Py之pandas:dataframe学习【转载】
转自:https://www.tutorialspoint.com/python_pandas/python_pandas_dataframe.htm
1.数据框4特性

列是不同类型的数据元素。
每列的长度可变
行和列都有标签
对行和列可进行算术运算。
可将其视为SQL表。//这个十分容易理解了。
2.创建
pandas.DataFrame( data, index, columns, dtype, copy)
其中Data可以是list,dict,array,series,map,等。
- Lists
- dict
- Series
- Numpy ndarrays
- Another DataFrame
index是对行的索引,column是列名。
空
从List

从dict

3.列操作
选择列,直接用列名即可。
添加列:

删除列,
使用del函数或者pop函数:

4.行操作
对行索引,
可以通过label来进行,那么使用loc;通过行数字来进行,使用iloc:
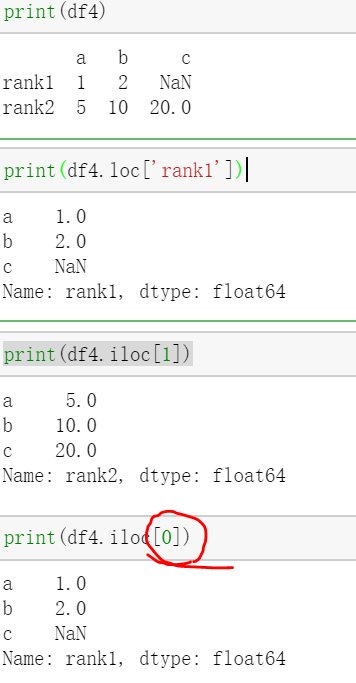
//行号是从0开始的。
对行进行数据切片:

//直接使用冒号即可,并且右边的数是取不到的。
添加行,使用append函数
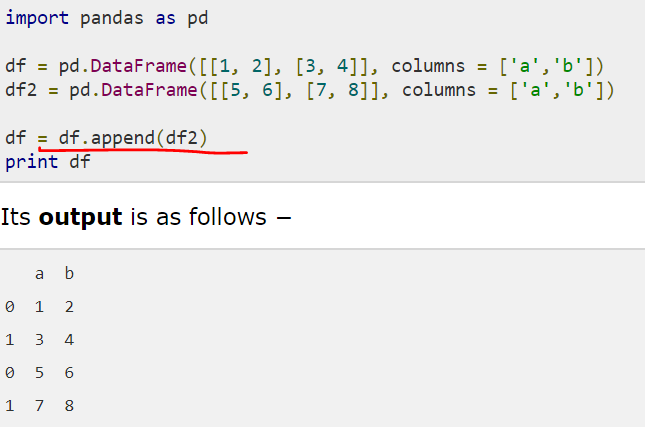
//注意上述,append了之后,index是仍旧保持原来的,会有相同的index。
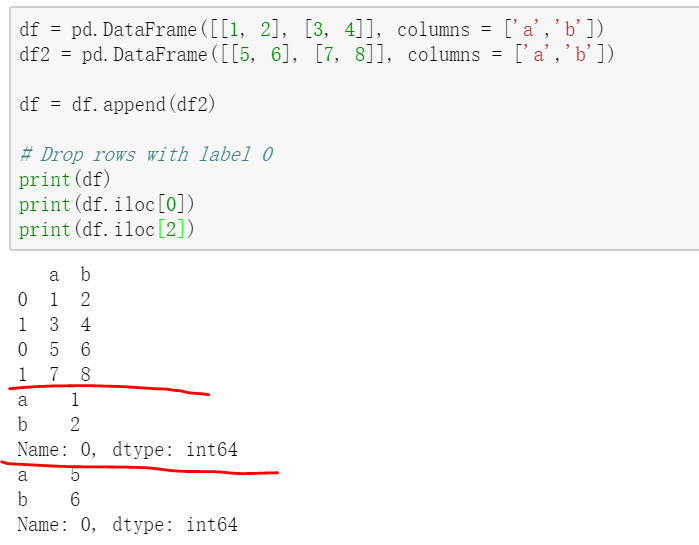
对于相同的index,如果使用整数去iloc的话,实际上并不是一列,从上述结果可以看书,那么如果是使用loc呢?
print(df.loc[''])
报错:KeyError: 'the label [0] is not in the [index]'
那么就只能用iloc去索引了

//去掉引号之后可以了。
这说明,对于不指定index的,自动生成的0,1,2,3.是label,使用loc索引。
删除行:

使用pop函数,会将具有相同label的行删除。
2020-3-3————————————
1.行遍历数据框
import pandas as pd
import numpy as np
b=pd.read_csv("a.txt",names=['','','','',''],skiprows=3,sep=' ')
a=np.zeros((4,2))
for i,v in b.iterrows():#这样就可以直接遍历行
a[i,0]=v[0]#下面可以直接访问列对另一个矩阵赋值
a[i,1]=v[2]
a.txt:
S.No Name Age City Salary df dfs
1 Tom 28 Toronto 20000.0
2 Lee 32 HongKong 3000.0
3 Steven 43 BayArea 8300.0
4 Ram 38 Hyderabad 3900.0
2.对行按照行名进行重新放置
import pandas as pd
import numpy as np
b=pd.read_csv("a.txt",sep=' ')
b.index=['a','b','c','d'] #直接这样就ok的啊。
也是非常的简单,直接b.reindex([....])即可,也可以是别的df的index
Py之pandas:dataframe学习【转载】的更多相关文章
- pandas.DataFrame学习系列1——定义及属性
定义: DataFrame是二维的.大小可变的.成分混合的.具有标签化坐标轴(行和列)的表数据结构.基于行和列标签进行计算.可以被看作是为序列对象(Series)提供的类似字典的一个容器,是panda ...
- Pandas DataFrame学习笔记
对一个DF r1 r2 r3 c1 c2 c3 选行: df['r1'] df['r2':'r2'] #包含r2 df[df['c1']>5] #按条件选 选列: df['c1'] ...
- pandas.DataFrame的pivot()和unstack()实现行转列
示例: 有如下表需要进行行转列: 代码如下: # -*- coding:utf-8 -*- import pandas as pd import MySQLdb from warnings impor ...
- pandas的学习总结
pandas的学习总结 作者:csj更新时间:2017.12.31 email:59888745@qq.com 说明:因内容较多,会不断更新 xxx学习总结: 回主目录:2017 年学习记录和总结 1 ...
- Python之Pandas库学习(二):数据读写
1. I/O API工具 读取函数 写入函数 read_csv to_csv read_excel to_excel read_hdf to_hdf read_sql to_sql read_json ...
- pandas再次学习
numpy.scipy官方文档 pandas官方网站 matplotlib官方文档 一.数据结构 二.数据处理 1.数据获取(excel文件数据基本信息) #coding=utf-8 import ...
- 如何通过Elasticsearch Scroll快速取出数据,构造pandas dataframe — Python多进程实现
首先,python 多线程不能充分利用多核CPU的计算资源(只能共用一个CPU),所以得用多进程.笔者从3.7亿数据的索引,取200多万的数据,从取数据到构造pandas dataframe总共大概用 ...
- Java多线程学习(转载)
Java多线程学习(转载) 时间:2015-03-14 13:53:14 阅读:137413 评论:4 收藏:3 [点我收藏+] 转载 :http://blog ...
- pandas DataFrame apply()函数(1)
之前已经写过pandas DataFrame applymap()函数 还有pandas数组(pandas Series)-(5)apply方法自定义函数 pandas DataFrame 的 app ...
随机推荐
- thinkphp 多对多关联模型(转)
先建立一个模型 1 2 3 4 5 6 7 8 9 10 11 12 <?php class UserModel extends RelationModel{ protected $ ...
- golang学习资料[Basic]
http://devs.cloudimmunity.com/gotchas-and-common-mistakes-in-go-golang/index.html 基础语法 <Go By Exa ...
- Egret IDE中搜索,过滤文件,只搜索.ts
刚开始忘了这个搜索条件在哪里打开了,后来找着了,记录一下 = =!
- Android ActivityManager与WindowManager
<uses-permission android:name="android.permission.GET_TASKS" /> <uses-permission ...
- phantomjs试玩
简单来说,phantomjs就是一个运行在node上的webkit内核,支持DOM渲染,css选择器,Canvas,SVG等,在浏览器上能做的事情,理论上,phantomjs 都能模拟做到. phan ...
- maven常用的plugin
maven-compiler-plugin 编译Java源码,一般只需设置编译的jdk版本 <plugin> <groupId>org.apache.maven.plugi ...
- logstash实战filter插件之grok(收集apache日志)
有些日志(比如apache)不像nginx那样支持json可以使用grok插件 grok利用正则表达式就行匹配拆分 预定义的位置在 /opt/logstash/vendor/bundle/jruby/ ...
- POJ-2329 Nearest number - 2(BFS)
Nearest number - 2 Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 4100 Accepted: 1275 De ...
- hihocoder 1829 - 压缩字符串 - [状压+暴力枚举][2018ICPC北京网络预赛B题]
题目链接:https://hihocoder.com/problemset/problem/1829 时间限制:1000ms 单点时限:1000ms 内存限制:256MB 描述 Lara Croft, ...
- ZOJ 3777 - Problem Arrangement - [状压DP][第11届浙江省赛B题]
题目链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=3777 Time Limit: 2 Seconds Me ...