zeppelin的安装与使用
想起马上就能回家了,心情是按捺不住的激动,唉,还是继续努力吧,其实不希望那么快就回家,感觉回去了就意味着马上就要回来了,人真的是神奇呀
今天我们来使用zeppelin,这个就是可以把我们查找的数据可以图形化的方式显示出来,好了,今天开始我们的任务吧
1.首先我们要下载zeppelin的压缩包,当我们解压之后(这一台主机上面已经安装过了java的环境)
2.修改配置环境
进入conf/
将zeppelin-env.sh.template修改为zeppelin-env.sh
将zeppelin-site.xml.template修改为zeppelin-site.xml

然后我们接下来修改conf/zeppelin-env.sh新增
export SPARK_MASTER_IP=192.168.109.136
export SPARK_LOCAL_IP=192.168.109.136
3.启动zeppelin
进入zeppelin:进入bin目录下执行./zeppelin-daemon.sh start
然后浏览器访问192.168.109.136:8080进入界面
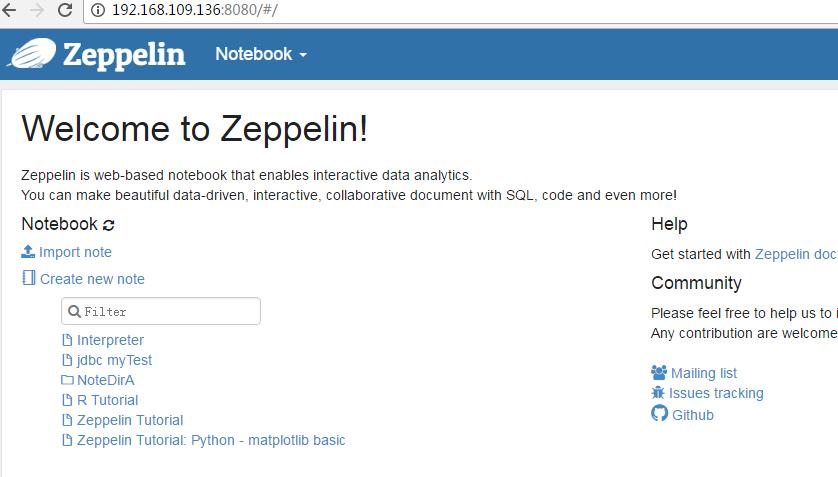
此时就启动成功
4.zeppelin简单实用
1.text
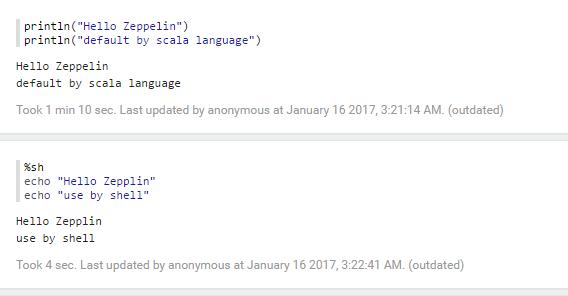
2.html

3.table
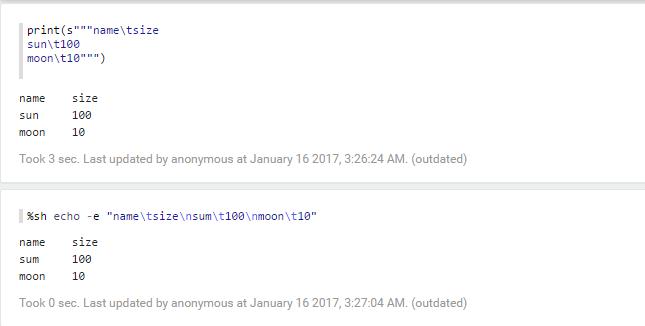

5.可以对数据进行分析
对于我做的最多的分析,就是基于学校的那个资料,我有学校里面的信息,这个里面的每一行的信息是以","
进行分隔,这个其中里面的民族,此时我们对这个民族进行分析
由于我们这个zeppelin是在linux里面的启动,所以我们必须把原有的数据放到linux的里面,此时zeppelin读的文件目录是linux里面的目录
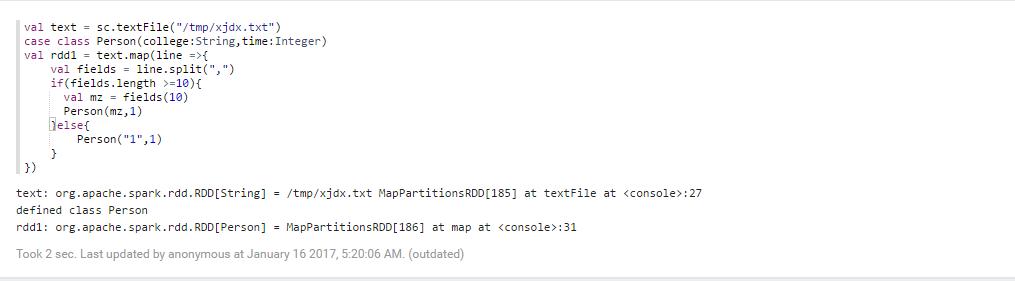



