<tf-idf + 余弦相似度> 计算文章的相似度
.png)

.png)
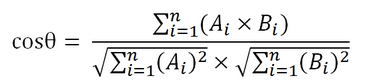
一般情况下,相似度都是归一化到[0,1]区间内,因此余弦相似度表示为cosineSIM=0.5cosθ+0.5
<tf-idf + 余弦相似度> 计算文章的相似度的更多相关文章
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- Python简单实现基于VSM的余弦相似度计算
在知识图谱构建阶段的实体对齐和属性值决策.判断一篇文章是否是你喜欢的文章.比较两篇文章的相似性等实例中,都涉及到了向量空间模型(Vector Space Model,简称VSM)和余弦相似度计算相关知 ...
- java算法(1)---余弦相似度计算字符串相似率
余弦相似度计算字符串相似率 功能需求:最近在做通过爬虫技术去爬取各大相关网站的新闻,储存到公司数据中.这里面就有一个技术点,就是如何保证你已爬取的新闻,再有相似的新闻 或者一样的新闻,那就不存储到数据 ...
- java文章标题及文章相似度计算hash算法实现
参看了 https://github.com/awnuxkjy/recommend-system 对方用了 余弦 函数实现相似度计算,我则用的是 hanlp+hash 算法(Hash算法总结) 再看服 ...
- 两矩阵各向量余弦相似度计算操作向量化.md
余弦相似度计算: \cos(\bf{v_1}, \bf{v_2}) = \frac{\left( v_1 \times v_2 \right)}{||v_1|| * ||v_2|| } \cos(\b ...
- Spark Mllib里相似度度量(基于余弦相似度计算不同用户之间相似性)(图文详解)
不多说,直接上干货! 常见的推荐算法 1.基于关系规则的推荐 2.基于内容的推荐 3.人口统计式的推荐 4.协调过滤式的推荐 协调过滤算法,是一种基于群体用户或者物品的典型推荐算法,也是目前常用的推荐 ...
- 转:Python 文本挖掘:使用gensim进行文本相似度计算
Python使用gensim进行文本相似度计算 转于:http://rzcoding.blog.163.com/blog/static/2222810172013101895642665/ 在文本处理 ...
- 使用 TF-IDF 加权的空间向量模型实现句子相似度计算
使用 TF-IDF 加权的空间向量模型实现句子相似度计算 字符匹配层次计算句子相似度 计算两个句子相似度的算法有很多种,但是对于从未了解过这方面算法的人来说,可能最容易想到的就是使用字符串匹配相关的算 ...
- TF/IDF计算方法
FROM:http://blog.csdn.net/pennyliang/article/details/1231028 我们已经谈过了如何自动下载网页.如何建立索引.如何衡量网页的质量(Page R ...
随机推荐
- java注解1
http://computerdragon.blog.51cto.com/6235984/1210969 http://blog.csdn.net/it_man/article/details/440 ...
- DB 数据同步到数据仓库的架构与实践
背景 在数据仓库建模中,未经任何加工处理的原始业务层数据,我们称之为ODS(Operational Data Store)数据.在互联网企业中,常见的ODS数据有业务日志数据(Log)和业务DB数据( ...
- 笔记2:Jmeter核心组件
资料来源:开源优测 微信公众号,作者:苦叶子 Jmeter核心组件 1.Thread Group(线程组) 2.逻辑控制器,配置元件,定时器,前置处理器,Sample,后置处理器,断言,监听器: 3. ...
- How to create a notification with NotificationCompat.Builder?AAAA
Ask Question up vote 49 down vote favorite 19 I need to create a simple notification which will be s ...
- H5中的语义化标签
H5中的语义化标签也就是之前的id = “header”演变而来的 只不过之前是id 现在变成了标签而已 什么是语义化: 根据内容结构化(内容语义化) 选择合适的标签(代码语义化) 便于开发者阅读和写 ...
- Python 之 matplotlib (十六)Animation动画【转】
本文转载自:https://blog.csdn.net/wangsiji_buaa/article/details/80057875 代码: import matplotlib.pyplot as ...
- 读取Excel复杂的数据
涉及到合并单元格的数据读取: package com.util; import org.apache.poi.ss.usermodel.*; import org.apache.poi.ss.util ...
- sql server 数据库复制实现数据同步常见问题(不定期更新)
sql server2008数据库复制实现数据同步常见问题 在原作者基础上追加 sql server2008数据库复制实现数据同步常见问题 23.发布 'xx' 的并发快照不可用,因为该快照尚未完全生 ...
- 初涉Rx套餐 之RxBinding(让你的事件流程更清晰)
转载请注明出处:王亟亟的大牛之路 最近下班回家都在WOW,周末就爆肝,感觉人都要GO DIE了,昨天下午看了看RxBinding相关的功能感觉还是蛮强大的,所提供的API也是相当丰富(基本Rx套餐都是 ...
- DataStage系列教程 (Pivot_Enterprise 行列转换)
有人提到Pivot_Enterprise这个组件,之前没有用过,今天捣腾了会,写下来供以后参考,如果有什么不对的,还请多指出,谢谢! Pivot_Enterprise主要用来进行行列转换. 1 示例 ...