【Machine Learning】监督学习、非监督学习及强化学习对比
- Supervised Learning
- Unsupervised Learning
- Reinforced Learning
Goal:
- How to apply these methods
- How to evaluate each methods
What is Machine Learning?
1.computational statistics
2.computational artifacts(人工制品) that learn over time based on experience
一、分类
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
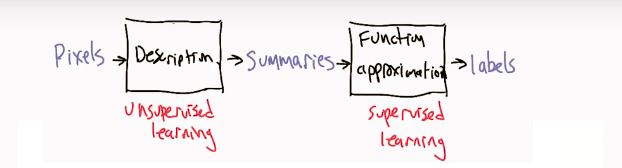
1.1 Supervised learning——Approximation
- 一句话实质:About Function Approximation(函数逼近),or Approximate function induction(近似函数归纳)
- feed with labeled examples,comeing up with some function that generalizes beyond(泛化函数)
- 有反馈
1.2 Unsupervised learning——Description
- 一句话实质:About Compact(简洁的) Description
- 无监督学习是密切相关的统计数据密度估计的问题。
- 无反馈
- Unsupervised learning could be helpful in the supervised Setting
1.3 Reinforcement learning (增强学习)
- 一句话实质:Learning from delayed reward (通过延迟性奖励进行学习)
- 执行许多步之后才知道反馈,就像下棋(对比监督学习的立即反馈)
二、归纳法(induction)与演绎法(deduction)
- Generalize 泛化
- 了解机器学习发展史
- 机器学习算法与归纳而不是演绎有关
- Inductive bias 归纳偏差
归纳:从示例到一般规律(从一个示例得出更普遍的规律)
演绎:从规则到实例,a general rule to specific instances,basically like reasoning(推理)
三、三种机器学习的比较
表述成:优化问题

Supervised Learning —— labels data well(to find a funtion to score that) (标记数据)
Unsupervised Learning —— cluster scores well(最好的分类方法)
Reinforcement learning —— behavior scores well (最好的表现)
3.2 Data
Data is king in machine learning.
转变:以算法为中心——》以数据为中心
- Believe in your data!
【Machine Learning】监督学习、非监督学习及强化学习对比的更多相关文章
- 131.005 Unsupervised Learning - Cluster | 非监督学习 - 聚类
@(131 - Machine Learning | 机器学习) 零. Goal How Unsupervised Learning fills in that model gap from the ...
- Machine Learning 之二,什么监督性学习,非监督性学习。
1.什么是监督性学习?Supervised Machine Learning. 在监督性学习,我们给定一个数据集以及我们已经知道正确输出的结果,然后找到一个输入和输出的关系. In Supervis ...
- 如何区分监督学习(supervised learning)和非监督学习(unsupervised learning)
监督学习:简单来说就是给定一定的训练样本(这里一定要注意,样本是既有数据,也有数据对应的结果),利用这个样本进行训练得到一个模型(可以说是一个函数),然后利用这个模型,将所有的输入映射为相应的输出,之 ...
- Reinforcement Learning 的那点事——强化学习(一)
引言 最近实验室的项目需要用到强化学习的有关内容,就开始学习起强化学习了,这里准备将学习的一些内容记录下来,作为笔记,方便日后忘记了好再方便熟悉,也可供大家参考.该篇为强化学习开篇文章,主要概括一些有 ...
- 监督学习&非监督学习
监督学习 1 - 3 - Supervised Learning 在监督学习中,数据集中的每个例子,算法将预测得到例子的""正确答案"",像房子的价格,或者溜 ...
- 机器学习之强化学习概览(Machine Learning for Humans: Reinforcement Learning)
声明:本文翻译自Vishal Maini在Medium平台上发布的<Machine Learning for Humans>的教程的<Part 5: Reinforcement Le ...
- 【资料总结】| Deep Reinforcement Learning 深度强化学习
在机器学习中,我们经常会分类为有监督学习和无监督学习,但是尝尝会忽略一个重要的分支,强化学习.有监督学习和无监督学习非常好去区分,学习的目标,有无标签等都是区分标准.如果说监督学习的目标是预测,那么强 ...
- 强化学习(Reinforcement Learning)中的Q-Learning、DQN,面试看这篇就够了!
1. 什么是强化学习 其他许多机器学习算法中学习器都是学得怎样做,而强化学习(Reinforcement Learning, RL)是在尝试的过程中学习到在特定的情境下选择哪种行动可以得到最大的回报. ...
- k-means 非监督学习聚类算法
非监督学习 非监督学习没有历史样本数据和标签,直接对数据分析或得结果. k-means 使用 >>> from sklearn.cluster import KMeans >& ...
随机推荐
- SQLmap源码分析之框架初始化(一)
SQLmap是现在搞web人手一个的注入神器,不仅包含了主流数据库的SQL注入检测,而且包含提权以及后渗透模块.基于python2.x开发而成,使用方便.所以研究web安全少不了分析源码,学习代码的同 ...
- Oracle分析函数、窗口函数简单记录汇总
一.分析函数.窗口函数一般形式 1.分析函数的形式分析函数带有一个开窗函数over(),包含三个分析子句:分组(partition by), 排序(order by), 窗口(rows) ,他们的使用 ...
- localStorage、sessionStorage用法总结
1.作用 1.1 共同点: 都是用来存储客户端临时信息的对象. 均只能存储字符串类型的对象(虽然规范中可以存储其他原生类型的对象,但是目前为止没有浏览器对其进行实现). 1.2 ...
- Docker 镜像加速
通过 Docker 官方镜像加速,中国区用户能够快速访问最流行的 Docker 镜像.该镜像托管于中国大陆,本地用户现在将会享受到更快的下载速度和更强的稳定性,从而能够更敏捷地开发和交付 Docker ...
- axios简单介绍
axios的配置,get,post,axiso的同步问题解决 一.缘由 vue-resoure不更新维护,vue团队建议使用axios. 二.axios安装 1.利用npm安装npm install ...
- 003-BootStrap完整模板
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="utf-8& ...
- 读写锁--ReentrantReadWriteLock
读写锁,对于读操作来说是共享锁,对于写操作来说是排他锁,两种操作都可重入的一种锁.底层也是用AQS来实现的,我们来看一下它的结构跟代码: ------------------------------- ...
- 【CSS】布局之选项卡与图片库
前面对简单的选项卡和简单的图片库进行了实现,现在把两者结合起来,实现下面这样的效果. 现在附上代码: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4 ...
- 快速掌握用python写并行程序
目录 一.大数据时代的现状 二.面对挑战的方法 2.1 并行计算 2.2 改用GPU处理计算密集型程序 3.3 分布式计算 三.用python写并行程序 3.1 进程与线程 3.2 全局解释器锁GIL ...
- Mybatis缓存(一)
1.什么是缓存 Mybatis提供缓存,用于减轻数据压力,提高数据库性能. 2.Mybatis缓存分类 Mybatis的缓存分为一级缓存和二级缓存. Mybatis的一级缓存 1.一级缓存的范围 1 ...