12 python json&pickle&shelve模块
1、什么叫序列化
序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes(字节)
2、用于序列化的两个模块,json和pickle
json,用于字符串 和 python数据类型间进行转换
pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load pickle模块提供了四个功能:dumps、dump、loads、load
2.1json和pickle的对比分析
json vs pickle: JSON: 优点:跨语言、体积小 缺点:只能支持int\str\list\tuple\dict Pickle: 优点:专为python设计,支持python所有的数据类型 缺点:只能在python中使用,存储数据占空间大
# 把内存数据转成字符串数据类型,叫序列化 : dumps dump
# 把字符串数据类型转化成内存数据 叫反序列化 : loads load
dumps和dump,load和loads的区别: dumps是将对象序列化,loads将序列化字符串反序列化。
dump是将对象序列化并保存到文件中,load将序列化字符串从文件读取并反序列化。
重点:dumps仅转为为字符串,loads反序列化,转化为原型
# dumps仅转化成字符串
import json
data = {'k1':123,'k2':'hello'}
d = json.dumps(data)
d1 = json.loads(d)
print('序列化',d,type(d))
print('反序列化d1',d1,type(d1))
输出为:
序列化 {"k1": 123, "k2": "hello"} <class 'str'>
反序列化d1 {'k1': 123, 'k2': 'hello'} <class 'dict'>
重点:dump先主动转化再写入文件,load读取json文件返回原型
#转化为字符并写入文件dump
data2 ={'a1':123,'b1':456}
with open('test序列.py','a+',encoding='utf-8') as f:
f1 = json.dump(data2,f)
print('序列化dump:',f1,type(f1))
序列化dump: None <class 'NoneType'>
因为:json.dump主要用来json文件读写 #反序列化:
import json
with open('test序列.py','r') as f2:
file = json.load(f2)
print('反序列化load:',file,type(file))
反序列化load: {'a1': 123, 'b1': 456} <class 'dict'>
因为: json.load是读取json数据 json.dumps : ’dict’转成str json.dump是将python数据保存成json json.loads:str转成’dict’ json.load是读取json数据 json.load是解析json文件的;json.loads是解析json字符串的
dumps 和loads对应
dump 和 load 对应
# 只是把数据转成字符串存到内存里的意义?
# json.dumps json.loads
# 1 把你的内存数据通过网络,共享给远程其他人
# 2 定义了不同语言之间的交互规则
# (1)纯文本,坏处:不能共享复杂的数据类型。(2)xml,坏处:占空间大。(3)json,简单,可读性好
3、pickle模块
与JSON不同的是pickle不是用于多种语言间的数据传输,它仅作为python对象的持久化或者python程序间进行互相传输对象的方法,因此它支持了python所有的数据类型。 import pickle
data = {'k1':123,'k2':'abc'}
d = pickle.dumps(data)
d2 = pickle.loads(d)
print('序列化',d,type(d))
print('反序列化d1',d2,type(d2)) 输出:
序列化 b'\x80\x03}q\x00(X\x02\x00\x00\x00k1q\x01K{X\x02\x00\x00\x00k2q\x02X\x03\x00\x00\x00abcq\x03u.' <class 'bytes'>
pickle.dumps输出为二进制模式,bytes就是单纯的二进制 反序列化d1 {'k1': 123, 'k2': 'abc'} <class 'dict'> (2)
pickle.dump/pickle.load #pickle只能以二进制格式存储数据到文件 f = open('test1.txt','wb')
data = {'k1':123,'k2':'abc'}
f1 = pickle.dump(data,f) #序列化对象到文件
print('pickle.dump(data,f):',f1,type(f1))
f = open('test1.txt','rb')
red = pickle.load(f) #从文件中反序列化对象
print('pickle.load(f)',red,type(red)) 输出结果:
pickle.dump(data,f): None <class 'NoneType'>#保存的为对象
pickle.load(f) {'k1': 123, 'k2': 'abc'} <class 'dict'>
4、shelve
Shelve是对象持久化保存方法,将对象保存到文件里面,缺省(即默认)的数据存储文件是二进制的。
用途:可以作为一个简单的数据存储方案
shelve与pickle类似用来持久化数据的,不过shelve是以键值对的形式,将内存中的数据通过文件持久化,
值支持任何pickle支持的python数据格式,它会在目录下生成三个文件。
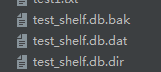
import shelve
s = shelve.open('test_shelf.db') #创建shelve并打开
try:
s['kk'] = {'int': 10, 'float': 9.5, 'String': 'Sample data'} #写入数据
s['MM'] = [1, 2, 3]
finally:
s.close() #关闭文件
import shelve
s = shelve.open('test_shelf.db') #打开文件
print(s['kk']) #访问数据
s.close()
输出:{'int': 10, 'float': 9.5, 'String': 'Sample data'} <class 'dict'>
(2)对于存储的key,value值,只能添加key,value,可修改整个value,不能单独修改列表或字典中的元素
s = shelve.open('test_shelf.db') #打开文件
#添加数据:s['k2']=[1,2,3]
若s['k2'] = [1,2,3]
#添加后修改(NO) s['k2'][0]=99 #修改存储的value的单个值时不生效也不报错
#可以整个修改: s['k2']=(33,44) #可以修改key的value
写回(write-back)由于shelve在默认情况下是不会记录待持久化对象的任何修改的,所以我们在shelve.open()时候需要修改默认参数,否则对象的修改不会保存。
>>> s = shelve.open('test_s.db',writeback=True) #使用回写功能打开
>>> print(s['k1']) #初始值
{'float': 8.8, 'string': 'python', 'int': 10}
>>> print(s['k2'])
(33, 44)
>>> s['k1']['float']='99.99' #修改字典中的元素
>>> print(s['k1']) #成功修改
