载网址 https://visualstudio.microsoft.com/zh-hans/ Visual Studio: 面向软件开发人员和 Teams 的 IDE 和代码编辑器 (micr ...
- Linux-mknod命令
mknod 创建块设备或者字符设备文件.此命令的适用范围:RedHat.RHEL.Ubuntu.CentOS.SUSE.openSUSE.Fedora. 用法: mknod [选项]... 名称 类型 ...
- SpringBoot静态文件映射问题
如果遇到这种情况,检查静态文件(js/css/img)是不是在默认的static路径下,在查看application配置中的 static-path-pattern: 是否和前端映射路径完全相同,要是 ...
- Java 1.8 Stream流原理与用法总结
一.接口设计 从Java1.8开始提出了Stream流的概念,侧重对于源数据计算能力的封装,并且支持序列与并行两种操作方式:依旧先看核心接口的设计: BaseStream:基础接口,声明了流管理的核心 ...
- hashmap组成原理及调用时机
整个HashMap中最重要的点有四个:初始化,数据寻址-hash方法,数据存储-put方法,扩容-resize方法,只要理解了这四个点的原理和调用时机,也就理解了整个HashMap的设计. 如果有疑惑 ...
- 8.4linux定时任务-环境变量-数据库
配合SUID本地环境变量提权 思路原理:利用sh环境变量替换,使得/tmp/ps得到root权限:ps=sh 过程:手写调用文件-编译-复制文件-增加环境变量-执行 gcc demon1.c -o s ...
- C++17: 用折叠表达式实现一个IsAllTrue函数
前言 让我们实现一个 IsAllTrue 函数,支持变长参数,可传入多个表达式,必须全部计算为true,该函数才返回true. 本文记录了逐步实现与优化该函数的思维链,用到了以下现代C++新特性知识, ...
- ECMA Script6 中的 尾调用优化
在读 <深入理解ES6>一书中,看到有关函数的 "尾调用优化" 章节,特此记录一下 尾调用 指的是 函数作为另一个函数的最后一条语句被调用: function foo ...
- CSS – Transform
前言 之前写的 W3Schools 学习笔记 (3) – CSS 2D Transforms. 这篇作为整理. 参考: Youtube – Learn CSS Transform In 15 Minu ...
- Azure 学习笔记
选择 VM 配套 https://docs.azure.cn/zh-cn/virtual-machines/sizes https://docs.azure.cn/zh-cn/virtual-mac ...