Java容器解析系列(5) AbstractSequentialList LinkedList 详解
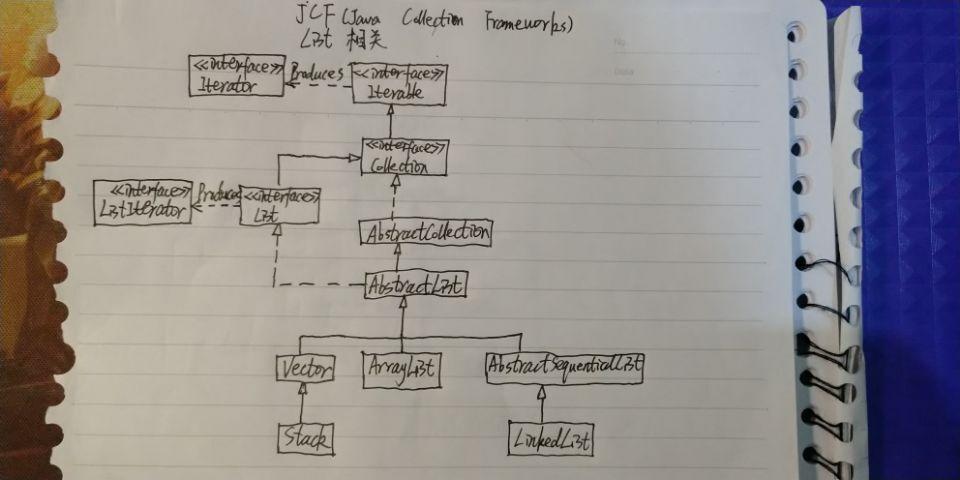
AbstractSequentialList为顺序访问的list提供了一个骨架实现,使实现顺序访问的list变得简单;
我们来看源码:
/**
AbstractSequentialList 继承自 AbstractList,是 List 接口的简化版实现。只支持按顺序访问,而不像 AbstractList 那样支持随机访问。
如果要支持随机访问,应该继承自AbstractList;
想要实现一个支持按次序访问的List的话,只需要继承该类并实现size()和listIterator()方法;
如果要实现的是不可修改的list,和listIterator()方法返回的 ListIterator 需要实现hasNext(), hasPrevious(), next(), previous(), 还有那几个 获取index 的方法;
如果要实现的是可修改的list,ListIterator还需要实现set()方法;
如果要实现的的list大小可变,ListIterator还需要实现add()和remove()方法;
* @since 1.2
*/
public abstract class AbstractSequentialList<E> extends AbstractList<E> {
protected AbstractSequentialList() {}
public E get(int index) {
try {
return listIterator(index).next();
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
public E set(int index, E element) {
try {
ListIterator<E> e = listIterator(index);
E oldVal = e.next();
e.set(element);
return oldVal;
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
public void add(int index, E element) {
try {
listIterator(index).add(element);
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
public E remove(int index) {
try {
ListIterator<E> e = listIterator(index);
E outCast = e.next();
e.remove();
return outCast;
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
public boolean addAll(int index, Collection<? extends E> c) {
try {
boolean modified = false;
ListIterator<E> e1 = listIterator(index);
Iterator<? extends E> e2 = c.iterator();
while (e2.hasNext()) {
e1.add(e2.next());
modified = true;
}
return modified;
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
// 这里通过调用listIterator()返回ListIterator
public Iterator<E> iterator() {
return listIterator();
}
public abstract ListIterator<E> listIterator(int index);
}
从上面源码可以看出:
- 所有在AbstractSequentialList默认实现的方法,内部都调用了listIterator()来实现(iterator()也是调用listIterator()来实现),并以其返回的ListIterator作为实现基础;
- 与AbstractList不同的是,AbstractSequentialList因为是顺序访问,所以其ListIterator内的方法实现不能像AbstractList那样通过add()/remove()/set()/get()/size()方法来实现(这样会导致效率极其低下),istIterator(int)为一个抽象方法,其子类必须提供其对应的ListIterator;
接下来我们把目光转到AbstractSequentialList的实现类之一-----LinkedList.