则此时我们就可以对数据库里面的东西进行视图分析,我们通过这个数据,我们发现通过读取数据
,以分组的方式,然后在查询数据有多少个,这样就可以对数据进行显示
a.
val text = sc.textFile("/tmp/xjdx.txt")
case class Person(college:String,time:Integer)
val rdd1 = text.map(line =>{
val fields = line.split(",")
if(fields.length >=){
val mz = fields()
Person(mz,)
}else{
Person("",)
}
})
b.
rdd1.toDF().registerTempTable("rdd1")
c.
%sql select college,count() from rdd1 group by college
这个里面只是针对于存储介质是文件的形式,对于数据库的那个有问题,我会在以后的章节继续介绍的,敬请期待
zeppelin的安装与使用的更多相关文章
- Spark实战2:Zeppelin的安装和SparkSQL使用总结
zeppelin是spark的web版本notebook编辑器,相当于ipython的notebook编辑器. 一Zeppelin安装 (前提是spark已经安装好) 1 下载https://zepp ...
- Zeppelin的安装和SparkSQL使用总结
zeppelin是spark的web版本notebook编辑器,相当于ipython的notebook编辑器. 一Zeppelin安装 (前提是spark已经安装好) 1 下载https://zepp ...
- centos6.5中部署Zeppelin并配置账号密码验证
centos6.5中部署Zeppelin并配置账号密码验证1.安装JavaZeppelin支持的操作系统如下图所示.在安装Zeppelin之前,你需要在部署的服务器上安装Oracle JDK 1.7或 ...
- Ubuntu下基于Saprk安装Zeppelin
前言 Apache Zeppelin是一款基于web的notebook(类似于ipython的notebook),支持交互式地数据分析,即一个Web笔记形式的交互式数据查询分析工具,可以在线用scal ...
- 安装zeppelin
安装zeppelin 1.默认安装好spark集群 2.安装zeppelin 1.解压安装包 tar zxvf zeppelin-0.5.5-incubating-bin-all.tgz 2.配置环境 ...
- 数据可视化工具zeppelin安装
介绍 zeppelin主要有以下功能 数据提取 数据发现 数据分析 数据可视化 目前版本(0.5-0.6)之前支持的数据搜索引擎有如下 安装 环境 centOS 6.6 编译准备工作 sudo yum ...
- NoteBook学习(二)-------- Zeppelin简介与安装
Zeppelin官网地址: http://zeppelin.apache.org/ Github地址: https://github.com/apache/zeppelin (参照官网) 1.什么是z ...
- Zeppelin 学习笔记之 Zeppelin安装和elasticsearch整合
Zeppelin安装: Apache Zeppelin提供了web版的类似ipython的notebook,用于做数据分析和可视化.背后可以接入不同的数据处理引擎,包括spark, hive, taj ...
- zeppelin安装使用
官网:http://zeppelin-project.org/ 代码:https://github.com/NFLabs/zeppelin 使用:按照官网的视频操作一遍,应该就懂了http://y ...
随机推荐
- Android Vmp加固实现流程图
0x00: 目前各种加固都说是VMP了,简单分析市面上的加固,然后自己实现了一个类似原理的加固,大致流程图如下: 加固端: 解释器:
- scss的使用方式(环境搭建)
我用的是Koala. IDE是intellij_idea(其他IDE也可) 下载Koala:http://koala-app.com/ 2.安装(选好位置,下一步即可) 3.打开Koala,创建项目 ...
- 1、HDFS分布式文件系统
1.HDFS分布式文件系统 分布式存储 分布式计算 2.hadoop hadoop含有四个模块,分别是 common. hdfs和yarn. common 公共模块. HDFS hadoop dist ...
- 【js基础修炼之路】— 深入浅出理解闭包
之前对于闭包的理解只是很肤浅的,只是浮于表面,这次深究了一下闭包,下面是我对闭包的理解. 什么是闭包? 引用高程里的话 => 闭包就是有权访问另一个作用域中变量的函数,闭包是由函数以及创建该函数 ...
- 使用dao时,如何同时使用动态表名和过滤字段?
使用dao时,如何同时使用动态表名和过滤字段? 发布于 630天前 作者 wukonggg 316 次浏览 复制 上一个帖子 下一个帖子 标签: 无 如题.求样例代码 1 回复 wend ...
- 初始化mysql数据库时提示字符编码错误的解决办法
有时候在安装完数据库并初始化的时候会出现如下错误: root@localhost mysql-5.5.19]# bash scripts/mysql_install_db --user=mysql - ...
- 1012: A MST Problem
1012: A MST Problem 时间限制: 1 Sec 内存限制: 32 MB提交: 63 解决: 33[提交][状态][讨论版][命题人:外部导入] 题目描述 It is just a ...
- 2018.8.6 学习 log4j.properties 配置文件
配置文件的话第一步当然是解决乱码问题 Eclipse中properties文件中文乱码解决方式 打开eclipse的properties文件时你会发现,其中部分中文注释乱码了,下面将写出如何设置pro ...
- lasagne保存网络参数
# Optionally, you could now dump the network weights to a file like this: # np.savez('model.npz', *l ...
- express_webpack自动刷新
现在,webpack可以说是最流行的模块加载器(module bundler).一方面,它为前端静态资源的组织和管理提供了相对较完善的解决方案,另一方面,它也很大程度上改变了前端开发的工作流程.在应用 ...