正则化的L1范数和L2范数
范数介绍:https://www.zhihu.com/question/20473040?utm_campaign=rss&utm_medium=rss&utm_source=rss&utm_content=title
首先介绍损失函数,它是用来估量你模型的预测值f(x)与真实值Y的不一致程度
主要的几种类型包括:1)0-1损失函数 2)平方损失函数 3)绝对损失函数 4) 对数损失函数
0-1损失函数:
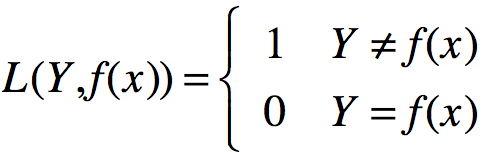
平方损失函数:
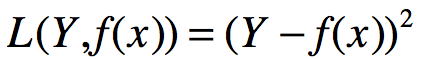
绝对损失函数:
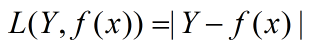
对数损失函数:

由此延伸出对应的概念:

其次介绍一般的范数表示:
范数包括向量范数和矩阵范数,向量范数表征向量空间中向量的大小,矩阵范数表征矩阵引起变化的大小。一种非严密的解释就是,对应向量范数,向量空间中的向量都是有大小的,这个大小如何度量,就是用范数来度量的,不同的范数都可以来度量这个大小
向量的范数:
1-范数,计算方式为向量所有元素的绝对值之和。

2-范数,计算方式跟欧式距离的方式一致。
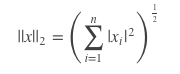
矩阵的范数:
假设矩阵的大小为m∗n,即m行n列。
1-范数,又名列和范数。顾名思义,即矩阵列向量中绝对值之和的最大值。
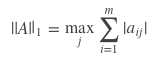
2-范数,又名谱范数,计算方法为ATA矩阵的最大特征值的开平方。
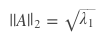
其中λ1为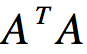 的最大特征值。
的最大特征值。
正则化也就是经验风险项加上正则化项,从而达到对模型选择的目的,以做到从模型拟合效果(经验风险)和复杂度(正则化项)来选去最优模型。
正则化的一般表示形式为:

其中第一项表示经验风险,第二项表示正则化项
正则化可以表示为多个形式,以回归方程为例,由于其损失函数为平方损失,正则化表示为参数向量的L2范数:
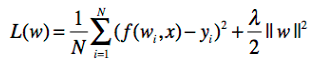
在这里||w||表示参数向量w的L2范数。
正则化也可以表示为参数向量的L1范数
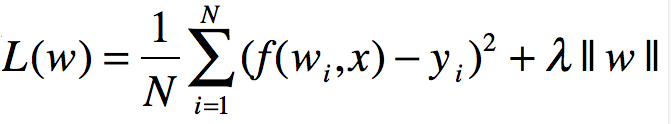
其中||w||表示参数向量w的L1范数
以上部分的经验风险表现越小模型越复杂,这时候正则化项为表现较大,所以我们主要还是筛选经验风险和正则化项同时较小的模型。
注:
L1范数因为表现出比L0范数更好的求解性而应用较为广泛
L2范数表现为向量各元素平方和求平方根,我们让L2范数的正则项||W||2最小,可以使得W的每个元素都很小,都接近于0。
正则化的L1范数和L2范数的更多相关文章
- L1范数与L2范数
L1范数与L2范数 L1范数与L2范数在机器学习中,是常用的两个正则项,都可以防止过拟合的现象.L1范数的正则项优化参数具有稀疏特性,可用于特征选择:L2范数正则项优化的参数较小,具有较好的抗干 ...
- L1范数与L2范数正则化
2018-1-26 虽然我们不断追求更好的模型泛化力,但是因为未知数据无法预测,所以又期望模型可以充分利用训练数据,避免欠拟合.这就要求在增加模型复杂度.提高在可观测数据上的性能表现得同时,又需要兼顾 ...
- L1范数和L2范数
给定向量x=(x1,x2,...xn)L1范数:向量各个元素绝对值之和L2范数:向量各个元素的平方求和然后求平方根Lp范数:向量各个元素绝对值的p次方求和然后求1/p次方L∞范数:向量各个元素求绝对值 ...
- Lp距离, L1范数, 和L2范数(转载)
范式可以理解成距离 转载自: https://blog.csdn.net/hanhuili/article/details/52079590 内容如下: 由此可见,L2其实就是欧式距离.工程上,往往不 ...
- L0、L1、L2范数正则化
一.范数的概念 向量范数是定义了向量的类似于长度的性质,满足正定,齐次,三角不等式的关系就称作范数. 一般分为L0.L1.L2与L_infinity范数. 二.范数正则化背景 1. 监督机器学习问题无 ...
- paper 126:[转载] 机器学习中的范数规则化之(一)L0、L1与L2范数
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数(转)
http://blog.csdn.net/zouxy09/article/details/24971995 机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http: ...
- L0、L1与L2范数、核范数(转)
L0.L1与L2范数.核范数 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理解下常用的L0.L1.L2和核范数规则化.最后聊下规则化项参数的选择问题.这里因为篇幅比较庞大 ...
- 机器学习中的范数规则化之(一)L0、L1与L2范数 非常好,必看
机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http://blog.csdn.net/zouxy09 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
随机推荐
- tool 'xcodebuild' requires Xcode, but active developer directory '/Library/Developer/CommandLineTools' is a command line tools instance
在执行自动化打包的时候报错,检查发现是Xcode的路径被改了 标记3的地方原来默认是没有内容的,点击它,然后会自动弹出一个选项,就是xcode的版本. 修改后,在命令行输入xcodebuild命令测试 ...
- SpringBoot 集成mongodb(2)多数据源配置
github:https://github.com/xiaozhuanfeng/mongoProj 现MongoDB有两个数据库: pom.xml: <!-- mongodb 配置 --> ...
- 阶段1 语言基础+高级_1-3-Java语言高级_1-常用API_1_第4节 ArrayList集合_16-ArrayList练习一_存储随机数
循环6次就是6.fori 循环子在外部+1就是得到的1到33的数字 list.fori遍历集合 自动生for循环的代码
- 阶段1 语言基础+高级_1-3-Java语言高级_04-集合_03 斗地主案例(单列)_1_斗地主案例的需求分析
洗牌用到集合工具类.Collections里面有个shuffle的方法 完整的需求分析
- 【HANA系列】SAP HANA启动出现ERROR
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列]SAP HANA启动出现ERRO ...
- 【ABAP系列】SAP F4搜索帮助的高级版
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[ABAP系列]SAP F4搜索帮助的高级版 ...
- day18 时间:time:,日历:calendar,可以运算的时间:datatime,系统:sys, 操作系统:os,系统路径操作:os.path,跨文件夹移动文件,递归删除的思路,递归遍历打印目标路径中所有的txt文件,项目开发周期
复习 ''' 1.跨文件夹导包 - 不用考虑包的情况下直接导入文件夹(包)下的具体模块 2.__name__: py自执行 '__main__' | py被导入执行 '模块名' 3.包:一系列模块的集 ...
- 应用安全 - 软件漏洞 - Jira漏洞汇总
CVE-2019-8451 ssrf url = url + '/plugins/servlet/gadgets/makeRequest?url=' + host + '@www.baidu.com/ ...
- 关于addEventListener中事件函数的this指向问题
看代码: //定义一个可见的盒子用于绑定点击事件 var box = document.getElementById('box'); box.x = 'box' //设置执行函数的对象属性 funct ...
- python列表-增强的赋值操作
增强赋值公式 (1) (2) (3) (4)