翻开原来的笔记,发现有一篇收藏博客对LinkedList讲解非常好( ̄□ ̄||),这里贴一下地址:
从源码角度彻底搞懂LinkedList
这篇博客把整个LinkedList源码都研究了一遍,但是其中有1点需要纠正:
- 插入和删除比较快(O(1)),查询则相对慢一些(O(n))
这里对于插入和删除的算法时间复杂度表述为O(1),这个可以是被广泛认为如此,其实并不正确.我们来看源码:
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
public void addFirst(E e) {
linkFirst(e);
}
public boolean add(E e) {
linkLast(e);
return true;
}
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
在链表的开始或结束位置进行添加或删除节点,其时间复杂度确实为O(1),但是,如果对中间的某个节点进行添加或删除呢?
// 时间复杂度O(n)
// 遍历查找指定位置的数据
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
add(int,E)和remove(int)方法都通过node(int)方法寻找元素,而node(int)方法的时间复杂度为O(n),也即查找指定index位置的元素的时间复杂度. 所以add(int,E)和remove(int)的时间复杂度也应该是O(n);
很多人认为链表插入和删除的算法时间复杂度为O(1),就是忽略了这个查找的过程;
OK,我们就可以得出结论
LinkedList在添加或删除元素时,如果不指定index(开始或结束位置)添加或删除节点,时间复杂度为O(1);如果指定index添加或删除元素,时间复杂度为O(n)
记得我们之前讲过的ArrayList的添加或删除的时间复杂度为O(n),其实和LinkedList的时间复杂度是一致的:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
// 如果在最后添加,那么这里根本不需要移动元素,时间复杂度为O(1)
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
// 移动index之后的数据,该步骤的时间复杂度为O(n)
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
// 如果在最后删除,那么这里根本不需要移动元素,时间复杂度为O(1)
if (numMoved > 0)
// 移动index之后的数据,该步骤的时间复杂度为O(n)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // Let gc do its work
return oldValue;
}
那么,难道这两者在添加和删除元素的时候就没有什么区别了吗?当然不是:
1. LinkedList添加和删除时间复杂度为O(n),是因为查找指定位置元素的时间复杂度为O(n);
2. ArrayList添加和删除时间复杂度为O(n),是因为移动元素位置的时间复杂度为O(n);
3. 一次移动元素位置比一次元素查看更加耗时;
4. 在LinkedList.ListIterator遍历过程中,因为已经知道了前一个元素和后一个元素,并不需要查询元素位置,此时间复杂度为O(1);
5. 在ArrayList.ListIterator遍历过程中,时间复杂度仍为O(n);
- LinkedList与ArrayList的比较:
ArrayList
1. 基于数组,ArrayList 获取指定位置元素的时间复杂度是O(1);
2. 但是添加、删除元素时,该元素后面的所有元素都要移动,所以添加/删除数据效率不高;
3. 每次达到阈值需要扩容,这个操作比较影响效率。
LinkedList
1. 基于双端链表,添加/删除元素只会影响周围的两个节点,开销比ArrayList低;
2. 只能顺序遍历,无法按照索引获得元素,因此查询效率不高;(get(int)方法内部也是顺序遍历实现)
3. 没有固定容量,不需要扩容;
4. 需要更多的内存,LinkedList 每个节点中需要多存储前后节点的指针,占用空间更多些。
因此,在表需要频繁地添加和删除元素时,还是应该使用LinkedList.如果更多的是按照索引获得元素,应该使用ArrayList
关于按照索引获得元素的效率比较,可以查看博客:
ArrayList遍历方式以及效率比较
建议调试其中的代码,修改LinkedList运行次数和大小,你会为结果感到惊讶
Java容器解析系列(5) AbstractSequentialList LinkedList 详解的更多相关文章
- Java容器解析系列(10) Map AbstractMap 详解
前面介绍了List和Queue相关源码,这篇开始,我们先来学习一种java集合中的除Collection外的另一个分支------Map,这一分支的类图结构如下: 这里为什么不先介绍Set相关:因为很 ...
- Java容器解析系列(0) 开篇
最近刚好学习完成数据结构与算法相关内容: Data-Structures-and-Algorithm-Analysis 想结合Java中的容器类加深一下理解,因为之前对Java的容器类理解不是很深刻, ...
- Java容器解析系列(11) HashMap 详解
本篇我们来介绍一个最常用的Map结构--HashMap 关于HashMap,关于其基本原理,网上对其进行讲解的博客非常多,且很多都写的比较好,所以.... 这里直接贴上地址: 关于hash算法: Ha ...
- Java容器解析系列(7) ArrayDeque 详解
ArrayDeque,从名字上就可以看出来,其是通过数组实现的双端队列,我们先来看其源码: /** 有自动扩容机制; 不是线程安全的; 不允许添加null; 作为栈使用时比java.util.Stac ...
- Java容器解析系列(6) Queue Deque AbstractQueue 详解
首先我们来看一下Queue接口: /** * @since 1.5 */ public interface Queue<E> extends Collection<E> { / ...
- Java容器解析系列(4) ArrayList Vector Stack 详解
ArrayList 这里关于ArrayList本来都读了一遍源码,并且写了一些了,突然在原来的笔记里面发现了收藏的有相关博客,大致看了一下,这些就是我要写的(╹▽╹),而且估计我还写不到博主的水平,这 ...
- Java容器解析系列(3) List AbstractList ListIterator RandomAccess fail-fast机制 详解
做为数据结构学习的常规,肯定是先学习线性表,也就是Java中的List,开始 Java中List相关的类关系图如下: 此篇作为对Java中相关类的开篇.从上图中可以看出,List和AbstractLi ...
- Java容器解析系列(13) WeakHashMap详解
关于WeakHashMap其实没有太多可说的,其与HashMap大致相同,区别就在于: 对每个key的引用方式为弱引用; 关于java4种引用方式,参考java Reference 网上很多说 弱引用 ...
- Java容器解析系列(9) PrioriyQueue详解
PriorityQueue:优先级队列; 在介绍该类之前,我们需要先了解一种数据结构--堆,在有些书上也直接称之为优先队列: 堆(Heap)是是具有下列性质的完全二叉树:每个结点的值都 >= 其 ...
随机推荐
- sublime Text 正则表达式功能使用介绍
sublime Text 正则表达式功能使用介绍 1.打开sublime Text ,然后按 CTRL+H打开替换面板 2.如下图,勾选正则表达式功能,然后填上正则表达式和替换内容. 3.替换后结果如 ...
- Shell 实践、常用脚本
(1)计算1-100的和. #!/bin/bash n= ` do n=$[$i+$n] done echo $n (2)输一个数字,然后计算出1到数字的和,要求如果输入数字小于1,则重新输入,知道输 ...
- 网站基础html javascript jquery
第二章HTML HBuilder的使用 边改边看模式 chrome浏览器看. HTML的基本格式 超文本标记语言 HyperText Markup Language HyperText 超文本 Mar ...
- hadoop MR的一些文件归属(包括临时文件存储情况)
https://blog.csdn.net/bxyz1203/article/details/8057810
- Odd Gnome【枚举】
问题 I: Odd Gnome 时间限制: 1 Sec 内存限制: 128 MB 提交: 234 解决: 144 [提交] [状态] [命题人:admin] 题目描述 According to t ...
- 论文阅读:Deep Attentive Tracking via Reciprocative Learning
Deep Attentive Tracking via Reciprocative Learning 2018-11-14 13:30:36 Paper: https://arxiv.org/abs/ ...
- Python:将数组中的元素导出到变量中 (unpacking)
问题 你需要将数组(list)或元组(tuple)中的元素导出到N个变量中. 解决方案 任何序列都可以通过简单的变量赋值方式将其元素分配到对应的变量中,唯一的要求就是变量的数量和结构需要和序列中的结构 ...
- L2-003. 月饼
L2-003. 月饼 月饼是中国人在中秋佳节时吃的一种传统食品,不同地区有许多不同风味的月饼.现给定所有种类月饼的库存量.总售价.以及市场的最大需求量,请你计算可以获得的最大收益是多少. 注意:销售时 ...
- centos7安装bbr
centos7安装bbr 安装 sudo wget --no-check-certificate https://github.com/teddysun/across/raw/master/bbr.s ...
- MDK C++编程说明
1.汇编启动文件的[WEAK]声明仅对C文件符号有效,所以我们编写外设中断服务方法时应该写在C文件中,或者在CPP文件中使用exetrn "C" { }修饰符. 2.C编译器不能直 ...