etcdv3 集群的搭建和使用
etcd是一个开源的分布式键值对数据库,他的每一个节点都有一份数据的copy,当有节点故障时保证了高可用性。etcd使用Raft算法来保证一致性。
第一次接触etcd是在学习k8s时。k8s用etcd做的服务发现。后来在开发一个分布式系统时需要用到服务发现,就想试一下用etcd做服务发现。效果还是很不错的。
这篇讲一下etcd集群的搭建和使用。
集群的节点个数和容错
官方推荐的集群个数为奇数个,如图当节点为3个和为4个时的容错都是1, 节点5个和6个时,容错为2...

集群的节点越多,容错性会越强,但是数据的同步份数也会越多,写性能会变差一些。合理的集群大小,就是平衡容错性和可写性。
安装集群
准备三台服务器
172.31.43.166 |
etcd0 |
172.31.43.114 |
etcd1 |
172.31.34.237 |
etcd2 |
分别在三台服务器上下载etcd。这里下载的是版本3.3.8
ETCD_VER=v3.3.8 GITHUB_URL=https://github.com/coreos/etcd/releases/download
DOWNLOAD_URL=${GITHUB_URL} rm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
rm -rf /tmp/etcd-download-test && mkdir -p /tmp/etcd-download-test curl -L ${DOWNLOAD_URL}/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz -o /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
tar xzvf /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz -C /tmp/etcd-download-test --strip-components=
rm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz /tmp/etcd-download-test/etcd --version
ETCDCTL_API= /tmp/etcd-download-test/etcdctl version
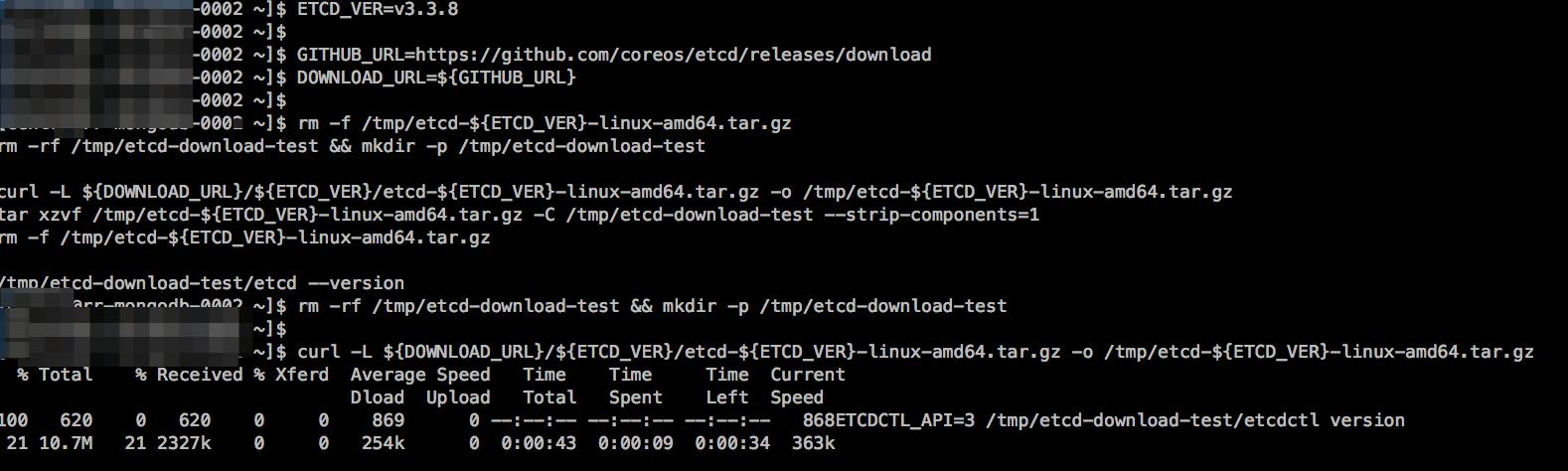

然后将两个文件都放到系统可执行目录 /usr/local/bin/ 或 /usr/bin/
cd /tmp/etcd-download-test
sudo cp etcd* /usr/local/bin/
创建一个文件夹用来保存etcd的数据
sudo mkdir -p /data/etcd
sudo chown -R root:$(whoami) /data/etcd
sudo chmod -R a+rw /data/etcd
在这里我使用static方式去搭建服务。
编写systemd服务文件,分别在每台机器上编写服务文件:
cat > /tmp/etcd0.service <<EOF
[Unit]
Description=etcd
Documentation=https://github.com/coreos/etcd
Conflicts=etcd.service
Conflicts=etcd2.service
[Service]
Type=notify
Restart=always
RestartSec=5s
LimitNOFILE=40000
TimeoutStartSec=0
ExecStart=/usr/local/bin/etcd --name etcd0 \
--data-dir /data/etcd \
--initial-advertise-peer-urls http://172.31.43.166:2380 \
--listen-peer-urls http://172.31.43.166:2380 \
--listen-client-urls http://172.31.43.166:2379,http://127.0.0.1:2379 \
--advertise-client-urls http://172.31.43.166:2379 \
--initial-cluster-token etcd-cluster-pro \
--initial-cluster etcd0=http://172.31.43.166:2380,etcd1=http://172.31.43.114:2380,etcd2=http://172.31.34.237:2380 \
--initial-cluster-state new
[Install]
WantedBy=multi-user.target
EOF
sudo mv /tmp/etcd0.service /etc/systemd/system/etcd0.service
cat > /tmp/etcd1.service <<EOF
[Unit]
Description=etcd
Documentation=https://github.com/coreos/etcd
Conflicts=etcd.service
Conflicts=etcd2.service
[Service]
Type=notify
Restart=always
RestartSec=5s
LimitNOFILE=40000
TimeoutStartSec=0
ExecStart=/usr/local/bin/etcd --name etcd1 \
--data-dir /data/etcd \
--initial-advertise-peer-urls http://172.31.43.114:2380 \
--listen-peer-urls http://172.31.43.114:2380 \
--listen-client-urls http://172.31.43.114:2379,http://127.0.0.1:2379 \
--advertise-client-urls http://172.31.43.114:2379 \
--initial-cluster-token etcd-cluster-pro \
--initial-cluster etcd0=http://172.31.43.166:2380,etcd1=http://172.31.43.114:2380,etcd2=http://172.31.34.237:2380 \
--initial-cluster-state new
[Install]
WantedBy=multi-user.target
EOF
sudo mv /tmp/etcd1.service /etc/systemd/system/etcd1.service
cat > /tmp/etcd2.service <<EOF
[Unit]
Description=etcd
Documentation=https://github.com/coreos/etcd
Conflicts=etcd.service [Service]
Type=notify
Restart=always
RestartSec=5s
LimitNOFILE=
TimeoutStartSec= ExecStart=/usr/local/bin/etcd -name etcd2 \
--data-dir /data/etcd \
--initial-advertise-peer-urls http://172.31.34.237:2380 \
--listen-peer-urls http://172.31.34.237:2380 \
--listen-client-urls http://172.31.34.237:2379,http://127.0.0.1:2379 \
--advertise-client-urls http://172.31.34.237:2379 \
--initial-cluster-token etcd-cluster-pro \
--initial-cluster etcd0=http://172.31.43.166:2380,etcd1=http://172.31.43.114:2380,etcd2=http://172.31.34.237:2380 \
--initial-cluster-state new [Install]
WantedBy=multi-user.target
EOF
sudo mv /tmp/etcd2.service /etc/systemd/system/etcd2.service
下面是一些常用配置选项的说明:
--name:方便理解的节点名称,默认为 default,在集群中应该保持唯一
--data-dir:服务运行数据保存的路径,默认为 ${name}.etcd
--snapshot-count:指定有多少事务(transaction)被提交时,触发截取快照保存到磁盘
--heartbeat-interval:leader 多久发送一次心跳到 followers。默认值是 100ms
--eletion-timeout:重新投票的超时时间,如果follower在该时间间隔没有收到心跳包,会触发重新投票,默认为 1000 ms
--listen-peer-urls:和同伴通信的地址,比如 http://ip:2380,如果有多个,使用逗号分隔。需要所有节点都能够访问,所以不要使用 localhost
--advertise-client-urls:对外公告的该节点客户端监听地址,这个值会告诉集群中其他节点
--listen-client-urls:对外提供服务的地址:比如 http://ip:2379,http://127.0.0.1:2379,客户端会连接到这里和etcd交互
--initial-advertise-peer-urls:该节点同伴监听地址,这个值会告诉集群中其他节点
--initial-cluster:集群中所有节点的信息,格式为 node1=http://ip1:2380,node2=http://ip2:2380,…。需要注意的是,这里的 node1 是节点的--name指定的名字;后面的ip1:2380 是--initial-advertise-peer-urls 指定的值
--initial-cluster-state:新建集群的时候,这个值为 new;假如已经存在的集群,这个值为existing
--initial-cluster-token:创建集群的token,这个值每个集群保持唯一。这样的话,如果你要重新创建集群,即使配置和之前一样,也会再次生成新的集群和节点 uuid;否则会导致多个集群之间的冲突,造成未知的错误
所有以--init开头的配置都是在第一次启动etcd集群的时候才会用到,后续节点的重启会被忽略,如--initial-cluseter参数。所以当成功初始化了一个etcd集群以后,就不再需要这个参数或环境变量了。
如果服务已经运行过就要把修改 --initial-cluster-state 为existing
启用服务
sudo systemctl daemon-reload
sudo systemctl enable etcd0.service
sudo systemctl start etcd0.service sudo systemctl daemon-reload
sudo systemctl enable etcd1.service
sudo systemctl start etcd1.service sudo systemctl daemon-reload
sudo systemctl enable etcd2.service
sudo systemctl start etcd2.service
查看 log:
sudo systemctl status etcd0.service -l --no-pager
sudo journalctl -u etcd0.service -l --no-pager|less
sudo journalctl -f -u etcd0.service sudo systemctl status etcd1.service -l --no-pager
sudo journalctl -u etcd1.service -l --no-pager|less
sudo journalctl -f -u etcd1service sudo systemctl status etcd2.service -l --no-pager
sudo journalctl -u etcd2.service -l --no-pager|less
sudo journalctl -f -u etcd2.service
暂停
sudo systemctl stop etcd0.service
sudo systemctl disable etcd0.service sudo systemctl stop etcd1.service
sudo systemctl disable etcd1.service sudo systemctl stop etcd2.service
sudo systemctl disable etcd2.service
使用etcd
我使用的etcd的api为v3版本。在使用命令时需要在前面加上ETCDCTL_API=3
如:查看集群成员
ETCDCTL_API= etcdctl member list

可以看到有3个节点在线
集群状态
ETCDCTL_API= etcdctl --endpoints 172.31.43.166:,172.31.34.237:,172.31.43.114: endpoint status --write-out="table"

操作数据
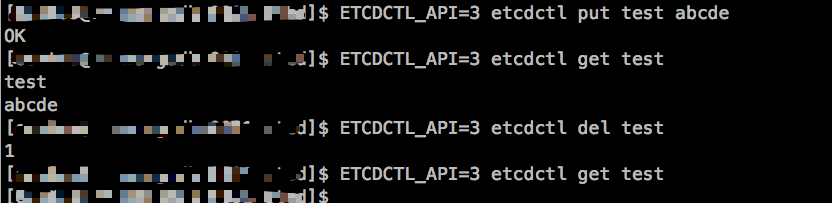
使用put和get命令可以保存和得到数据.del删除数据
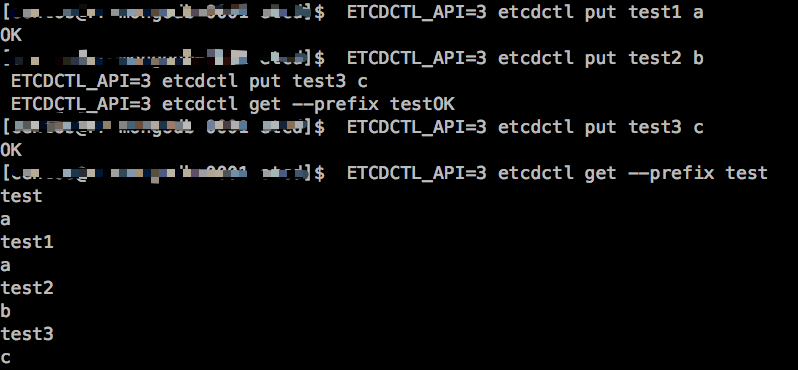
根据前缀查询
ETCDCTL_API= etcdctl put test1 a
ETCDCTL_API= etcdctl put test2 b
ETCDCTL_API= etcdctl put test3 c
ETCDCTL_API= etcdctl get --prefix test
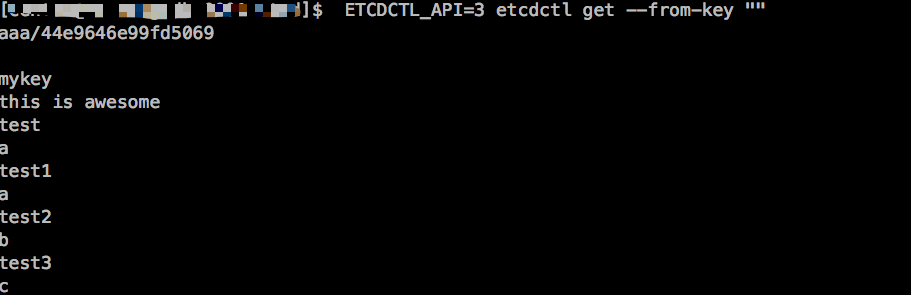
查询所有数据
ETCDCTL_API= etcdctl get --from-key ""
watch 监听
watch 会监听key的变动 有变动时会在输出。这也正是服务发现需要使用的。
我们监听 test键,然后对test执行修改和删除操作
ETCDCTL_API= etcdctl watch test

ETCDCTL_API= etcdctl put test abcde
ETCDCTL_API= etcdctl put test aaaa
ETCDCTL_API= etcdctl del test
lead 租约
etcd可以为key设置超时时间,但与redis不同,etcd需要先创建lease,然后使用put命令加上参数–lease=<lease ID>
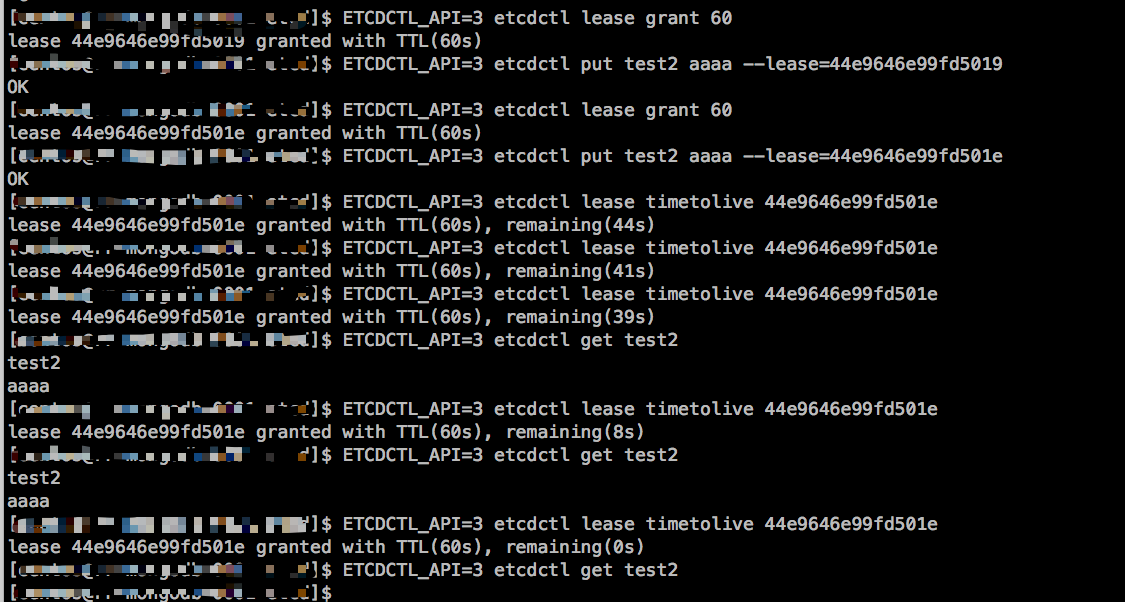
ETCDCTL_API=3 lease grant ttl 创建lease,返回lease ID ttl秒
ETCDCTL_API=3 lease revoke leaseId 删除lease,并删除所有关联的key
ETCDCTL_API=3 lease timetolive leaseId 取得lease的总时间和剩余时间
ETCDCTL_API=3 lease keep-alive leaseId keep-alive会不间断的刷新lease时间,从而保证lease不会过期。
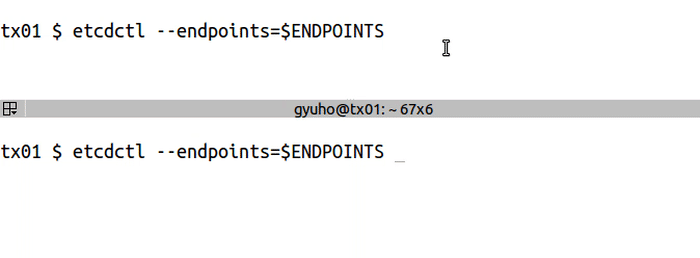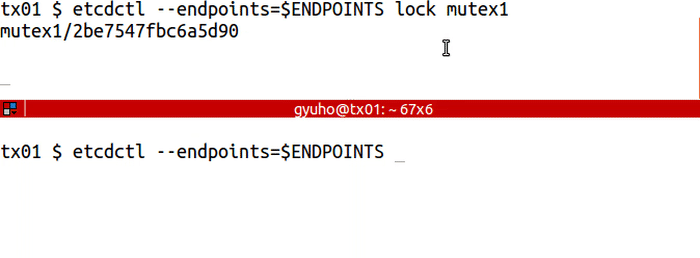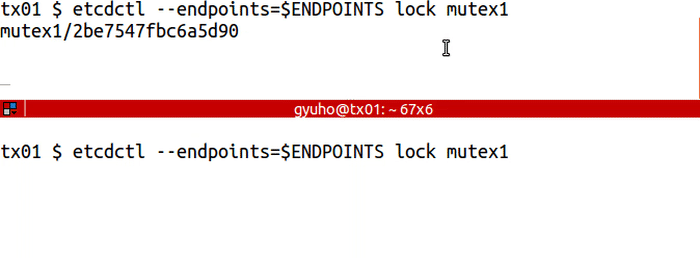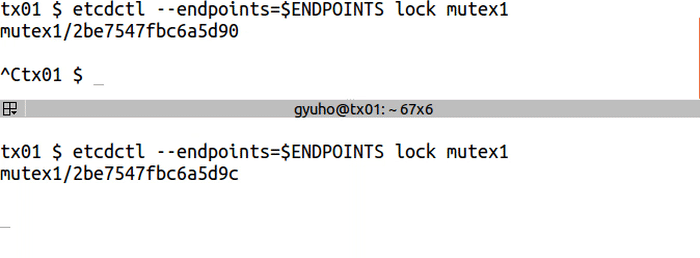
分布式锁
使用lock命令后加锁名称 做分布式锁,如果没有显示释放锁,其他地方只能等待。
etcdctl --endpoints=$ENDPOINTS lock mutex1 # 在另一个终端输入
etcdctl --endpoints=$ENDPOINTS lock mutex1
etcdv3 集群的搭建和使用的更多相关文章
- zookeeper集群的搭建以及hadoop ha的相关配置
1.环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 master作为active主机,data1作为standby备用机,三台机器均作为数据节点,yarn资源 ...
- 朝花夕拾之--大数据平台CDH集群离线搭建
body { border: 1px solid #ddd; outline: 1300px solid #fff; margin: 16px auto; } body .markdown-body ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- linux环境(CentOS-6.7)下redis集群的搭建全过程
linux环境下redis集群的搭建全过程: 使用mount命令将光盘挂载到/mnt/cdrom目录下: [root@hadoop03 ~]# mount -t iso9660 -o ro /dev/ ...
- 【redis】 linux 下redis 集群环境搭建
Redis集群 (要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对应的redis节点的ip和端口对应关系如下) 127.0.0.1:63791 ...
- 项目进阶 之 集群环境搭建(三)多管理节点MySQL集群
上次的博文项目进阶 之 集群环境搭建(二)MySQL集群中,我们搭建了一个基础的MySQL集群,这篇博客咱们继续讲解MySQL集群的相关内容,同时针对上一篇遗留的问题提出一个解决方案. 1.单管理节点 ...
- [原]项目进阶 之 集群环境搭建(二)MySQL集群
上次的博文中我们介绍了一下集群的相关概念,今天的博文我们介绍一下MySQL集群的相关内容. 1.MySQL集群简介 MySQL群集技术在分布式系统中为MySQL数据提供了冗余特性,增强了安全性,使得单 ...
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- Solr集群的搭建以及使用(内涵zookeeper集群的搭建指南)
1 什么是SolrCloud SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud.当一个系统的索引数据量少的时候 ...
随机推荐
- TF:TF分类问题之MNIST手写50000数据集实现87.4%准确率识别:SGD法+softmax法+cross_entropy法—Jason niu
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # number 1 to 10 ...
- POJ1700----Crossing River
#include<cstdio> #include<iostream> #include<cstring> #include<algorithm> us ...
- java 分布式与集群的区别和联系(转)
本文主要介绍了java分布式与集群的区别和联系,具有很好的参考价值,下面跟着小编一起来看下吧 一.先说区别: 一句话:分布式是并联工作的,集群是串联工作的. 1.分布式是指将不同的业务分布在不同的地方 ...
- 几个比较很重要的Shader相关教程
1. 论坛上有个兄弟写个的ToonShaderModel,可以参考ShaderModelhttps://github.com/EpicGames/UnrealEngine/pull/1552/file ...
- Codeforces.1088D.Ehab and another another xor problem(交互 思路)
题目链接 边颓边写了半上午A掉啦233(本来就是被无数人过掉的好吗→_→) 首先可以\(Query\)一次得到\(a,b\)的大小关系(\(c=d=0\)). 然后发现我们是可以逐位比较出\(a,b\ ...
- 英语口语练习系列-C31-图书-谈论事物-白雪歌送武判官归京
book your favorite book a story in your childhood a character in film or TV 词汇 含义 备注 trend 趋势 indivi ...
- 潭州课堂25班:Ph201805201 django框架 第十三课 自定义404页面,auth系统中的User模型,auth系统权限管理 (课堂笔记)
当 DEBUG=True 时,django 内部的404报错信息, 自带的报错信息, 要自定义404信息,要先把 DEBUG=False , 之后要自定义4040页面,有两种方法, 方法1,在创建40 ...
- 潭州课堂25班:Ph201805201 django框架 第六课 模型类增删改查,常用 的查询矣查询条件 (课堂笔记)
在视图函数中写入增删改查的方法 增: 在 urls 中配置路径 : 查: 1: 在后台打印数据 在模型类中添加格式化输出 : QuerySet,反回的是个对象,可以按索引聚会,用 for 循环,, 找 ...
- [CQOI2005]三角形面积并
[CQOI2005]三角形面积并 题目大意: 求\(n(n\le100)\)个三角形的面积并. 思路: 自适应辛普森法,玄学卡精度可过. 源代码: #include<cmath> #inc ...
- BZOJ4681 : [Jsoi2010]旅行
将边按权值从小到大排序. 考虑一条路径,一定是最大的若干条边和最小的相应的没选的边进行交换. 这会导致存在一个分界线$L$,交换之后恰好选中前$L$小的边,且只允许$>L$的边与$\leq L$ ...