hadoop HA架构
什么是Hadoop?
http://hadoop.apache.org/
解决问题:
·海量数据的存储 (HDFS)
·海量数据的分析 (MapReduce)
·资源管理调度 (YARN)
集群规划:(这里namenode 与 ResourceManager 分开是为了更好理解是俩个集群;namenode是控制元数据,另一个是yarn框架),一般合在一起方便ssh认证(namenode要认证DN,ResourceManager要认证NM)
| 主机名 | IP | 安装软件 | 运行的进程 |
| hadoop01 | 192.168.109.137 | jdk、hadoop | namenode、DFSZKailoverController(zkfc) |
| hadoop02 | 192.168.109.138 | jdk、hadoop | namenode、DFSZKailoverController(zkfc) |
| hadoop03 | 192.168.109.139 | jdk、hadoop | ResourceManager |
| hadoop04 | 192.168.109.140 | jdk、hadoop | ResourceManager |
| hadoop05 | 192.168.109.141 | jdk、hadoop、zk | DataNode、NodeManager、JournalNode、QuorumPeerMain |
| hadoop06 | 192.168.109.142 | jdk、hadoop、zk | DataNode、NodeManager、JournalNode、QuorumPeerMain |
| hadoop07 | 192.168.109.143 | jdk、hadoop、zk | DataNode、NodeManager、JournalNode、QuorumPeerMain |
HA:俩个namenode,一个处于active状态,另一个处于standby状态。
hadoop普通用户安装;ssh认证
nn节点(认证自身和DN节点):
hadoop01机器:至少认证hadoop01、02、05、06、07
hadoop02机器:至少认证hadoop01、02、05、06、07
RM节点(认证自身和NM节点):
hadoop03机器:至少认证hadoop03、04、05、06、07
hadoop04机器:至少认证hadoop03、04、05、06、07
软件需求:

部署流程:(部署很简单,没什么营养,建议大家先了解hadoop生态,这样配置就很好理解了,有空我会再简单整理下理论)
http://hadoop.apache.org/
jdk1.8安装:(7台机器,简单说下一带而过)
cd /usr/local/soft/
tar -zxf jdk1.8.tar.gz
vim /etc/profile 追加(我们还可以追加hadoop的环境,就可也直接用命令)
export JAVA_HOME=/usr/local/soft/jdk
export HADOOP_HOME=/home/apps/hadoop-3.2.0
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile
zk集群安装:(3台机器:192.168.109.141,192.168.109.142,192.168.109.143,简单说下一带而过)
zk的常用作用:
1.统一命名服务(服务的发现与注册)
2.配置文件的管理(如分布式应用的配置)
3.集群的管理(zk+kafka)
4.共享锁
zk集群的选举~(略)
cd /usr/local/soft/
wget http://apache.fayea.com/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
tar -zxf zookeeper-3.4.14.tar.gz
cp /usr/local/soft/zookeeper-3.4.14/conf/zoo_sample.cfg /usr/local/soft/zookeeper-3.4.14/conf/zoo.cfg
vim /usr/local/soft/zookeeper-3.4.14/conf/zoo.cfg
dataDir=/tmp/zookeeper修改为dataDir=/data/zookeeper
server.1=hadoop05:2888:3888
server.2=hadoop06:2888:3888
server.3=hadoop07:2888:3888
创建数据目录:mkdir -pv /data/zookeeper
分别写入zk集群myid,与配置文件server.id对应,机器对应
echo "1" > /data/zookeeper/myid
echo "2" > /data/zookeeper/myid
echo "3" > /data/zookeeper/myid
ln -s /usr/local/soft/zookeeper-3.4.14 /usr/local/soft/zookeeper
启动:
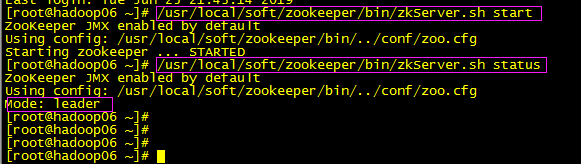
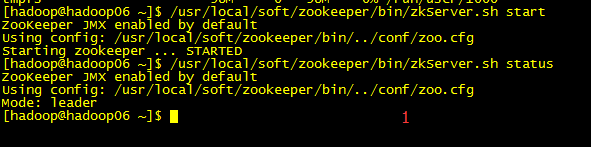
/usr/local/soft/zookeeper/bin/zkServer.sh start
查看状态:
/usr/local/soft/zookeeper/bin/zkServer.sh status
hadoop安装:(所有,7台机器)
http://hadoop.apache.org/
mkdir -pv /home/apps/
cd /usr/local/soft/
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz
tar -zxf hadoop-3.2.0.tar.gz -C /home/apps/
配置配置文件:
cd /home/apps/hadoop-3.2.0/etc/hadoop
1.1:修改vim hadoop-env.sh 首行加个JAVA_HOME环境
export JAVA_HOME=/usr/local/soft/jdk
1.2:修改vim core-site.xml
<configuration>
<!-- 指定hdfs的nameserver为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop的临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/apps/hadoop-3.2.0/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop05:2181,hadoop06:2181,hadoop07:2181</value>
</property>
</configuration>

