STL查找序列中处于某一大小范围内的元素个数

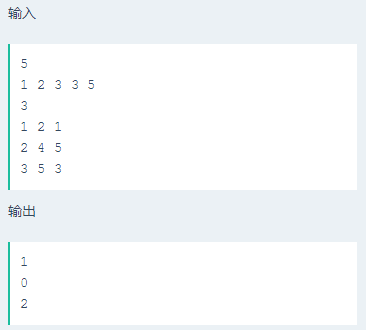
还是头条的笔试题(咦?),问题最后转换成这样的形式:
输入:不包含重复元素的有序数组a[N]以及上下界low, high;
输出:数组a[N]中满足元素处于闭区间[low,high]内(即low <= a[i] <= high)的元素个数
二分查找一向的特点,原理上非常好理解,但是判断边界的时候则是十分头疼。
这里我一开始都用lower_bound来查找low和high,返回两个位置it1,it2,然后计算初始数量cnt = it2 - it1 + 1;(因为是闭区间所以加1),然后再判断it1、it2找到的到底是low和high本身还是比它们大的数。
实际上不必这么麻烦,直接用lower_bound查找low,upper_bound查找high就行。
再回顾这两个函数:lower_bound返回的是第一个大于或等于查找值的迭代器,upper_bound返回的是第一个大于查找值的迭代器。
举个例子:int a[4] = { 3, 5, 7, 9 };分4种典型情况考虑
1、low=4,high=6。结果为1(元素5)。lower_bound(4)返回的是5的位置&a[1],upper_bound(6)返回的是7的位置&a[2],数量为2-1=1,无误;
2、low=4,high=7。结果为2(元素5、7)。lower_bound(4)返回的是5的位置&a[1],upper_bound(7)返回的是9的位置&a[3],数量为3-1=2,无误;
3、low=5,high=6。结果为1(元素5)。lower_bound(5)返回的是5的位置&a[1],upper_bound(6)返回的是7的位置&a[2],数量为2-1=1,无误;
4、low=5,high=7。结果为2(元素5、7)。lower_bound(5)返回的是5的位置&a[1],upper_bound(7)返回的是9的位置&a[3],数量为3-1=2,无误;
在此之上进行推广,假如low,high组成的不是闭区间,计算方法如下

至于笔试题的解法,代码如下:
#include <iostream>
#include <vector>
#include <unordered_map>
#include <algorithm>
using namespace std; int main()
{
// 输入
int n;
cin >> n;
vector<int> val(n);
for (int i = ; i < n; i++)
{
cin >> val[i];
}
int q;
cin >> q;
// 构建hash表, key为以1开始的数组下标
unordered_map<int, vector<int>> m;
for (int i = ; i < n; i++)
{
if (m.count(val[i]) == )
{
m.emplace(val[i], vector<int>{ i + });
}
else
{
m[val[i]].emplace_back(i + );
}
}
// 读取q组{l,r,k}, 输出m[k]中在区间[l,r]内的元素个数
vector<int> l(q);
vector<int> r(q);
vector<int> k(q);
for (int i = ; i < q; i++)
{
cin >> l[i] >> r[i] >> k[i];
}
vector<int> res(q);
for (int i = ; i < q; i++)
{
int ll = l[i];
int rr = r[i];
int kk = k[i];
if (m.count(kk) == ) // 喜好度为k的用户个数为0
{
res[i] = ;
}
else
{
int cnt = ;
auto it1 = lower_bound(m[kk].begin(), m[kk].end(), ll);
auto it2 = upper_bound(m[kk].begin(), m[kk].end(), rr);
res[i] = it2 - it1;
}
}
// 输出结果
for (int x : res)
cout << x << endl;
}
STL查找序列中处于某一大小范围内的元素个数的更多相关文章
- 1、如何在列表,字典,集合种根据条件筛选数据?2、如何为元组中的每个元素命名,提高程序的可读性3、如何统计出序列中元素出现的频度4、如何根据字典中value的大小,对字典的key进行排序
一.数据筛选: 处理方式: 1.filter函数在py3,返回的是个生成式. from random import randint data = [randint(-100,100) for i in ...
