Spark DataFrame vector 类型存储到Hive表
1. 软件版本
| 软件 | 版本 |
|---|---|
| Spark | 1.6.0 |
| Hive | 1.2.1 |
2. 场景描述
在使用Spark时,有时需要存储DataFrame数据到Hive表中,一般的存储方式如下:
// 注册临时表
myDf.registerTempTable("t1")
// 使用SQLContext从临时表创建Hive表
sqlContext.sql("create table h1 as select * from t1")
在DataFrame中存储一般的数据类型,比如Double、Float、String等到Hive表是没有问题的,但是在DataFrame中还有一个数据类型:vector , 如果存储这种类型到Hive表那么会报错,类似:
org.apache.spark.sql.AnalysisException: cannot resolve 'cast(norF as struct<type:tinyint,size:int,indices:array<int>,values:array<double>>)'
due to data type mismatch: cannot cast org.apache.spark.mllib.linalg.VectorUDT@f71b0bce to StructType(StructField(type,ByteType,true), StructField(size,IntegerType,true), StructField(indices,ArrayType(IntegerType,true),true), StructField(values,ArrayType(DoubleType,true),true));
这个错误如果搜索的话,可以找到类似这种结果: Failed to insert VectorUDT to hive table with DataFrameWriter.insertInto(tableName: String)
也即是说暂时使用Spark是不能够直接存储vector类型的DataFrame到Hive表的,那么有没有一种方法可以存储呢?
想到这里,那么在Spark中是有一个工具类VectorAssembler 可以达到相反的目的,即把多个列(也需要要求这些列的类型是一致的)合并成一个vector列。但是并没有相反的工具类,也就是我们的需求。
3. 问题的迂回解决方法
这里提出一个解决方法如下:
假设:
1. DataFrame中数据类型是vector的列中的数据类型都是已知的,比如Double,数值类型;
2. vector列中的具体子列个数也是已知的;
有了上面两个假设就可以通过构造RDD[Row]以及schema的方式来生成新的DataFrame,并且这个新的DataFrame的类型是基本类型,如Double。这样就可以保存到Hive中了。
4. 示例
本例流程如下:
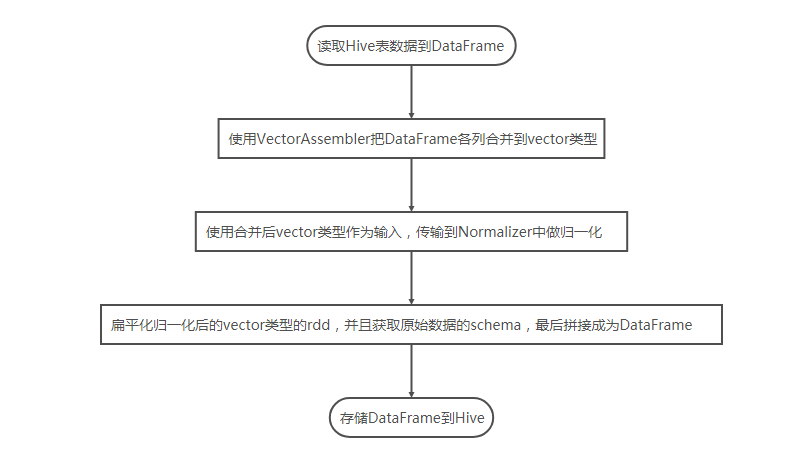
代码如下:
// 1.读取数据
val data = sqlContext.sql("select * from normalize")
读取数据如下:

// 2.构造vector数据
import org.apache.spark.ml.feature.VectorAssembler
val cols = data.schema.fieldNames
val newFeature = "fea"
val asb = new VectorAssembler().setInputCols(cols).setOutputCol(newFeature)
val newDf = asb.transform(data)
newDf.show()

// 3.做归一化
import org.apache.spark.ml.feature.Normalizer
val norFeature ="norF"
val normalizer = new Normalizer().setInputCol(newFeature).setOutputCol(norFeature).setP(1.0)
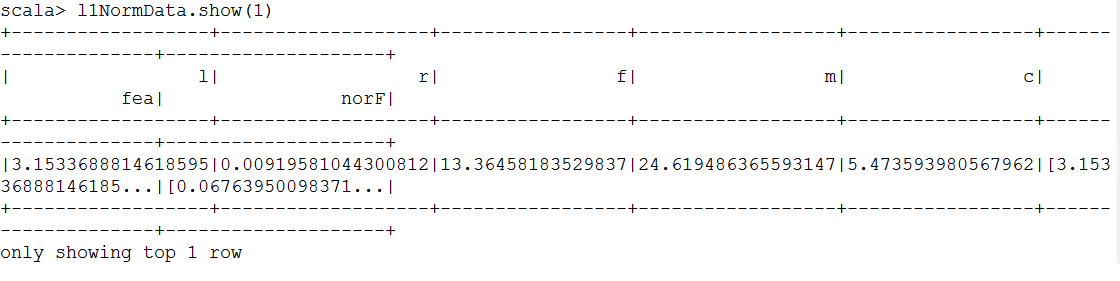
val l1NormData = normalizer.transform(newDf)
l1NormData.show()
// 存储DataFrame vector类型报错
// l1NormData.select(norFeature).registerTempTable("t1")
// sqlContext.sql("create table h2 as select * from t1")
// 4.扁平转换vector到row
import org.apache.spark.sql.Row
val finalRdd= l1NormData.select(norFeature).rdd.map(row => Row.fromSeq(row.getAs[org.apache.spark.mllib.linalg.DenseVector]().toArray))
val finalDf = sqlContext.createDataFrame(finalRdd,data.schema)
finalDf.show()