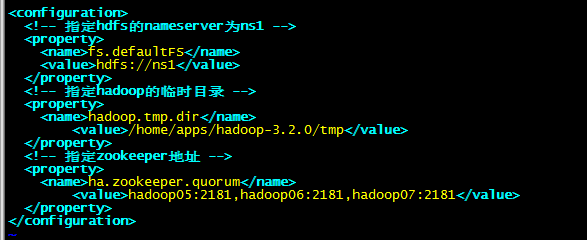
1.3:修改vim hdfs-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有俩个namenode,分别为nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hadoop01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hadoop01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hadoop02:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hadoop02:50070</value>
</property>
<!-- 指定namenode的元数据在 JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop05:8485;hadoop06:8485;hadoop07:8485/ns1</value>
</property>
<!-- 指定 JournalNode 在本地磁盘上存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/apps/hadoop-3.2.0/journaldata</value>
</property>
<!-- 开启namenode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免密登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
图(略)
扩展(已测):
1.hadoop DataNode节点的超时时间设置:
DataNode进程死亡或者网络故障造成DataNode无法与namenode通信,nn不会立即将该节点判断为死亡,是有一个时间,这个时间称超时时间
默认:10分钟30秒 计算公式:2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval 其中(heartbeat.recheck.interval 默认大小为5分钟;dfs.heartbeat.interval 默认3秒)
修改的话,vim hdfs-site.xml 添加(第一个 单位为毫秒,第二个为秒;测试效果的可以如下设置,结合页面管理查看效果)
<property>
<name>heartbeat.recheck.interval</name>
<value>2000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>1</value>
</property>
2.HDFS冗余数据块的自动删除、增加
在日常维护hadoop集群的过程中:
某个节点由于网络故障或者DataNode进程死亡,被nn判断为死亡,这个节点上的数据块的副本数就会少于我们定义的副本数,
HDFS马上自动开始数据块的容错拷贝;当故障恢复时,节点重新添加到集群中,此时节点上的数据块副本数就大于了我们定义的副本数目了,这些多余的副本会在一段时间(观察有点长)自动删除,这个时间间隔我们是可以设置的,这个时间的长短与数据块报告的间隔时间有关(DataNode会定期将当前该节点上所有的blk信息报告给nn)参数 dfs.blockreport.intervalMsec 就是控制这个报告间隔的参数:
修改的话:vim hdfs-site.xml
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>3600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
默认3600000毫秒,即1小时,所以我们看到的默认效果是一个小时,可以默认,具体根据自己环境修改
1.4:修改vim mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
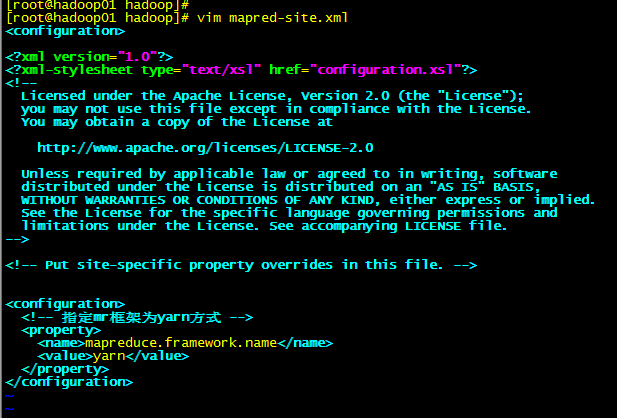
1.5:修改vim yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的 cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop03</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop04</value>
</property>
<!-- 指定zk集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop05:2181,hadoop06:2181,hadoop07:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
rm -rf /home/apps/hadoop-3.2.0/share/doc
配置好了~其他机器同步过去就好:
cd /home/apps
rsync -avz --progress -e ssh ./hadoop-3.2.0 192.168.109.138:/home/apps/
..
...
...
启动(初次启动严格按此顺序):
2.1:启动zk集群(上面已启动,查看下就好)
2.2:启动 journalnode (分别在hadoop05、hadoop06、hadoop07上执行)
/home/apps/hadoop-3.2.0/sbin/hadoop-daemon.sh start journalnode
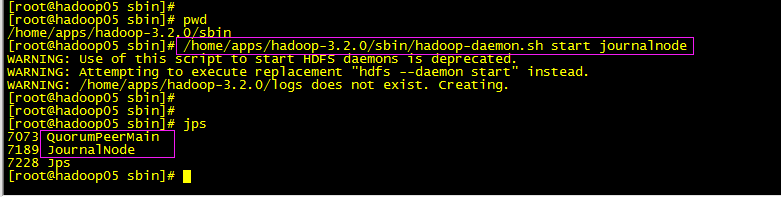
日志信息查看:tail -200f /home/apps/hadoop-3.2.0/logs/hadoop-root-journalnode-hadoop05.log
2.3:格式化HDFS,在任意一台namenode上如(hadoop01)上执行
/home/apps/hadoop-3.2.0/bin/hadoop namenode -format
#格式化后会根据core-site.xml中的hadoop.tmp.dir配置生成对应的目录:/home/apps/hadoop-3.2.0/tmp,然后拷贝目录到nn2上,#也可用命令在nn2上生成,命令如下
/home/apps/hadoop-3.2.0/bin/hdfs namenode -bootstrapStandby
报错:

