Hadoop服务库与事件库的使用及其工作流程
Hadoop服务库与事件库的使用及其工作流程
Hadoop服务库:
YARN采用了基于服务的对象管理模型,主要特点有:
- 被服务化的对象分4个状态:NOTINITED,INITED,STARTED,STOPED
- 任何服务状态变化都可以触发另外一些动作
- 可通过组合方式对任意服务进行组合,统一管理
具体类请参见 org.apache.hadoop.service包下.核心接口是Service,抽象实现是AbstractService
YARN中,ResourceManager和NodeManager属于组合服务,内部包含多个单一和组合服务.以实现对内部多种服务的统一管理.
Hadoop事件库:
YARN采用事件驱动并发模型, 把各种逻辑抽象成事件,进入事件队列,然后由中央异步调度器负责传递给相应的事件调度器处理,或者调度器之间再传递,直至完成任务.
具体参见org.apache.hadoop.yarn.event.主要类和接口是:Event, AsyncDispatcher,EventHandler
按照惯例, 先给出一个Demo,然后顺着Demo研究代码实现.
示例我是直接抄<hadoop技术内幕>:
例子涉及如下几个模块:
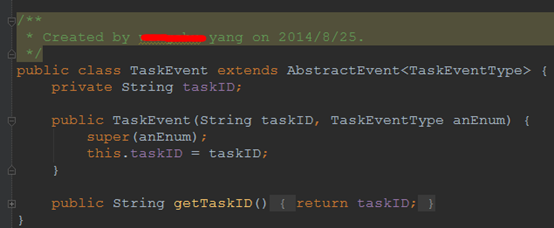
- Task
- TaskType
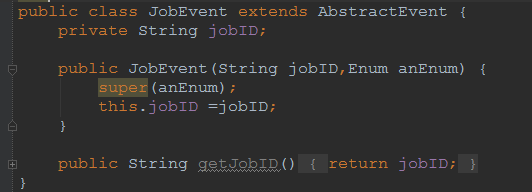
- Job
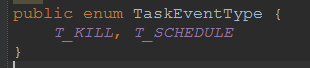
- JobType

- Dispatcher
|
package
import org.apache.hadoop.conf.Configuration; import import import import import
/** * Created by yang on 2014/8/25. */ public
private private String jobID; private private String[] taskIDs;
public SimpleService(String name, String jobID, int super(name); this.jobID = jobID; this.taskNum = taskNum; this.taskIDs = new String[taskNum];
for (int taskIDs[i] = new String(jobID + "_task_" + i); } }
public return }
public dispatcher = new dispatcher.register(JobEventType.class, new JobEventDIspatcher()); dispatcher.register(TaskEventType.class, new TaskEventDIspatcher()); addService((Service)dispatcher); super.serviceInit(conf); }
private
@Override public if (jobEvent.getType() == JobEventType.JOB_KILL) { System.out.println("JOB KILL EVENT"); for (int dispatcher.getEventHandler().handle(new } } else System.out.println("JOB INIT EVENT"); for (int dispatcher.getEventHandler().handle(new } } } }
private
@Override public if (taskEvent.getType() == TaskEventType.T_KILL) { System.out.println("TASK KILL EVENT" + taskEvent.getTaskID()); } else System.out.println("TASK INIT EVENT" + taskEvent.getTaskID()); } } } } |
- 测试程序
|
package
import org.apache.hadoop.conf.Configuration; import
/** * Created by yang on 2014/8/25. */ public public String jobID="job_1"; SimpleService YarnConfiguration
ss.serviceInit(config); ss.init(config); ss.start();
ss.getDispatcher().getEventHandler().handle(new ss.getDispatcher().getEventHandler().handle(new } } |
不出意外的话,运行结果应该类似:
|
14/08/25 16:02:20 INFO event.AsyncDispatcher: Registering class com.yws.demo1.JobEventType for class com.yws.demo1.SimpleService$JobEventDIspatcher 14/08/25 16:02:42 INFO event.AsyncDispatcher: Registering class com.yws.demo1.TaskEventType for class com.yws.demo1.SimpleService$TaskEventDIspatcher 14/08/25 16:02:54 INFO event.AsyncDispatcher: Registering class com.yws.demo1.JobEventType for class com.yws.demo1.SimpleService$JobEventDIspatcher 14/08/25 16:03:03 INFO event.AsyncDispatcher: Registering class com.yws.demo1.TaskEventType for class com.yws.demo1.SimpleService$TaskEventDIspatcher JOB KILL EVENT JOB KILL EVENT TASK KILL EVENTjob_1_task_0 TASK KILL EVENTjob_1_task_1 TASK KILL EVENTjob_1_task_2 TASK KILL EVENTjob_1_task_3 TASK KILL EVENTjob_1_task_4 TASK KILL EVENTjob_1_task_0 TASK KILL EVENTjob_1_task_1 TASK KILL EVENTjob_1_task_2 TASK KILL EVENTjob_1_task_3 TASK KILL EVENTjob_1_task_4 |
我们开始分析:
所谓的Task,Job,其实是按业务逻辑划分的, 他们都继承AbstractEvent类.