{'float': '99.99', 'string': 'python', 'int': 10}
# 1.创建一个shelf对象,直接使用open函数即可 import shelve
s = shelve.open('test_shelf.db') #
try:
s['kk'] = {'int': 10, 'float': 9.5, 'String': 'Sample data'}
s['MM'] = [1, 2, 3]
finally:
s.close() # 2.如果想要再次访问这个shelf,只需要再次shelve.open()就可以了,然后我们可以像使用字典一样来使用这个shelf import shelve
try:
s = shelve.open('test_shelf.db')
value = s['kk']
print(value)
finally:
s.close() # 3.对shelf对象,增、删、改操作 import shelve
s = shelve.open('test_shelf.db', flag='w', writeback=True)
try:
# 增加
s['QQQ'] = 2333
# 删除
del s['MM']
# 修改
s['kk'] = {'String': 'day day up'}
finally:
s.close() # 注意:flag设置为‘r’-只读模式,当程序试图去修改一个以只读方式打开的DB时,将会抛一个访问错误的异常。异常的具体类型取决于anydbm这个模块在创建DB时所选用的DB。异常举例:anydbm.error: need ‘c’ or ‘n’ flag to open new db # 4.循环遍历shelf对象 import shelve
s = shelve.open('test_shelf.db')
try:
# 方法一:
for item in s.items():
print ('键[{}] = 值[{}]'.format(item[0], s[item[0]]))
# 方法二:
for key, value in s.items():
print(key, value)
finally:
s.close()
writeback=True,对子字典修改完后要写回,否则不会看到修改后的结果
open(filename, flag='c', protocol=None, writeback=False):
12 python json&pickle&shelve模块的更多相关文章
- Python json & pickle & shelve模块
json & pickle 之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇 ...
- Python json & pickle, shelve 模块
json 用于字符串和python的数据类型间的转换 四个功能 dumps dump loads load pickle 用于python特有的类型和python的数据类型进行转换 四个功能 dump ...
- python序列化: json & pickle & shelve 模块
一.json & pickle & shelve 模块 json,用于字符串 和 python数据类型间进行转换pickle,用于python特有的类型 和 python的数据类型间进 ...
- python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess logging re正则
python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess ...
- day6_python序列化之 json & pickle & shelve 模块
一.json & pickle & shelve 模块 json,用于字符串 和 python数据类型间进行转换pickle,用于python特有的类型 和 python的数据类型间进 ...
- Python全栈之路----常用模块----序列化(json&pickle&shelve)模块详解
把内存数据转成字符,叫序列化:把字符转成内存数据类型,叫反序列化. Json模块 Json模块提供了四个功能:序列化:dumps.dump:反序列化:loads.load. import json d ...
- Python序列化,json&pickle&shelve模块
1. 序列化说明 序列化可将非字符串的数据类型的数据进行存档,如字典.列表甚至是函数等等 反序列化,将通过序列化保存的文件内容反序列化即可得到数据原本的样子,可直接使用 2. Python中常用的序列 ...
- json,pickle,shelve模块,xml处理模块
常用模块学习—序列化模块详解 什么叫序列化? 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes. 为什么要序列化? 你打游戏过程 ...
- json&pickle&shelve模块
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了 ...
随机推荐
- pow 的使用和常见问题
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/menxu_work/article/details/24540045 1.安装: $ curl ge ...
- TensorFlow笔记-07-神经网络优化-学习率,滑动平均
TensorFlow笔记-07-神经网络优化-学习率,滑动平均 学习率 学习率 learning_rate: 表示了每次参数更新的幅度大小.学习率过大,会导致待优化的参数在最小值附近波动,不收敛:学习 ...
- 检索关键字 nyoj
检索关键字 时间限制: 1000ms 内存限制: 65536KB 64位整型: Java 类名: 上一题 提交 运行结果 统计 讨论版 下一题 类型: 没有 没有 难度 ...
- velocity 知识点
velocity 教程: http://www.51gjie.com/javaweb/126 velocity 语法 语法 说明 关键字以#开头 定义数组 ['aaa','bbb'] 变量以$开头 把 ...
- webpack externals
当我们想在项目中require一些其他的类库或者API,而又不想让这些类库的源码被构建到运行时文件中,这在实际开发中很有必要.此时我们就可以通过配置externals参数来解决这个问题: //webp ...
- asp.net 退出登陆(解决退出后点击浏览器后退问题仍然可回到页面问题)
代码如下: Session.Abandon(); Response.Redirect("Login.aspx"); 但是这样点点击浏览器的后退仍然可以回到刚才的页面,这可不行,在网 ...
- 【Active入门-3】ActiveMQ学习-发布者与订阅者
2015年4月28日 1个发布者,1个订阅者,topic 方式1: 先发布消息: 然后订阅消息: 方式2: 先订阅消息: 然后发布消息:订阅者如下: 结论1: 从上面可以看出,消息发布需要在线发布. ...
- Sigar简介
大家好,我是Sigar.也许好多人还不认识我.下面就介绍一下我自己,好让大家对我有一个大致的了解. 我的全名是System Information Gatherer And Reporter,中文名是 ...
- 小峰mybatis(5)mybatis使用注解配置sql映射器--动态sql
一.使用注解配置映射器 动态sql: 用的并不是很多,了解下: Student.java 实体bean: package com.cy.model; public class Student{ pri ...
- AppScan代理扫描app/H5安全测试(没试过,记录在此)
标签: 1.首先设置AppScan代理,设置如下: