zeppelin的安装与使用
想起马上就能回家了,心情是按捺不住的激动,唉,还是继续努力吧,其实不希望那么快就回家,感觉回去了就意味着马上就要回来了,人真的是神奇呀
今天我们来使用zeppelin,这个就是可以把我们查找的数据可以图形化的方式显示出来,好了,今天开始我们的任务吧
1.首先我们要下载zeppelin的压缩包,当我们解压之后(这一台主机上面已经安装过了java的环境)
2.修改配置环境
进入conf/
将zeppelin-env.sh.template修改为zeppelin-env.sh
将zeppelin-site.xml.template修改为zeppelin-site.xml

然后我们接下来修改conf/zeppelin-env.sh新增
export SPARK_MASTER_IP=192.168.109.136
export SPARK_LOCAL_IP=192.168.109.136
3.启动zeppelin
进入zeppelin:进入bin目录下执行./zeppelin-daemon.sh start
然后浏览器访问192.168.109.136:8080进入界面
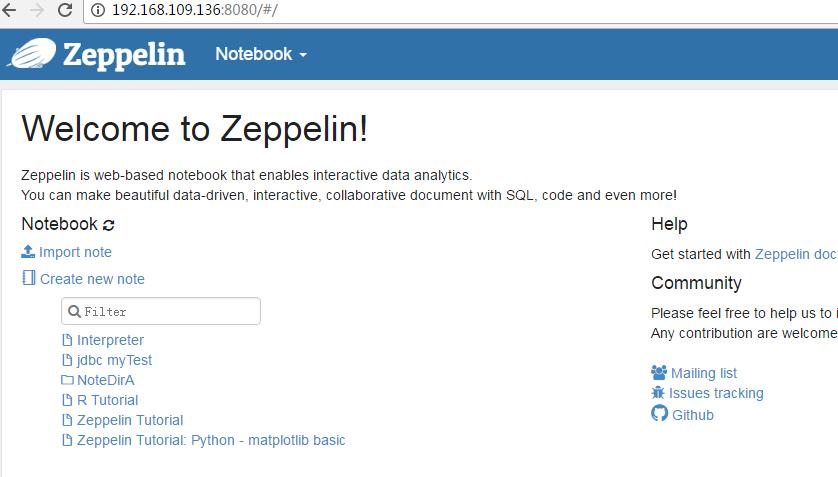
此时就启动成功
4.zeppelin简单实用
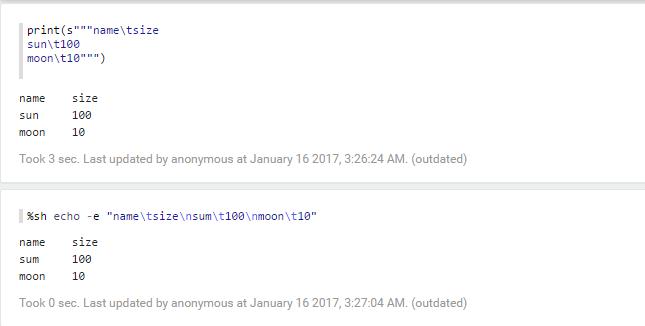
1.text
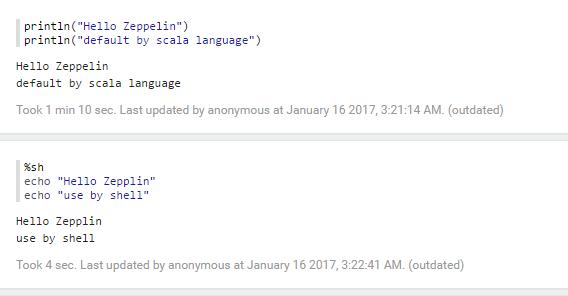
2.html

3.table

5.可以对数据进行分析
对于我做的最多的分析,就是基于学校的那个资料,我有学校里面的信息,这个里面的每一行的信息是以","
进行分隔,这个其中里面的民族,此时我们对这个民族进行分析
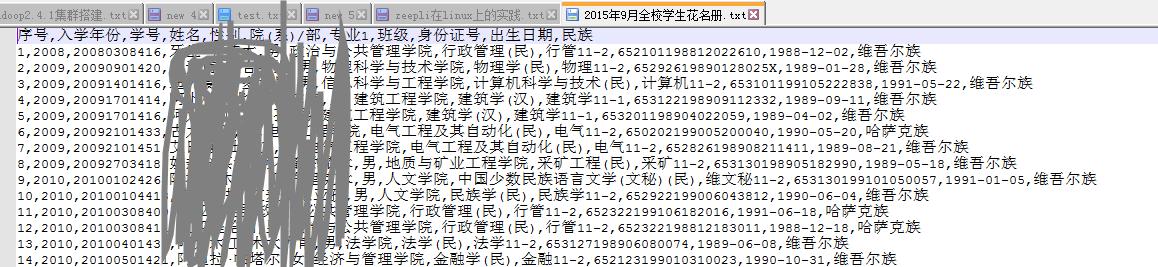
由于我们这个zeppelin是在linux里面的启动,所以我们必须把原有的数据放到linux的里面,此时zeppelin读的文件目录是linux里面的目录
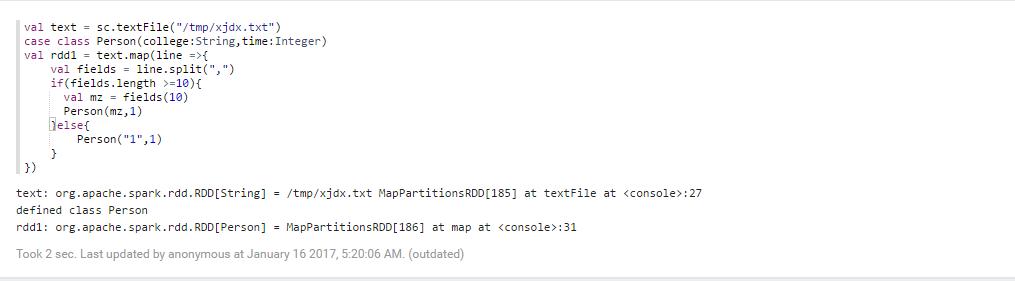



则此时我们就可以对数据库里面的东西进行视图分析,我们通过这个数据,我们发现通过读取数据
,以分组的方式,然后在查询数据有多少个,这样就可以对数据进行显示
a.
val text = sc.textFile("/tmp/xjdx.txt")
case class Person(college:String,time:Integer)
val rdd1 = text.map(line =>{
val fields = line.split(",")
if(fields.length >=){
val mz = fields()
Person(mz,)
}else{
Person("",)
}
})
b.
rdd1.toDF().registerTempTable("rdd1")
c.
%sql select college,count() from rdd1 group by college
这个里面只是针对于存储介质是文件的形式,对于数据库的那个有问题,我会在以后的章节继续介绍的,敬请期待
zeppelin的安装与使用的更多相关文章
- Spark实战2:Zeppelin的安装和SparkSQL使用总结
zeppelin是spark的web版本notebook编辑器,相当于ipython的notebook编辑器. 一Zeppelin安装 (前提是spark已经安装好) 1 下载https://zepp ...
- Zeppelin的安装和SparkSQL使用总结
zeppelin是spark的web版本notebook编辑器,相当于ipython的notebook编辑器. 一Zeppelin安装 (前提是spark已经安装好) 1 下载https://zepp ...
- centos6.5中部署Zeppelin并配置账号密码验证
centos6.5中部署Zeppelin并配置账号密码验证1.安装JavaZeppelin支持的操作系统如下图所示.在安装Zeppelin之前,你需要在部署的服务器上安装Oracle JDK 1.7或 ...