解决:(还是配置文件写漏了单词...配置文件尽量复制好了,我这核对花了很多时间,将所有程序改成了hadoop用户运行)

再次格式化:
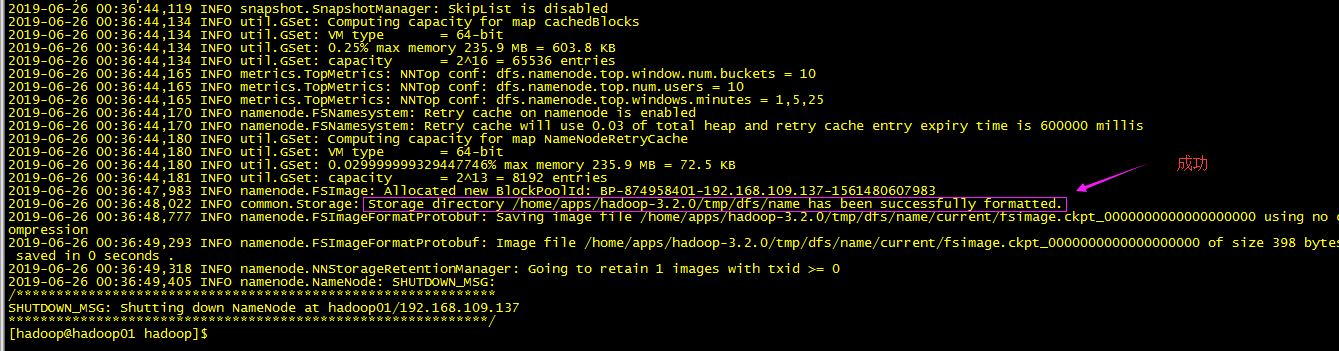
注意首次启动为保持2台namenode的fsimage一致:
方法1:我们手动将tmp目录拷贝过去
rsync -avz --progress -e ssh ./tmp hadoop02:/home/apps/hadoop-3.2.0/
方法2:在nn2上执行命令生成(建议用方法2),要先建议ssh认证 和 slave文件
/home/apps/hadoop-3.2.0/bin/hdfs namenode -bootstrapStandby
2.4:格式化ZKFC(在hadoop01上执行就可以):ZKFC是用来做namenode状态切换管理的,格式化就是在zookeeper上写一些初始化信息
/home/apps/hadoop-3.2.0/bin/hdfs zkfc -formatZK

