1 python 文件处理
1、打开文件open 函数
open函数最常用的使用方法如下:文件句柄 = open('文件路径', '模式',编码方式)。 encode=''
1、关于文件路径
#文件路径:
主要有两种,一种是使用相对路径,想上面的例子就是使用相对路径。
另外一种就是绝对路径, 如:C:/Users/Desktop/python/test.txt'
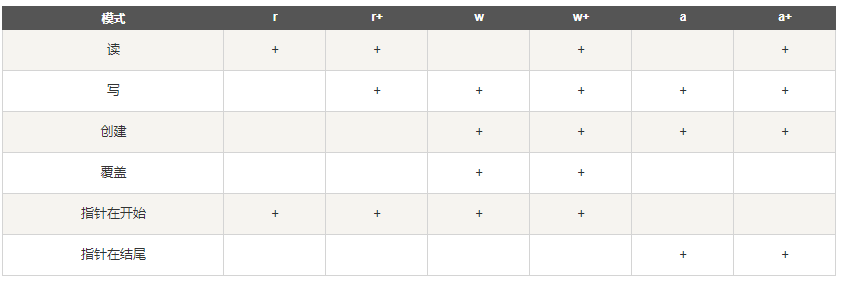
2、读取文件的各种方法说明:
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。(只读模式)指针在开头 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 (只读模式) 指针在开头 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 (读写模式)指针在开头 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。(删除原内容,写入,文件不存在就创建)指针在开头 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。指针在开头 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
# test.txt原文 :python,is,on,the,way
# 只读
f=open('test.txt','r')
print(f.read())# 输出 python,is,on,the,way# 读写
#读写
# 先写再度 此模式在最开始光标在最开始
f=open('test.txt','r+')
f.write('java')
print(f.read()) #on,is,on, the, way
f.close()
文本内容:# javaon,is,on,the,way
首先,以r 方式打开光标都会在最开始的位置,这时候执行f.write('java'),
这时候就把原来的pyth
紧接着进行print(f.read())。就会把后面剩下的文本内容打印出来。所以输出就是:on,is,on, the, way 整个程序完成后,
整个文本内容就成了javaon,is,on,the,way (光标!!) 写入的光标依据输入字符串的长度往后移动,,空格,逗号等符号也算!被取代 python,is,on,the,way
当写入 java1234
最后文本中为 java1234s,on,the,way
#----------------------------------------------
#先读再写 读取之后光标停留在文本末尾
f=open('test.txt','r+')
f.read()
f.write("java1234")
f.write("aa")
f.write("bb")
f.write("cc")
f.write("dd")
先读再写的结果: python,is,on,the,wayjava1234aabbccdd
先读再写就是往读的后面依次添加,先写再读就是在文本最开始位置依次添加。
循环文件:
f = open("text.txt",'r',encoding="utf-8") for line in f:
print(line) f.close() 就是输出文件的内容
3、读取文件的三种操作
# -----------------------------------------------------------------------
读取文件的三种操作 1、read() #一次性读取文本中全部的内容,以字符串的形式返回结果 文本里面是什么状态读取就是什么状态:
特点是:读取整个文件,将文件内容放到一个字符串变量中。劣势是:如果文件非常大,尤其是大于内存时,无法使用read()方法。read()直接读取字节到字符串中,包括了换行符 2、readline() #只读取每次读取第一行的内容,以字符串的形式返回结果 3、readlines() #读取文本所有内容,并且以列表的格式返回结果,一般配合for in使用
f = file.readlines() 读取文本,每行为一个元素:['beijing haha hhhhh kkkkkk lllll'];在不同行的读取结果:['beijing\n', 'haha\n', 'hhhhh\n', 'kkkkkk lllll'] #--------------------------------------------------------------------------------
text = file.read() # 结果为str类型
read()、.readline() 和 .readlines()。每种方法可以接受一个变量以限制每次读取的数据量,但它们通常不使用变量。
4、关闭文件:
不关闭占用内存资源,而且还可能导致其他不安全隐患。还有一种方法可以让我们不用去特意关注关闭文件。那就是 with open()
with open('test.txt','a+') as f:
f.write('')
print(f.readable())
这不必调用f.close()方法。
5、写入文件
# 写入
# test.txt原文 :python,is,on,the,way f=open('test.txt','r+')
# 前面加 r
print(f.read())
f.write(r'this\nis\nhaiku') #write(string)