- Ubuntu下基于Saprk安装Zeppelin
前言 Apache Zeppelin是一款基于web的notebook(类似于ipython的notebook),支持交互式地数据分析,即一个Web笔记形式的交互式数据查询分析工具,可以在线用scal ...
- 安装zeppelin
安装zeppelin 1.默认安装好spark集群 2.安装zeppelin 1.解压安装包 tar zxvf zeppelin-0.5.5-incubating-bin-all.tgz 2.配置环境 ...
- 数据可视化工具zeppelin安装
介绍 zeppelin主要有以下功能 数据提取 数据发现 数据分析 数据可视化 目前版本(0.5-0.6)之前支持的数据搜索引擎有如下 安装 环境 centOS 6.6 编译准备工作 sudo yum ...
- NoteBook学习(二)-------- Zeppelin简介与安装
Zeppelin官网地址: http://zeppelin.apache.org/ Github地址: https://github.com/apache/zeppelin (参照官网) 1.什么是z ...
- Zeppelin 学习笔记之 Zeppelin安装和elasticsearch整合
Zeppelin安装: Apache Zeppelin提供了web版的类似ipython的notebook,用于做数据分析和可视化.背后可以接入不同的数据处理引擎,包括spark, hive, taj ...
- zeppelin安装使用
官网:http://zeppelin-project.org/ 代码:https://github.com/NFLabs/zeppelin 使用:按照官网的视频操作一遍,应该就懂了http://y ...
随机推荐
- div多选控制
此点击按钮,弹出DIV,div内容可以多项选择,点击确定,被选项回填至文本框.功能类似之前写过的一篇日期多选,不过是在其基础上,新增点击页面其他区域,隐藏div功能. 1.css部分代码 .multi ...
- Android getRunningTasks和getRunningAppProcesses失效
Android 5.0以上的getRunningTasks失效,该方法可以获得在前台运行的系统进程.可以用getRunningAppProcesses方法暂时替代. android6.0以上的getR ...
- 二种方法安装卸载Windows服务的命令
第一种方法:通过Dos命令安装系统服务1. 开始 运行输入 cmd 进入dos窗口2. cd命令进入到C:\WINDOWS\Microsoft.NET\Framework\v2.0.50727目录下, ...
- Struts2_用DomainModel接收参数
用域模型接收参数 User类 package com.bjsxt.struts2.user.model; public class User { private String name; privat ...
- linux下搭建svn并同步更新至web目录
安装svn 使用yum安装 yum install subversion -y 安装成功后查看版本库 svnserve --version 生成目录 cd /var mkdir svn cd svn ...
- POJ-1159 Palindrome---变成回文串的最小代价
题目链接: https://cn.vjudge.net/problem/POJ-1159 题目大意: 题意很明确,给你一个字符串,可在任意位置添加字符,最少再添加几个字符,可以使这个字符串成为回文字符 ...
- Android(java)学习笔记66:Android Studio中build.gradle简介
1.首先我们直接上代码介绍: // Top-level build file where you can add configuration options common to all sub-pro ...
- #WPF的3D开发技术基础梳理
原文:#WPF的3D开发技术基础梳理 自学WPF已经有半年有余了,一遍用,一边学.但是一直没有去触摸WPF的3D开发相关技术,因为总觉得在内心是一座大山,觉得自己没有能力去逾越.最近因为一个项目的相关 ...
- 在使用HTMLTestRunner时,报告为空,错误提示<_io.TextIOWrapper name='<stderr>' mode='w' encoding='utf_8'>
<_io.TextIOWrapper name='<stderr>' mode='w' encoding='utf_8'> Time Elapsed: 0:00:21.3163 ...
- Node.js 的初体验
例子1: 1.首先第一步 :要 下载 node.js. 官网 上可以下载 下载完后,是这个玩意. 2. 打开 node.js ,然后输入 // 引入http模块 var http = require( ...