python学习笔记:第21天 常用内置模块之collections和time
一、collections模块
1. Counter
Counter是⼀个计数器,主要⽤统计字符的数量,之前如果我们要统计字符串的话要写如下算法:
s = 'Wed Nov 14 08:58:45 CST 2018'
dic = {}
for c in s:
dic[c] = dic.setdefault(c, 0) + 1
print(dic)
# 结果:
# {'W': 1, 'e': 1, 'd': 1, ' ': 5, 'N': 1, 'o': 1, 'v': 1, '1': 2, '4': 2, '0': 2, '8': 3, ':': 2, '5': 2, 'C': 1, 'S': 1, 'T': 1, '2': 1}
但是使用Count函数要简单的多:
from collections import Counter
s = 'Wed Nov 14 08:58:45 CST 2018'
c = Counter(s)
for k in c:
print(f'{k}: {c[k]}')
# 结果:
# W: 1
# e: 1
# d: 1
# : 5
# N: 1
# o: 1
# v: 1
# 1: 2
# 4: 2
# 0: 2
# 8: 3
# :: 2
# 5: 2
# C: 1
# S: 1
# T: 1
# 2: 1
2. 双向队列
这里的双向队列的操作其实很简单,但是我们需要明确两个概念:栈和队列
- 栈:栈就像是一个桶,可以往里面放东西和从里面把东西拿出来,但是我们在放当西的时候(push)会发现最开始放进去的东西总是在最下面,而最后放的东西会在最上面,于是我们从里面拿东西(pop)的时候都是从最上面开始拿的。这就是栈所遵循的先进后出的原则:FILO(Last In First Out)
由于python中并没有栈的实现,这里写一个简单版的栈来看一下栈实现的效果:
class Node:
def __init__(self, value): # 创建了一个节点类,代表栈中每一个元素
self.value = value
self.next = None # 这里的next指向下一个元素的位置
class Stack:
def __init__(self):
self.top = None # 初始化的时候栈顶元素默认值设置为None
def push(self, val):
node = Node(val) # push的时候先创建一个新的节点
node.next = self.top # 把新节点的next指向原来的栈顶元素
self.top = node # 把添加的新节点标记为栈顶节点
def pop(self):
if self.top is not None: # 判断栈中是否存在元素,如果存在再抛出栈顶元素
top = self.top # 先把栈顶元素赋值给一个临时变量
self.top = self.top.next # 再把栈顶元素指向自己的下一个节点
return top.value # 抛出之前的栈顶元素(即临时变量top)
return None
以上代码就是一个简单版本栈的实现,我们可以来测试一下:
s = Stack()
s.push('馒头一号')
s.push('馒头二号')
s.push('馒头三号')
s.push('馒头四号')
s.push('馒头五号')
print(s.pop())
print(s.pop())
print(s.pop())
print(s.pop())
print(s.pop())
print(s.pop())
# 结果:
# 馒头五号
# 馒头四号
# 馒头三号
# 馒头二号
# 馒头一号
# None
从上可以看出,栈始终遵循着先进后出的原则。
- 队列
在python中已经有了队列的实现,我们来看看对列的特性:
from queue import Queue
q = Queue()
q.put("李嘉诚")
q.put("张开")
q.put("张毅")
print(q) # 这里的q返回的是一个Queue对象
print(q.get())
print(q.get())
print(q.get())
# 结果:
# <queue.Queue object at 0x000001DD79D68630>
# 李嘉诚
# 张开
# 张毅
如果队列⾥没有元素了. 再也就拿不出来元素了. 此时程序会阻塞.
队列的特性就像是我们买火⻋票排队的情景,排在前面的就先买然后买完出来,排在后面就后面买,队列遵循的是先进先出的原则:FIFO(first in first out)。
- 双向队列
然后我们再来看下双向队列deque:
from collections import deque
q = deque()
q.append('高圆圆')
q.append('江疏影')
q.appendleft('赵又廷')
q.appendleft('赵丽颖')
# q: 赵丽颖 赵又廷 高圆圆 江疏影
print(q.pop())
print(q.popleft())
print(q.popleft())
# 结果:
# 江疏影
# 赵丽颖
# 赵又廷
3. namedtuple 命名元组
命名元组,顾名思义即给元组内的元素进⾏命名,比如我们说(x, y) 这是⼀个元组同时,我们还可以认为这是⼀个点坐标。这时,我们就可以使⽤namedtuple对元素进⾏命名。
from collections import namedtuple
t = namedtuple('Point', ['x', 'y', 'z', 'u'])
p = t(10, 100, 34, 89)
print(p.x) # 可以像访问实例变量一样用 . 访问
print(p.y)
print(p)
print(p[1]) # 也可以用下标访问
print(p[0])
print('--------------')
for i in p: # 也可以对这个对象做循环遍历
print(i)
# 结果:
# 10
# 100
# Point(x=10, y=100, z=34, u=89)
# 100
# 10
# --------------
# 10
# 100
# 34
# 89
4. orderdict和defaultdict
orderdict:字典的key默认是⽆序的,⽽OrderedDict是有序的(自3.6的版本后已经没有太大的差异了,打印的时候默认也是顺序的)
from collections import OrderedDict
od = OrderedDict({'a':1, 'c':3, 'b':2})
print(od)
print(od['a'])
# 结果:
# OrderedDict([('a', 1), ('c', 3), ('b', 2)])
# 1
defaultdict:可以给字典设置默认值,当key不存在时,直接获取默认值:
from collections import defaultdict
lst = [11, 22, 33, 44, 55, 66, 77, 88, 99]
d = defaultdict(list) # 传入默认值list
for i in lst:
if i < 66:
d['key1'].append(i)
else:
d['key'].append(i)
print(d)
# 结果:
# defaultdict(<class 'list'>, {'key1': [11, 22, 33, 44, 55], 'key': [66, 77, 88, 99]})
二、时间模块
时间模块是我们要熟记的,对我们后期的项目开发来说很重要,要使用时间模块首先我们要导入这个模块:
#常用方法
time.sleep(secs) # (线程)推迟指定的时间运行。单位为秒。
time.time() # 获取当前时间戳
# 1542166453.105443
在python中时间分成三种表现形式:
时间戳(timestamp):时间戳使⽤的是从1970年01⽉01⽇00点00分00秒到现在⼀共经过了多少秒... 我们运行
type(time.time())获取到的就是时间戳了,使⽤float来表⽰。格式化时间(strftime):这个时间可以根据我们的需要对时间进⾏任意的格式化,具体的格式如下表:
| 格式 | 格式说明 | 取值范围或其他 |
|---|---|---|
| %y | 两位数的年份表示 | 00-99 |
| %Y | 四位数的年份表示 | 000-9999 |
| %m | 月份 | 01-12 |
| %d | 月内中的一天 | 0-31 |
| %H | 24小时制小时数 | 0-23 |
| %I | 12小时制小时数 | 01-12 |
| %M | 分钟数 | 00=59 |
| %S | 秒 | 00-59 |
| %a | 本地简化星期名称 | |
| %A | 本地完整星期名称 | |
| %b | 本地简化的月份名称 | |
| %B | 本地完整的月份名称 | |
| %c | 本地相应的日期表示和时间表示 | |
| %j | 年内的一天 | 001-366 |
| %p | 本地A.M.或P.M.的等价符 | |
| %U | 一年中的星期数,星期天为星期的开始 | 00-53 |
| %w | 星期(0-6),星期天为星期的开始 | 0-6 |
| %W | 一年中的星期数,星期一为星期的开始 | 00-53 |
| %x | 本地相应的日期表示 | |
| %X | 本地相应的时间表示 | |
| %Z | 当前时区的名称 | |
| %% | %号本身 |
- 结构化时间(struct_time):这个时间主要可以把时间进⾏分类划分. 比如. 1970年01⽉01⽇ 00点00分00秒 这个时间可以被细分为年, ⽉, ⽇.....⼀⼤堆东⻄:
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为0 |
我们先看下这几种时间表现形式:
In [1]: import time
In [2]: time.time() # 查看当前时间的时间戳
Out[2]: 1542447516.5602913
In [3]: time.localtime() # 查看当前的结构化时间
Out[3]: time.struct_time(tm_year=2018, tm_mon=11, tm_mday=17, tm_hour=17, tm_min=38, tm_sec=43, tm_wday=5, tm_yday=321, tm_isdst=0)
In [4]: time.strftime('%Y-%m-%d %I:%M:%S %p') # 查看当前的格式化时间
Out[4]: '2018-11-17 05:39:10 PM'
时间模块常用的几个方法:
time.sleep(s) # 挂起进程,让程序睡眠s秒
time.time() # 查看当前的时间戳
time.strftime(format[, tuple]) # 把格式化时间转化成格式化时间,默认转换当前时间
time.strptime(string, format) # 以指定的format格式把格式化时间转换成结构化时间
time.gmtime(timestamp) # UTC时间,与英国伦敦当地时间一致
time.localtime(timestamp) # #当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时
time.mktime(struct_time) # 把结构化时间转化成时间戳
时间戳、结构化时间和格式化时间的关系和转化:
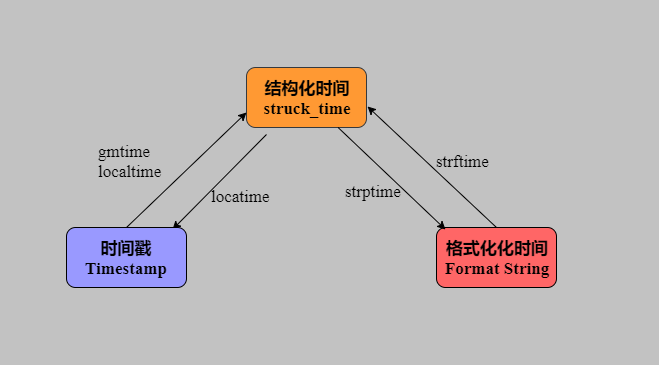
# 时间戳转化为格式化时间
st1 = 18888888
struck_time = time.localtime(st1)
print(struck_time)
# time.struct_time(tm_year=1970, tm_mon=8, tm_mday=7, tm_hour=22, tm_min=54, tm_sec=48, tm_wday=4, tm_yday=219, tm_isdst=0)
# 格式化时间转化成时间戳
st2 = time.mktime(struck_time)
print(st2)
# 18888888.0
# 格式化时间转换成结构化时间
ft1 = '2018-11-19 20:34'
st1 = time.strptime(ft1, '%Y-%m-%d %H:%M')
print(st1)
# time.struct_time(tm_year=2018, tm_mon=11, tm_mday=19, tm_hour=20, tm_min=34, tm_sec=0, tm_wday=0, tm_yday=323, tm_isdst=-1)
# 结构化时间转换成格式化时间
ft2 = time.strftime('%Y-%m-%d %H:%M:%S', st1)
print(ft2)
# 2018-11-19 20:34:00
时间戳和格式化时间的互转(最常用):
# 时间戳转成格式化时间:
ft3 = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(1888888888))
print(ft3)
# 2029-11-09 11:21:28
# 格式化时间转成时间戳:
st3 = time.mktime(time.strptime(ft3, '%Y-%m-%d %H:%M:%S'))
print(st3)
# 1888888888.0
python学习笔记:第21天 常用内置模块之collections和time的更多相关文章
- Python学习笔记(四十一)— 内置模块(10)urllib
摘抄自:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001432688314 ...
- Python学习笔记(四十)— 内置模块(9)HTMLParser
摘抄自:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001432002312 ...