// 5. 存储到Hive中
finalDf.registerTempTable("t1")
sqlContext.sql("create table h1 as select * from t1")

Spark DataFrame vector 类型存储到Hive表的更多相关文章
- 将DataFrame数据如何写入到Hive表中
1.将DataFrame数据如何写入到Hive表中?2.通过那个API实现创建spark临时表?3.如何将DataFrame数据写入hive指定数据表的分区中? 从spark1.2 到spark1.3 ...
- Spark访问与HBase关联的Hive表
知识点1:创建关联Hbase的Hive表 知识点2:Spark访问Hive 知识点3:Spark访问与Hbase关联的Hive表 知识点1:创建关联Hbase的Hive表 两种方式创建,内部表和外部表 ...
- Spark SQL解析查询parquet格式Hive表获取分区字段和查询条件
首先说一下,这里解决的问题应用场景: sparksql处理Hive表数据时,判断加载的是否是分区表,以及分区表的字段有哪些?再进一步限制查询分区表必须指定分区? 这里涉及到两种情况:select SQ ...
- Spark访问Hive表
知识点1:Spark访问HIVE上面的数据 配置注意点:. 1.拷贝mysql-connector-java-5.1.38-bin.jar等相关的jar包到你${spark_home}/lib中(sp ...
- spark+hcatalog操作hive表及其数据
package iie.hadoop.hcatalog.spark; import iie.udps.common.hcatalog.SerHCatInputFormat; import iie.ud ...
- Spark 读写hive 表
spark 读写hive表主要是通过sparkssSession 读表的时候,很简单,直接像写sql一样sparkSession.sql("select * from xx") 就 ...
- spark相关介绍-提取hive表(一)
本文环境说明 centos服务器 jupyter的scala核spylon-kernel spark-2.4.0 scala-2.11.12 hadoop-2.6.0 本文主要内容 spark读取hi ...
- 大数据学习day25------spark08-----1. 读取数据库的形式创建DataFrame 2. Parquet格式的数据源 3. Orc格式的数据源 4.spark_sql整合hive 5.在IDEA中编写spark程序(用来操作hive) 6. SQL风格和DSL风格以及RDD的形式计算连续登陆三天的用户
1. 读取数据库的形式创建DataFrame DataFrameFromJDBC object DataFrameFromJDBC { def main(args: Array[String]): U ...
- 使用spark对hive表中的多列数据判重
本文处理的场景如下,hive表中的数据,对其中的多列进行判重deduplicate. 1.先解决依赖,spark相关的所有包,pom.xml spark-hive是我们进行hive表spark处理的关 ...
随机推荐
- ldap命令
ldapadd -x 进行简单认证 -D 用来绑定服务器的DN -h 目录服务的地址 -w 绑定DN的密码 -f 使用ldif文件进行条目添加的文件 -W 交互式输入DN的密码 ...
- Python 2.7.6 安装lxml模块[ubuntu14.04 LTS]
lxml --->首字母是字母l,不是数字1 lxml 2.x : https://pypi.python.org/pypi/lxml/2.3 1xml官网:http://lxml.de/ 一 ...
- 使用nginx做反代时遇到413 Request Entity Too Large的解决方法
在使用nginx做反向代理的时候,被反代的系统在上传文件的时候遇到413 错误 :Request Entity Too Large 原因是nginx限制了上传文件的大小,在nginx中可以配置最大允许 ...
- Dockerfile创建镜像
Dockerfile是一个文本格式的配置文件,用户可以使用Dockerfile来快速创建自定义的镜像. Dockerfile由一行行命令语句组成,并且支持易#开头的注释行. 一般而言Dockerfil ...
- dhroid - Dhdb orm简化sqlite数据库操作
android数据库其实使用的不多,dhroid框架中的网络缓存使用了数据库我就写了也写了一个数据库操作工具 dhroid 数据库基本还是单表操作多,为了简单我只做了单表,那些级联,懒加载,什么的分两 ...
- node+express实现文件上传功能
在进行node web开发时,我们可能经常遇到上传文件的问题,这一块如果我们没有经验,可能会遇到很多坑,下面我将跟大家分享一下,实现文件上传的一些方式. 一.node+express文件上传的常用方式 ...
- 神奇的thrust::device_vector与nvcc编译选项
在C++的GPU库thrust中,有两种vector thrust::device_vector<int> D; //GPU使用的内存中的向量 thrust::host_vector< ...
- linux启动程序和关闭程序脚本
关闭脚本: #!/bin/bash source /etc/profile log() { echo `date +[%Y-%m-%d" "%H:%M:%S]` $1 } log ...
- C 语言实现增量式PID
一直以来,pid都是控制领域的经典算法,之前尝试理解了很久,但还是一知半解,总是不得要领,昨天模仿着别人的代码写了一个增量式pid的代码. 我的理解就是pid其实就是对你设置的预定参数进行跟踪.在控制 ...
- html 在一个超链接上面,鼠标移动上去时,也显示一串文字,如何实现
a标签的title属性,对title属性赋值即可.例如:<a href="http://www.baidu.com/" title="跳转到百度"> ...