print(f.read()) >>输出
python,is,on,the,way
this\nis\nhaiku # 不加 r(r'this\nis\nhaiku')
输出:
python,is,on,the,way
this
is
haiku #------------------------------------------------------------------------------------------------------------------ 还有write、writelines方法,用法与上述方法对应类似,只不过write写入的对象时字符串(str),writelines写入的是列表(list),即: obj.write(str) obj.writelines(sequence)
向文件写入一个字符串或一个字符串列表,如果字符串列表中的元素需要换行要自己加入换行符
# writelines(list)写入时列表
list02 = ["","test","hehe","",""] obj.writelines(list02) li1 = ['','','','[1,2,3]'] writelines 写入list 但 列表里面的每个元素必须是字符串的形式,否则会报错 with open('test.txt','r+',encoding='utf-8') as file:
li1 = ['','','']
f2 = file.writelines(li1) #写入后文本中显示: 123国人主要在亚洲 utf-8 一个中文占三个字节
f = file.read()
print(f) # 原先的test.txt:中国人主要在亚洲
6、read(size),size可以从文件中读取的字符数
以rb模式打开就是读取的字节数------------以r模式打开就是读取的字符数 1、f.read([size]):默认一次性读入打开的文件内容。如果有size参数,则指定每次读入字符数。注意,此处按字符来读入,一个汉字为一个字符
例如文本:123,。[]国人主要在亚洲 # 字符每写一个就算字符,英文,汉字,标点符号都算
f = file.read(8)# 0 读出为空,1才为第一个字符
print(f)
> 123,。[]国 (读取8个显示的结果)
2、f.readline([size]):一次读入一行文件内容
f = file.readline(8)
print(f)
> 123,。[]国 #size字符数
3、f.readlines([size]):将文件内容全部读入,保存在一个列表中,每行为一个元素。
文本中两行:
123,。[]国人主要在亚洲 (14个字符)
hdi0好 若
f = file.readlines(14) #(size<=14)
print(f)
>['123,。[]国人主要在亚洲\n'] 只显示第一行的内容
f = file.readlines(15) # 超过第一行字符数,则显示第二行的内容
print(f)
>
['123,。[]国人主要在亚洲\n', 'hdi0好']
f.writ(str,encoding=):将str写入文件,可以指定写入的编码格式,默认为utf-8 f.writlines() f.readable() : 判断是否可读,返回布尔值。如果是在只写模式下打开文件, 也是返回false f.writable():判断是否可写 f.tell() : 返回当前光标位置 f.seek(offset,whence=0):将光标位置移至所需位置。offset为偏移量。whence定义开始偏移的位置。
0为从文件开头偏移。1为从当前位置开始偏移。2为从文件末尾开始偏移,---------默认为0。
def seek(self, *args, **kwargs): # real signature unknown
把操作文件的光标移到指定位置
*注意seek的长度是按字节算的, 字符编码存每个字符所占的字节长度不一样。
如“路飞学城” 用gbk存是2个字节一个字,用utf-8就是3个字节,因此以gbk打开时,seek(4) 就把光标切换到了“飞”和“学”两个字中间。
但如果是utf8,seek(4)会导致,拿到了飞这个字的一部分字节,打印的话会报错,因为处理剩下的文本时发现用utf8处理不了了,因为编码对不上了。少了一个字节def truncate(self, *args, **kwargs): # real signature unknown
按指定长度截断文件
*指定长度的话,就从文件开头开始截断指定长度,不指定长度的话,就从当前位置到文件尾部的内容全去掉。f.flush() 把文件从内存buffer里强制刷新到硬盘
清空文件内容 f.truncate() 注意:仅当以 "r+" "rb+" "w" "wb" "wb+"等以可写模式打开的文件才可以执行该功能。 七、删除文件 import os os.remove(file)
1 python 文件处理的更多相关文章
- Linux下Python 文件内容替换脚本
Linux下Python 文件替换脚本 import sys,os if len(sys.argv)<=4: old_text,new_text = sys.argv[1],sys.argv[2 ...
- 【Python文件处理】递归批处理文件夹子目录内所有txt数据
因为有个需求,需要处理文件夹内所有txt文件,将txt里面的数据筛选,重新存储. 虽然手工可以做,但想到了python一直主张的是自动化测试,就想试着写一个自动化处理数据的程序. 一.分析数据格式 需 ...
