【spark】分区
RDD是弹性分布式数据集,通常RDD很大,会被分成多个分区,保存在不同节点上。
那么分区有什么好处呢?
分区能减少节点之间的通信开销,正确的分区能大大加快程序的执行速度。
我们看个例子
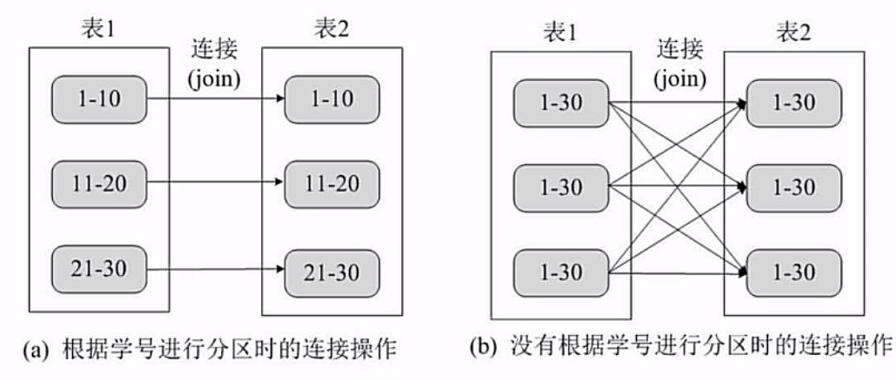
首先我们要了解一个概念,分区并不等同于分块。
分块是我们把全部数据切分成好多块来存储叫做分块。
如上图b,产生的分块,每个分块都可能含有同样范围的数据。
而分区,则是把同样范围的数据分开,如图a
我们通过这个图片可以清楚的看到,我们通过把相同主键的数据连接。
经过有序分区的数据,只需要按照相同的主键分区 join 即可。
未通过分区的分块执行 join ,额外进行多次连接操作,把同样的数据连接到不同节点上,大大增大了通信开销。
在一些操作上,join groupby,filer等等都能从分区上获得很大的收益。
分区原则
RDD分区的一个分区原则是使得分区个数尽量等于集群中的CPU核心(core)数量。分区过多并不会增加执行速度。
例如,我们集群有10个core,我们分5个区,每个core执行一个分区操作,剩下5个core浪费。
如果,我们分20分区,一个core执行一个分区,剩下的10分区将会排队等待。
默认分区数目
对于不同的Spark部署模式而言(本地模式,standalone模式,YARN模式,Mesos模式)
都可以数值spark.default.parallelism这个参数值,来配置默认分区。
当然针对不同的部署模式,默认分区的数目肯定也是不相同的。
本地模式,默认为本地机器的CPU数目,若设置了local[N],则默认为N。一般使用local[*]来使用所有CPU数。
YARN模式,在集群中所有CPU核心数目总和和 2 二者中取较大值作为默认值。
Mesos模式,默认分区为8.
如何手动设置分区
1.创建RDD时:在调用 textFile 和 parallelize 方法的时候手动指定分区个数即可。
语法格式 sc.parallelize(path,partitionNum) sc.textFile(path,partitionNum)
//sc.parallelize(path,partitionNum)
val list = List("Hadoop","Spark","Hive");
val rdd1 = sc.parallelize(list,2);//设置两个分区
val rdd2 = sc.parallelize(list);//未指定分区,默认为spark.default.parallelism //sc.textFile(path,partitionNum)
val rdd3 = sc.textFile("file://+本地文件地址",2);//设置两个分区
val rdd4 = sc.textFile("file://+本地文件地址");//未指定分区,默认为min(2,spark.default.parallelism)
val rdd5 = sc.textFile("file://+HDFS文件地址");//未指定分区,默认为HDFS文件分片数
2.通过转化操作得到新的RDD时:调用 repartition 方法即可。
语法格式 val newRdd = oldRdd.repartition(1)
val list = List("Hadoop","Spark","Hive");
val rdd1 = sc.parallelize(list,2);//设置两个分区
val newRdd1 = rdd1.repartition(3);//重新分区
println(newRdd1.partitions.size);//查看分区数
分区函数
我们在使用分区的时候要了解两条规则
(1)只有Key-Value类型的RDD才有分区的,非Key-Value类型的RDD分区的值是None
(2)每个RDD的分区ID范围:0~numPartitions-1,决定这个值是属于那个分区的
spark内部提供了 HashPartitioner 和 RangePartitioner 两种分区策略。
1.HashPartitioner
原理:
对于给定的key,计算其hashCode,并除于分区的个数取余,如果余数小于0,则用余数+分区的个数,最后返回的值就是这个key所属的分区ID。
语法:
rdd.partitionBy(new spark.HashPartitioner(n))
示例:
object Main{
def main(args:Array[String]): Unit ={
val conf = new SparkConf();
val sc = new SparkContext(conf);