- STL之序列容器vector
首先来看看vector的模板声明: template <class T, class Alloc = allocator<T>> class vector { //… }; v ...
- stl 在 acm中的应用总结
总结一些在acm中常用的小技巧,小函数 之前尝试着总结过很多次.都失败了,因为总是担心不全,理解的也不是很透彻.这次再来一次...其实之前保存了很多的草稿就不发布了,当然,下面说的很不全面,路过的大牛 ...
- Deep-Learning-with-Python] 文本序列中的深度学习
https://blog.csdn.net/LSG_Down/article/details/81327072 将文本数据处理成有用的数据表示 循环神经网络 使用1D卷积处理序列数据 深度学习模型可以 ...
- JS数组常用函数以及查找数组中是否有重复元素的三种常用方法
阅读目录: DS01:常用的查找数组中是否有重复元素的三种方法 DS02:常用的JS函数集锦 DS01.常用的查找数组中是否有重复元素的三种方法 1. var ary = new Array(&qu ...
- 17082 两个有序数序列中找第k小
17082 两个有序数序列中找第k小 时间限制:1000MS 内存限制:65535K 提交次数:0 通过次数:0 题型: 编程题 语言: 无限制 Description 已知两个已经排好序(非减 ...
- 如何查找MySQL中查询慢的SQL语句
如何查找MySQL中查询慢的SQL语句 更多 如何在mysql查找效率慢的SQL语句呢?这可能是困然很多人的一个问题,MySQL通过慢查询日志定位那些执行效率较低的SQL 语句,用--log-slow ...
- C++的STL在C#中的应用
这里主要讲几个重要的STL在C#中的应用:vector, map, hash_map, queue, set, stack, list. vector: 在C#中换成了list using Syste ...
- 常用的STL查找算法
常用的STL查找算法 <effective STL>中有句忠告,尽量用算法替代手写循环:查找少不了循环遍历,在这里总结下常用的STL查找算法: 查找有三种,即点线面: 点就是查找目标为单个 ...
随机推荐
- 51nod1210
题解: 二维树状数组,再矩阵推一下 代码: #include<bits/stdc++.h> using namespace std; typedef long long LL; ; int ...
- 自己写的一个delphi正整数快速排序
type TIntArr= array of word; procedure MyQSort(var arr: TIntArr; low: word; high: word); //word可以改 ...
- 关于CentOS 7 下的Oracle11g的proc编译器的一些常见问题
1.proc编译器配置问题 在使用proc将.pc文件编译成.c文件时出现一堆的错误,网上的答案七杂八杂的,都没有解决我的问题. 如下是我在使用过程中的一些错误: 由于我可能比较笨,实在是受不了网上那 ...
- jquery 实现内容的级联选取
- 【转】DelphiXE10.2.3——跨平台生成验证码图片
原文地址 Java.PHP.C#等很容易在网上找到生成验证码图片的代码,Delphi却寥寥无几,昨天花了一整天时间,做了个跨平台的验证码,可以用在C/S和B/S端,支持Windows.Linux.An ...
- Web Components 是什么
/********************************************************************************* * Web Components ...
- 在 Ubuntu 18.0-10上安装 MySQL8
直接使用apt install mysql-server安装,那么恭喜你踩坑. sudo apt install mysql-server默认会安装MySQL 5.7,将会出现一些莫名的问题,例如:安 ...
- CTF-练习平台-Misc之 妹子的陌陌
二十五.妹子的陌陌 该图片后缀名为rar,发现里面有一个文本 但是解压需要密码,应为不知道是几位的没法爆破,观察图片后发现红色字体:“喜欢我吗.”尝试一下,居然是密码,将文本解压出来 内容如下: 嘟嘟 ...
- 【矩阵快速幂】【杭电OJ1757】
http://acm.hdu.edu.cn/showproblem.php?pid=1757 A Simple Math Problem Time Limit: 3000/1000 MS (Java/ ...
- FutureTask的用法及两种常用的使用场景 + FutureTask的方法执行示意图
from: https://blog.csdn.net/linchunquan/article/details/22382487 FutureTask可用于异步获取执行结果或取消执行任务的场景.通过 ...