- python学习笔记(12)常用模块
一.模块.包 什么是模块? 模块实质上就是一个python文件,它是用来组织代码的,意思就是说把python代码写到里面,文件名就是模块的名称,test.py test就是模块名称. 什么是包? 包, ...
- Python学习笔记五:字符串常用操作,字典,三级菜单实例
字符串常用操作 7月19日,7月20日 ,7月22日,7月29日,8月29日,2月29日 首字母大写:a_str.capitalize() 统计字符串个数:a_str.count(“x”) 输出字符, ...
- python学习笔记(十)常用模块
import os print(os.getcwd())#取当前工作目录,绝对路径 print(os.chdir("../"))#更改当前目录,.代表当前目录,..代表上一级目录 ...
- python学习笔记(13)常用模块列表总结
os模块: os.remove() 删除文件 os.unlink() 删除文件 os.rename() 重命名文件 os.listdir() 列出指定目录下所有文件 os.chdir() 改变当前工作 ...
- python学习笔记(四)- 常用的字符串的方法
一.常用的字符串方法(一):(字符串是不能被修改的) 1)a.strip() #默认去掉字符串两边的空格和换行符 a = ' 字符串 \n\n ' c = a.strip() a.lstrip() ...
- python学习笔记(21)--新建html乱码(给每本漫画生成一个html)
说明: 1. open("index.html","w",encoding="utf-8"),open的第三个参数可以设置编码格式. 2. ...
- Python 学习笔记(五)常用函数
Python内建函数 四舍五入: round() 绝对值: abs() >>> round(1.543,2) 保留两位小数,四舍五入为1.54 1.54 >>> r ...
随机推荐
- TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本课主题 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- 简单的python爬虫--爬取Taobao淘女郎信息
最近在学Python的爬虫,顺便就练习了一下爬取淘宝上的淘女郎信息:手法简单,由于淘宝网站本上做了很多的防爬措施,应此效果不太好! 爬虫的入口:https://mm.taobao.com/json/r ...
- 017random模块
import randomprint(random.random())print(random.randint(1,8)) #包括8 print(random. ...
- 入门学习webpack笔记
注意事项: 1.预热知识:前端模块化.commonJS最好提前了解.commonJS语法最好熟悉. 2.commonJS中,module表示当前模块,module.exports(或者exports) ...
- BZOJ2820:YY的GCD(莫比乌斯反演)
Description 神犇YY虐完数论后给傻×kAc出了一题给定N, M,求1<=x<=N, 1<=y<=M且gcd(x, y)为质数的(x, y)有多少对kAc这种 傻×必 ...
- BZOJ2337:[HNOI2011]XOR和路径(高斯消元)
Description 给定一个无向连通图,其节点编号为 1 到 N,其边的权值为非负整数.试求出一条从 1 号节点到 N 号节点的路径,使得该路径上经过的边的权值的“XOR 和”最大.该路径可以重复 ...
- UVA11987 【Almost Union-Find】
这是一道神奇的题目,我调了大概一天多吧 首先hack一下翻译,操作3并没有要求查询后从其所在集合里删除该元素 于是我们来看一下这三个操作 第一个合并属于并查集的常规操作 第三个操作加权并查集也是可以解 ...
- mybatis全局配置文件
一.properties:引入外部配置文件 1.resource :引入类路径下的全局配置文件,例如:<properties resource="conf/dbconfig.prope ...
- 二十六、关于 IntelliJ IDEA 中 Schedule for Addition 的问题
在我们使用 IntelliJ IDEA 的时候,经常会遇到这种情况,即: 从 SVN 检出项目之后,并用 IDEA 首次打开项目,IDEA 会弹出如下选择框: 如上图所示,让我们选择是否将XXX.im ...
- ssm分页
pom.xml配置文件中增加相关的插件. <dependency> <groupId>com.github.pagehelper</groupId> <art ...