- Python文件使用“wb”方式打开,写入内容
Python文件使用"wb"方式打开,写入字符串会报错,因为这种打开方式为:以二进制格式打开一个文件只用于写入.如果该文件已存在则将其覆盖.如果该文件不存在,创建新文件. 所以写入 ...
- Python 文件操作函数
这个博客是 Building powerful image classification models using very little data 的前期准备,用于把图片数据按照教程指示放到规定的文 ...
- python文件I/O(转)
Python 文件I/O 本章只讲述所有基本的的I/O函数,更多函数请参考Python标准文档. 打印到屏幕 最简单的输出方法是用print语句,你可以给它传递零个或多个用逗号隔开的表达式.此函数把你 ...
- python 文件操作总结
Python 文件I/O 本章只讲述所有基本的的I/O函数,更多函数请参考Python标准文档. 打印到屏幕 最简单的输出方法是用print语句,你可以给它传递零个或多个用逗号隔开的表达式.此函数把你 ...
- Python基础篇【第2篇】: Python文件操作
Python文件操作 在Python中一个文件,就是一个操作对象,通过不同属性即可对文件进行各种操作.Python中提供了许多的内置函数和方法能够对文件进行基本操作. Python对文件的操作概括来说 ...
- python文件和元组
python文件操作 相较于java,Python里的文件操作简单了很多 python 获取当前文件所在的文件夹: os.path.dirname(__file__) 写了一个工具类,用来在当前文件夹 ...
- Python文件基础
===========Python文件基础========= 写,先写在了IO buffer了,所以要及时保存 关闭.关闭会自动保存. file.close() 读取全部文件内容用read,读取一行用 ...
- python文件打包格式,pip包管理
1..whl是python文件的一种打包格式, 在有些情况下,可以将文件的后缀名改为.zip并解压 2.cmd中,提示pip版本太低,先升级pip pip install --upgrade pi ...
随机推荐
- sql server 循环操作
使用的sql 语句如下: declare @userid int ;set @userid=0while(@userid<20)begin print 'the result is :'+STR ...
- C#编程之IList<T>、List<T>、ArrayList、IList, ICollection、IEnumerable、IEnumerator、IQueryable 和 IEnumerable的区别
额...今天看了半天Ilist<T>和List<T>的区别,然后惊奇的发现使用IList<T>还是List<T>对我的项目来说没有区别... 在C#中 ...
- JMeter分布式部署的大致步骤以及误区解释
master和slave机要在同一网段内,才能做分布式(Jmeter要配环境变量,这样不用手动起server) 分布式不成功,解决方案: 1.master端和slave端要ping通 2.ping通后 ...
- 监控分析——Web中间件
发现 中间件监控看是否有性能瓶颈 核心:主要看中间件的线性池进程池有没有排队情况,请求是否处理及时就OK Apache 以前php都是用apache,现在基本用nginx了. 首先自己启动apache ...
- vue 知识点
Vue 中的 slot: 概念:槽/slot是组件在模板中为调用者预留的位置,使用<slot>元素声明一个 槽.在最终的视图中,调用者模板中被调用组件的内容,将填充<slot> ...
- PHP安全相关的配置(1)
PHP作为一门强大的脚本语言被越来越多的web应用程序采用,不规范的php安全配置可能会带来敏感信息泄漏.SQL注射.远程包含等问题,规范的安全配置可保障最基本的安全环境.下面我们分析几个会引发安全问 ...
- IE版本检测
<html><body><script type="text/javascript">var browser=navigator.appName ...
- thinkPHP5 引入模板
有三种方法:第一种: 直接使用 return view(); 助手函数第二种: use think\View; class Admin extends View 见下第三种: use think\Co ...
- jmeter测试TCP服务器/模拟发送TCP请求
jmeter测试TCP服务器,使用TCP采样器模拟发送TCP请求. TCP采样器:打开一个到指定服务器的TCP / IP连接,然后发送指定文本并等待响应. jmeter模拟发送TCP请求的方法: 1. ...
- json包含单双引号问题解决方案
解决方案:在后台处理 JSONArray.fromObject(list).toString() 转自明明如月小角落: 效果DEMO: JsonQuotesUtil.js /** * 解决json传输 ...