Scrapy反爬
1,随机更换 user-agent:
将足够多的user-agent放在settings中,在parse方法中调用

缺点:每一个request中都要调用这个方法
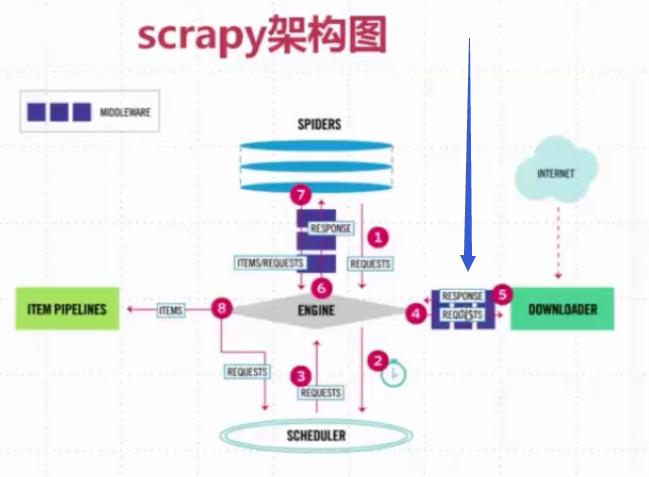 这个是scrapy的流程图。
这个是scrapy的流程图。
既然每一次下载都需要通过中间件,那么为什么不写在中间件里面呢?

scrapy怎么写呢?
在官方文档中可以知道,需要处理的是三个个方式
1,process_request(request, spider)
2,process_response(request, response, spider)
3, process_ exception(request, exception, spider)
当然在github上面已经有人写过随机更换user-agent了
在github上面搜索fake-useragent即可
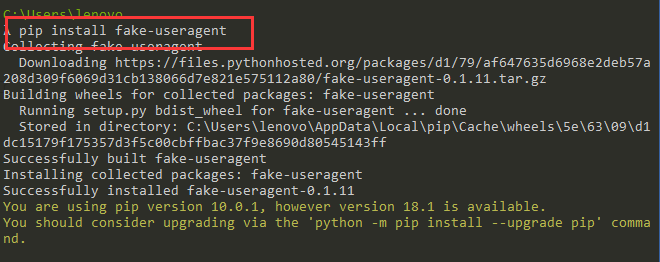
pip install fake-useragent
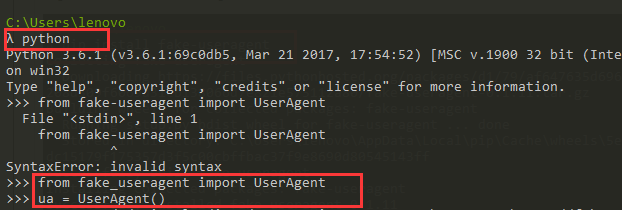
首先进入python的交互环境,引入并实例化对象。
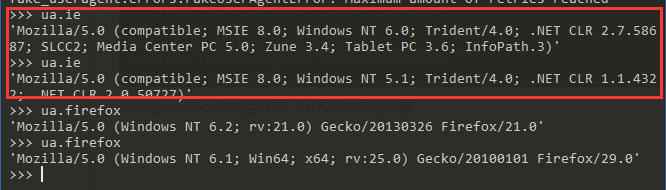
注意的是,这个里面即使使用同一个浏览器他的useragent都是不一样的,这样就满足要求了
每一次需要指定浏览器类型还是比较麻烦,在这个里面有一个好的方法random
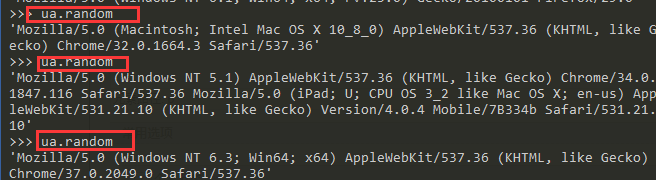
>>> ua.random
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1664.3 Safari/537.36'
>>> ua.random
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.116 Safari/537.36 Mozilla/5.0 (iPad; U; CPU OS 3_2 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML, like Gecko) Version/4.0.4 Mobile/7B334b Safari/531.21.10'
>>> ua.random
'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36'
这样他就可以随机生成浏览器的请求头了,就没有必要专门在settings中维护user-agent了
from fake_useragent import UserAgent class RandomUserAgentMiddleware(object):
def __init__(self, crawler):
super(RandomUserAgentMiddleware, self).__init__() # 使用父类的方法来进行初始化 self.ua = UserAgent()
self.per_proxy = crawler.settings.get('RANDOM_UA_PER_PROXY', False)
self.ua_type = crawler.settings.get('RANDOM_UA_TYPE', 'random')
self.proxy2ua = {} @classmethod
def from_crawler(cls, crawler): # 传递爬虫信息