我们可以去zk集群查看信息:
/usr/local/soft/zookeeper/bin/zkCli.sh
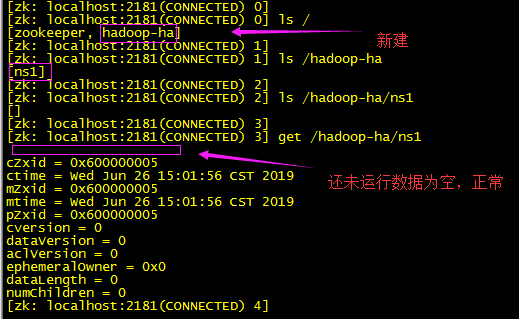
2.5:启动HDFS(在nn其中一台启动就好,如:hadoop01) 查看了启动脚本:/home/apps/hadoop-3.2.0/sbin/start-dfs.sh发现新版与老版本有点不同,读取节点配置老版本(slaves文件),新版本(/home/apps/hadoop-3.2.0/etc/hadoop/workers文件)
vim /home/apps/hadoop-3.2.0/etc/hadoop/workers
hadoop05
hadoop06
hadoop07
修改配置记得同步其他机器:
rsync -avz --progress -e ssh ./workers hadoop02:/home/apps/hadoop-3.2.0/etc/hadoop/
...
...
启动:(启动前确保ssh认证做好)
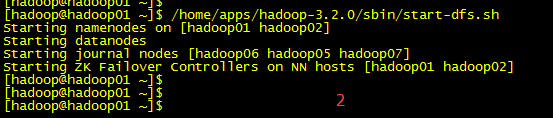
/home/apps/hadoop-3.2.0/sbin/start-dfs.sh
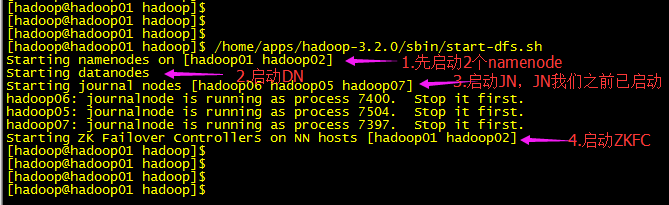
老版本会看DN 和 ZKFC这些启动每一个ssh的过程,
启动完毕后各对应节点jps命令查看下对应进程是否存在


2.6:启动YARN(我这的YARN集群部署在hadoop03和hadoop04,我们在hadoop03执行start-yarn.sh启动,【基于ssh认证】读的也是workers文件,nn集群和yarn(ResourceManager)集群分开能提高性能问题)
启动:/home/apps/hadoop-3.2.0/sbin/start-yarn.sh

各节点jps查看下:
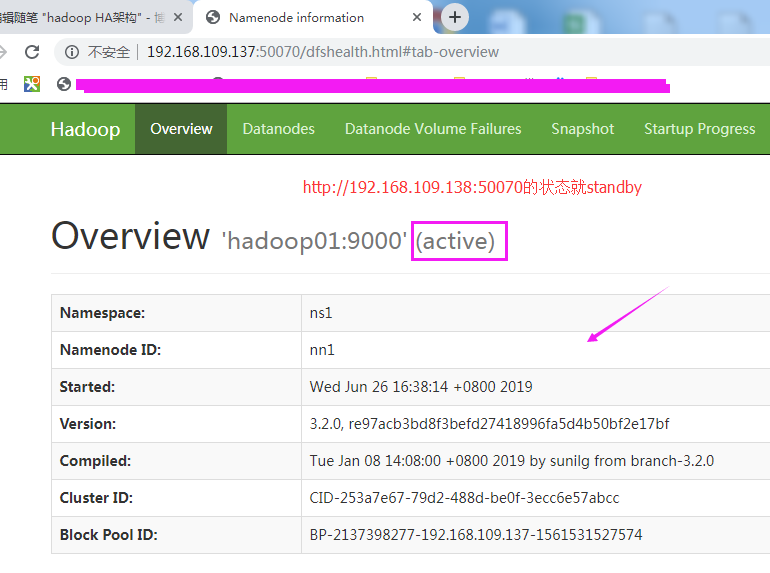
至此!hadoop配置完毕,可以统计浏览器访问:
namenode集群页面管理:
http://192.168.109.137:50070
http://192.168.109.138:50070
查看文件系统:
YARN集群管理页面:
http://192.168.109.139:8088
http://192.168.109.140:8088