SimpleService是一个组合服务,里面放了EventHandler和Dispatcher
从Test开始,看看Service是如何创建的
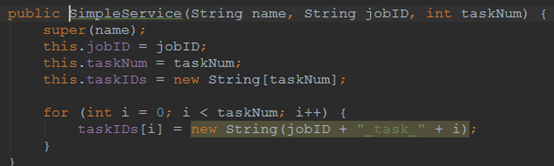
构造函数比较简单,就是将一个job拆分成taskNum个Task
ss.serviceInit(config);做了什么呢:

创建一个中央事件调度器: AsyncDispatcher(具体实现我们在后文分析)
并把Job和Task的Event及2者对应的EventHandler注册到调度器中.

这里就是初始化和启动服务了.最后2行就是模拟2个事件的JOB_KILL事件.
我们进到ss.getDispatcher().getEventHandler(),发现他其实是创建一个GenericEventHandler
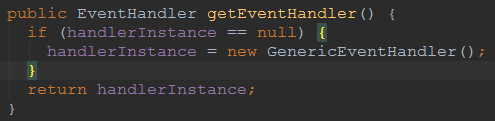
这个handler干什么是呢?
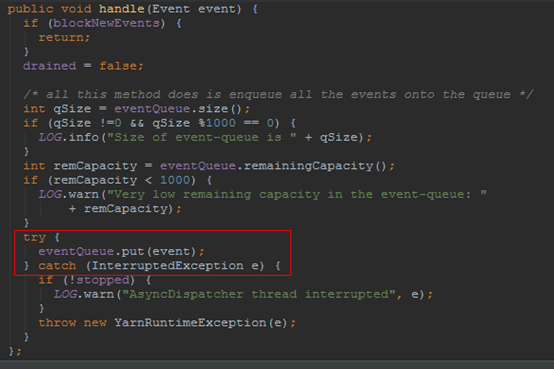
就是把

塞到BlockingQueue<Event> eventQueue; 中.
不知道你发现没有, 这个方法仅仅是一个入队操作啊. 那具体调用JobEventDIspatcher.handler是在什么地方呢?
这时联想到之前不是有个中央调度器嘛, AsyncDispatcher, Line 80行, 他创建了一个线程,并不断的从之前说的EventQueue中不断的取Event,然后执行,这里的执行也就是调用了具体的handler了
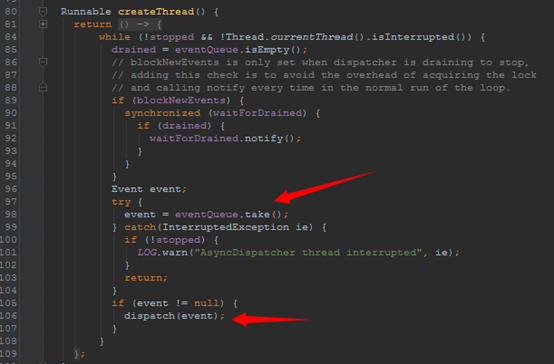
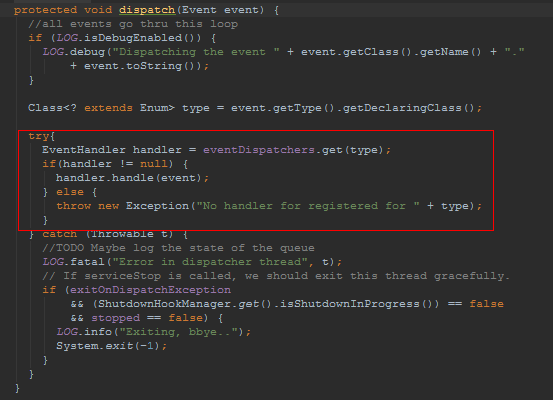
就这样一个基于事件驱动的程序这么完成了.
按照hadoop 早起版本中, 业务逻辑之间是通过函数调用方式实现的,也就是串行的. 现在基于事件驱动后,大大提高了并发性.很值得我们学习.
来张全家福:
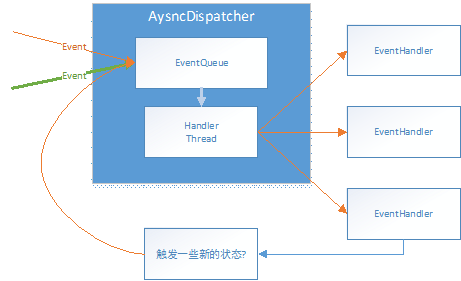
HandlerThread就是前文说的那个隐藏线程. EventHandler会产生一些新的Event,然后又重新进入队列.循环.