val list = List((1,1),(1,2),(2,1),(2,2),(3,1),(3,2))//注意这里必须是(k,v)形式
val rdd = sc.parallelize(list);
rdd.partitionBy(new spark.HashPartitioner(3));//使用HashPartitioner
}
}
我们再看一个例子说明HashPartitioner如何分区的。

注意:实际我们使用的默认分区方式实际是 HashPartitioner 分区方式
2.RangePartitioner
原理:
根据key值范围和分区数确定分区范围,将范围内的键分配给相应的分区。
语法:
rdd.partitionBy(new RangePartitioner(n,rdd));
示例:
object Main{
def main(args:Array[String]): Unit ={
val conf = new SparkConf();
val sc = new SparkContext(conf);
val list = List((1,1),(1,2),(2,1),(2,2),(3,1),(3,2))
val rdd = sc.parallelize(list);
val pairRdd = rdd.partitionBy(new RangePartitioner(3,rdd));//根据key分成三个区
}
}
3.用户自定义分区
如果上面两种分区都满足不了你的要求的时候,我们可以自己定义分区类。
Spark提供了相应的接口,我们只需要扩展Partitioner抽象类。
abstract class Partitioner extends Serializable {
def numPartitions: Int //这个方法需要返回你想要创建分区的个数
def getPartition(key: Any): Int //这个函数需要对输入的key做计算,然后返回该key的分区ID,范围一定是0到 numPartitions-1
}
定义完毕后,通过parttitionBy()方法调用。
示例:

我们看这样一个实例,需要按照最后一位数来分区,我们用普通的分区并不能满足要求,所以这个时候需要自己定义分区类。
class UDPartitioner (numParts:Int) extends Partitioner {
//覆盖分区数
override def numPartitions = numParts;
//覆盖分区获取函数,返回分区所用的key
override def getPartition(key: Any) : Int= {
key.toString.toInt % 10;//通过key除10取余来获取最后一位数并返回。
}
}
object Main{
def main(args:Array[String]): Unit ={
val conf = new SparkConf();
val sc = new SparkContext(conf);
//模拟5个分区的数据
val data1 = sc.parallelize(1 to 10,5);
//注意,RDD一定要是key-value,才能使用用户自定义的分区类,通过key来确定分区
val data2 = data1.map((_,1));//占位符用法,等同于data.map(x => (x,1))
//根据尾号转变为10个分区,分别写到10个文件中
data2.partitionBy(new UDPartitioner(10)).saveAsTextFile("file:///usr/local/output");
}
}
另外,我们也可以通过在函数中额外定义 hashcode()方法 和 equal()方法来保证分区的正确分配。
【spark】分区的更多相关文章
- 【Spark 深入学习-08】说说Spark分区原理及优化方法
本节内容 ------------------ · Spark为什么要分区 · Spark分区原则及方法 · Spark分区案例 · 参考资料 ------------------ 一.Spark为什 ...
- Spark学习之路 (十七)Spark分区
一.分区的概念 分区是RDD内部并行计算的一个计算单元,RDD的数据集在逻辑上被划分为多个分片,每一个分片称为分区,分区的格式决定了并行计算的粒度,而每个分区的数值计算都是在一个任务中进行的,因此任务 ...
- Spark(十一)Spark分区
一.分区的概念 分区是RDD内部并行计算的一个计算单元,RDD的数据集在逻辑上被划分为多个分片,每一个分片称为分区,分区的格式决定了并行计算的粒度,而每个分区的数值计算都是在一个任务中进行的,因此任务 ...
- spark分区
spark默认的partition的分区数是和本机CPU的核数保持一致: bucket的数量和reduce的数量一致:buket的概念是map会将计算获得数据放到各个buket中,每个bucket和一 ...
- Spark学习之路 (十七)Spark分区[转]
分区的概念 分区是RDD内部并行计算的一个计算单元,RDD的数据集在逻辑上被划分为多个分片,每一个分片称为分区,分区的格式决定了并行计算的粒度,而每个分区的数值计算都是在一个任务中进行的,因此任务的个 ...
- Hive和Spark分区策略
1.概述 离线数据处理生态系统包含许多关键任务,最大限度的提高数据管道基础设施的稳定性和效率是至关重要的.这边博客将分享Hive和Spark分区的各种策略,以最大限度的提高数据工程生态系统的稳定性和效 ...
- Spark分区实例(teacher)
package URL1 import org.apache.spark.Partitioner import scala.collection.mutable class MyPartitioner ...
- 重要 | Spark分区并行度决定机制
最近经常有小伙伴在本公众号留言,核心问题都比较类似,就是虽然接触Spark有一段时间了,但是搞不明白一个问题,为什么我从HDFS上加载不同的文件时,打印的分区数不一样,并且好像spark.defaul ...
- Spark分区器浅析
分区器作用:决定该数据在哪个分区 概览: 仅仅只有pairRDD才可能持有分区器,普通RDD的分区器为None 在分区器为None时RDD分区一般继承至父RDD分区 初始RDD分区数: 由集合创建,R ...
- spark 分区
http://stackoverflow.com/questions/39368516/number-of-partitions-of-spark-dataframe
随机推荐
- Linux上free命令的输出及其他
一.明确概念 A buffer is something that has yet to be "written" to disk. A cache is something t ...
- 思考在伟大的互联网世界中,我是谁?——By Me in 2016
互联网伟大在哪里? 互联网的发明是不是伟大的,这个问题就如同这个世界上许许多多的问题一样,很大程度上取决于人们不同的经历.不同的见识,乃至不同的信念.不同的人生态度. 摘录网上的一段表述:“互联网(产 ...
- 001-前端系列-react系列
一.概述 原文地址:http://www.ruanyifeng.com/blog/2016/09/react-technology-stack.html 二.摘要 ES6 语法:教程 [可以了解] B ...
- 对数值数据的格式化处理(保留小数点后N位)
项目中有时会遇到对数值部分进行保留操作,列如保留小数点后2位,所有的数据都按这种格式处理, //保留小数点后2位,都按这种格式处理,没有补0 DecimalFormat df = new Decima ...
- 生信笔记-mooc【武大】
.DNA拓扑学 在拓扑结构的限制下,DNA进行复制等过程.还有连环数=扭转数+缠绕数. 2.拓扑异构酶 DNA变性破坏了两条链之间碱基形成的氢键.和拓扑异构酶是不同的. 3.RNA的组成和结构特点 R ...
- jdk1.7 ArrayList源码浅析
参考:http://www.cnblogs.com/xrq730/p/4989451.html(借鉴的有点多,哈哈) 首先介绍ArrayList的特性: 1.允许元素为空.允许重复元素 2.有序,即插 ...
- 使用Stanford Parser进行句法分析
一.句法分析 1.定义 句法分析判断输入的单词序列(一般为句子)的构成是否合乎给定的语法,并通过构造句法树来确定句子的结构以及各层次句法成分之间的关系,即确定一个句子中的哪些词构成一个短语,哪些词是动 ...
- Python之初识函数(Day11)
一.函数的定义与调用 总结一: 定义:def 关键词开头,空格之后接函数名称和圆括号(),最后还有一个":". def 是固定的,不能变,必须是连续的def三个字母,不能分开... ...
- java基本类型和包装器类
java是一种面向对象语言,java中的类把方法与数据连接在一起,并构成了自包含式的处理单元.但在java中不能定义基本类型(primitive type),为了能将基本类型视为对象来处理,并能连接相 ...
- python处理时间相关的方法
记录python处理时间的模块:time模块.datetime模块和calendar模块. python版本:2.7 https://blog.csdn.net/songfreeman/article ...