return cls(crawler) def process_request(self, request, spider):
def get_ua(): # 因为
'''Gets random UA based on the type setting (random, firefox…)'''
return getattr(self.ua, self.ua_type) # 取self.ua中的self.ua_type的值 if self.per_proxy:
proxy = request.meta.get('proxy')
if proxy not in self.proxy2ua:
self.proxy2ua[proxy] = get_ua()
logger.debug('Assign User-Agent %s to Proxy %s'
% (self.proxy2ua[proxy], proxy))
request.headers.setdefault('User-Agent', self.proxy2ua[proxy])
else:
ua = get_ua()
request.headers.setdefault('User-Agent', get_ua())
在settings中配置需要哪种类型的agent,是随机选择ie还是Firefox,还是Chrome
还是随机任意一个
RANDOM_UA_PER_PROXY = 'random'
当然在这个地方会遇到问题就是self.ua.self.ua_type还可以成立吗,当然不行,因为python是一门动态语言,支持,函数中定义函数、
相当于闭包的一个特性
2,代理IP (尽量不要让自己本机的IP被封,因为本机IP效果最好,西刺高匿代理IP)
1,买了亚马逊等除了阿里云的服务器,动态分配IP
2,通过request.meta['proxy']="https://^^^^^^^"
3,设置代理池
如何获取呢?写个爬虫爬取西刺高匿的IP代理嘛
------------------------------
安装scrapy_proxies库,pip install scrapy_proxies即可,
收费的有scrapy-crawlera
或者使用tor洋葱浏览器
3,在线打码平台(云打码)
4,配置Scrapy,降低被封几率
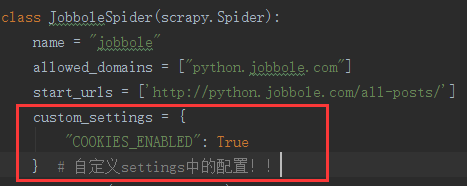
① cookies的禁用
settings中有一个参数,COOKIES_ENABLED = True,对于一些不需要登录的网站就可以设置为False,但是对于像知乎之类的需要登录的网站就不行
② 控制下载的速度
https://scrapy-chs.readthedocs.io/zh_CN/latest/topics/autothrottle.html
AUTOTHROTTLE_ENABLED = True # 如果设置为False的话,默认不开启间隔下载
DOWNLOAD_DELAY = 3 # 默认下载时间3s
③ 根据不同的spider设定不同的settings值
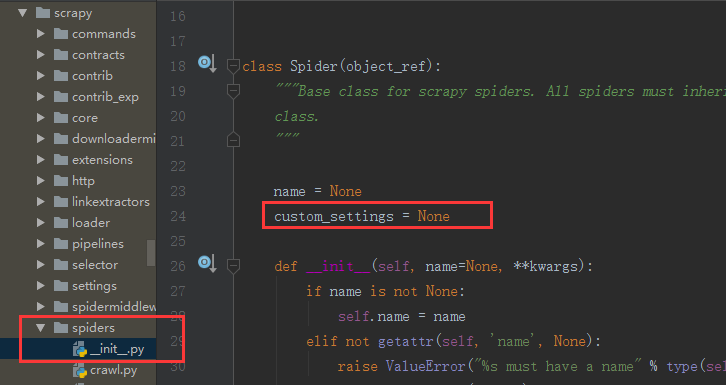
我们在源码中可以看到,这里面有个custom_settings默认为None
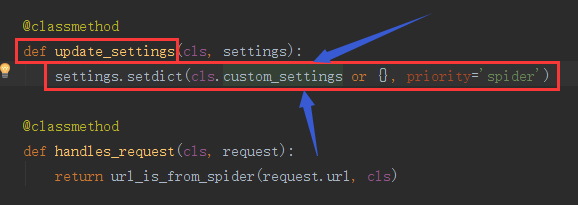
在update_settings这个类方法中可以看到类调用了custom_settings,所以,我们可以根据不同的爬虫,在settings中定制不同的custom_settings