Hadoop服务库与事件库的使用及其工作流程的更多相关文章
- Hadoop2源码分析-YARN 的服务库和事件库
1.概述 在<Hadoop2源码分析-YARN RPC 示例介绍>一文当中,给大家介绍了YARN 的 RPC 机制,以及相关代码的演示,今天我们继续去学习 YARN 的服务库和事件库,分享 ...
- 【深入浅出 Yarn 架构与实现】2-3 Yarn 基础库 - 服务库与事件库
一个庞大的分布式系统,各个组件间是如何协调工作的?组件是如何解耦的?线程运行如何更高效,减少阻塞带来的低效问题?本节将对 Yarn 的服务库和事件库进行介绍,看看 Yarn 是如何解决这些问题的. 一 ...
- Yarn的服务库和事件库使用方法
事件类型定义: package org.apache.hadoop.event; public enum JobEventType { JOB_KILL, JOB_INIT, JOB_START } ...
- 服务容错保护断路器Hystrix之二:Hystrix工作流程解析
一.总运行流程 当你发出请求后,hystrix是这么运行的 红圈 :Hystrix 命令执行失败,执行回退逻辑.也就是大家经常在文章中看到的“服务降级”. 绿圈 :四种情况会触发失败回退逻辑( fal ...
- Yarn的服务库和事件库
对于生命周期较长的对象,YARN采用了基于服务对象管理模型对其进行管理. 该模型有一下特点: 每个被服务化的对象都分为4个状态 任何服务状态变化都可以触发另外一些动作 可以通过组合方式对任意服务进行组 ...
- 【深入浅出 Yarn 架构与实现】2-2 Yarn 基础库 - 底层通信库 RPC
RPC(Remote Procedure Call) 是 Hadoop 服务通信的关键库,支撑上层分布式环境下复杂的进程间(Inter-Process Communication, IPC)通信逻辑, ...
- 利用epoll写一个"迷你"的网络事件库
epoll是linux下高性能的IO复用技术,是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率.另一点原因就是获取 ...
- libevent库介绍--事件和数据缓冲
首先在学习libevent库的使用前,我们还要从基本的了解开始,已经熟悉了epoll以及reactor,然后从event_base学习,依次学习事件event.数据缓冲Bufferevent和数据封装 ...
- ktouch移动端事件库
最近闲来无事,写了个移动端的事件库,代码贴在下面,大家勿拍. /** @version 1.0.0 @author gangli @deprecated 移动端触摸事件库 */ (function ( ...
随机推荐
- Curator的cluster,实现多节点数据共享
模拟两个客户端,实现多节点数据共享 package bjsxt.curator.cluster; import org.apache.curator.RetryPolicy; import org.a ...
- 100-days: seventeen
Title: How 'Bohemian Rhapsody(波西米亚狂想曲)' ended up in 'Wayne's World(反斗智多星)' and became a phenomenon(现 ...
- 【python深入】collections-Counter使用总结
关于collections的使用,首先介绍:Counter的使用 需要执行:from collections import Counter 在很多使用到dict和次数的场景下,Python中用Coun ...
- Python练习-迭代-2018.11.28
#遍历list L=['a','b','c','d'] l=[] a=0 for n in L: l.insert(a,n) a=a+1 print(l) #遍历dict里的key,导出为list L ...
- java ssh执行shell脚本
1.添加依赖 com.jcraft:jsch ch.ethz.ganymed:ganymed-ssh2:262 2.获取连接 conn = new Connection(ip, port); conn ...
- Python开发——数据类型【列表】
列表的定义 中括号[]内以逗号分隔开,按照索引,存放各种数据类型,每个位置代表一个元素 list_t = ['张三','Lucy',123] print(list_t) # ['张三', 'Lucy' ...
- linux resin 安装 配置 相关
resin跟tomcat一样,也是解析jsp网站的,也需要JDK的支持,所以第一步也是安装JDK,安装JDK的方法参考Tomcat中的安装JDK部分.下面介绍安装resin.resin官网http:/ ...
- Android 记录点滴
1:关于断点 设置断点点三角是进不去的,这个是类似c#的release 正式版, 点第二个红圈内的debug的那个按钮才可以 . 这个按钮可以让程序及时进入当前断点处 2:对于背景颜色 andro ...
- nginx路径设置(web)
原文 https://www.jianshu.com/p/57db2c5d0cb9 语法 root 语法:root path 默认值:root html 配置段:http.server.locatio ...
- TCP编程
Socket是网络编程的一个抽象概念,通常我们用一个Socket表示“打开了一个网络连接”,而打开一个Socket需要知道目标计算机的IP地址和端口号,在指定协议类型即可. 客户端 大多数连接就是考的 ...