把所需要的参数给传递进去即可。
custom_settings = {
"COOKIES_ENABLED": True
}
Scrapy反爬的更多相关文章
- Scrapy———反爬蟲的一些基本應對方法
1. IP地址驗證 背景:有些網站會使用IP地址驗證進行反爬蟲處理,檢查客戶端的IP地址,若同一個IP地址頻繁訪問,則會判斷該客戶端是爬蟲程序. 解決方案: 1. 讓Scrapy不斷隨機更換代理服務器 ...
- 关于使用scrapy框架编写爬虫以及Ajax动态加载问题、反爬问题解决方案
Python爬虫总结 总的来说,Python爬虫所做的事情分为两个部分,1:将网页的内容全部抓取下来,2:对抓取到的内容和进行解析,得到我们需要的信息. 目前公认比较好用的爬虫框架为Scrapy,而且 ...
- 第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用.自动限速.自定义spider的settings,对抗反爬机制 cookie禁用 就是在Scrapy的配置文件set ...
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- 二十四 Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scrapy架构源码分析图
- scrapy——4 —反爬措施—logging—重要参数—POST请求发送实战
scrapy——4 常用的反爬虫策略有哪些 怎样使用logging设置 Resquest/Response重要参数有哪些 Scrapy怎么发送POST请求 动态的设置User-Agent(随即切换Us ...
- Scrapy中的反反爬、logging设置、Request参数及POST请求
常用的反反爬策略 通常防止爬虫被反主要有以下几策略: 动态设置User-Agent(随机切换User-Agent,模拟不同用户的浏览器信息.) 禁用cookies(也就是不启用cookies midd ...
- scrapy请求传参-BOSS反爬
scrapy请求传参-BOSS反爬 思路总结 首先boss加了反爬 是cookies的 爬取的内容为职位和职位描述 # -*- coding: utf-8 -*- import scrapy from ...
- Scrapy 教程(六)-反爬
伪装浏览器 服务器可以查看访问的终端,如果不是浏览器,可能会被屏蔽,而且即使你用同一浏览器访问频率过快,也可能被屏蔽,所以需要伪装浏览器反爬. 有以下几种方法 1. 在 settings中添加 use ...
随机推荐
- PythonStudy——字符串常用操作 String common operations
# 1.字符串的索引取值: 字符串[index]# 正向取值从0编号,反向取值从-1编号 s1 = '123abc呵呵' t_s = ' # 取出c print(s1[5], s1[-3]) # 2. ...
- Python生成器(generator)和迭代器(Iterator)
列表生成式 a = [i+1 for i in range(10)] print(a) [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 这就是列表生成式 生成器(generator) ...
- Centos7 下安装VMware tools
1:先在虚拟机点击安装VMware Tools 2:然后挂载 mount /dev/cdrom /mnt 3:进入/mnt,可以看到有 4:拷贝VMwareTools到其他 ...
- 汉语言处理工具pyhanlp的简繁转换
繁简转换 HanLP几乎实现了所有我们需要的繁简转换方式,并且已经封装到了HanLP中,使得我们可以轻松的使用,而分词器中已经默认支持多种繁简格式或者混合.这里我们不再做过多描述. 说明: ·Ha ...
- c# 判断时间是否在 某一时间段内
protected bool getTimeSpan(string timeStr) { //判断当前时间是否在工作时间段内 string _strWorkingDayAM = "08:30 ...
- Spring boot 配置 mybatis xml和动态SQL 分页配置
更新时间 2018年4月30日23:27:07 1.pom.xml <?xml version="1.0" encoding="UTF-8"?> & ...
- android升级gradle到3.4.1
这两天把gradle升级到了gradle-3.4.1 com.android.tools.build:gradle升级到了com.android.tools.build:gradle:2.3.0 结果 ...
- 【译】Building ArduPilot on Windows with waf and Bash
原文链接:http://ardupilot.org/dev/docs/building-ardupilot-onwindows10.html 翻译水平有限,如有错误请指出! 在Windows上使用wa ...
- 自定义python扩展类型
目标:自定义一个C\C++矩阵类,有几个用于演示的矩阵运算函数或者操作,将其通过 PyTypeOject newType的方式注册到python中成为一种新的类型,并且要可继承. 预备知识 建议先运行 ...
- sql server 数据库变成单用户模式的恢复
USE master;GODECLARE @SQL VARCHAR(MAX);SET @SQL=''SELECT @SQL=@SQL+'; KILL '+RTRIM(SPID)FROM master. ...