以后启动就只要关注:zk集群启动、start-dfs.sh启动和start-yarn.sh

后面的测试体验~
1.上传文件:
先查看DM下(几台都看下):
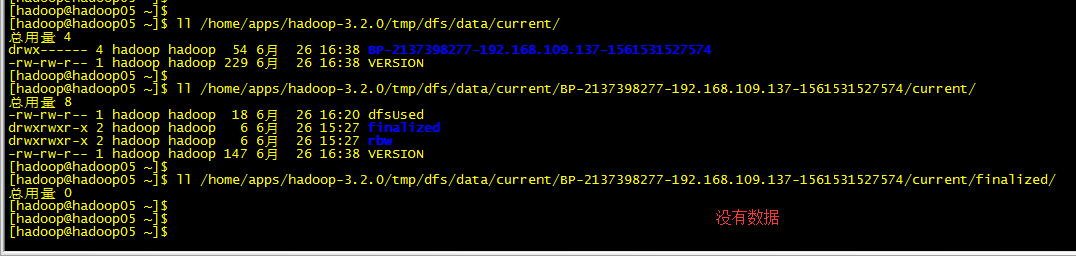
上传:(也可管理页面操作)

数据查看DM节点上查看:
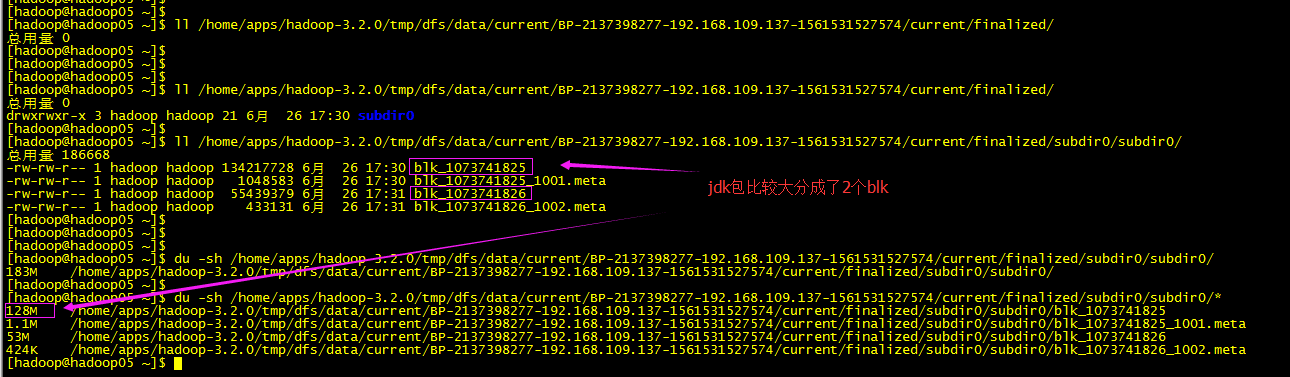
文件系统查看nn节点查看:

下载:
下载命令:/home/apps/hadoop-3.2.0/bin/hadoop fs -get /jdk1.8.tar.gz
删除:hadoop fs -rm /jdk1.8.tar.gz
hadoop fs --help
可以通过kill NN的进程,或关闭NN机器,测试集群的高可用性--上传下载
DataNode节点的添加...
hadoop HA架构的更多相关文章
- hadoop HA架构安装部署(QJM HA)
###################HDFS High Availability Using the Quorum Journal Manager########################## ...
- Hadoop HA 架构
为什么要用集群? 企业里面,多台机器 伪分布式 每一个角色都是一个进程 HDFS: NN SNN DN YARN: RM NM 大数据所有组件, 都是主从架构 master-slave HDFS读写请 ...
- Hadoop技术之Hadoop HA 机制学习
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:温球良 导语 最近分享过一次关于Hadoop技术主题的演讲,由于接触时间不长,很多技术细节认识不够,也没讲清楚,作为一个技术人员,本 ...
- hadoop HA 详解
NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDFS NameNode 和 JobTracker 都存在着单点问题,这其中以 NameNode ...
- hadoop HA学习
一 HDFS HA架构图 二 HDFS HA组件 Active NameNode和Standby NameNode 在NameNode的HA方案中有两个不同状态的NameNode,分别为活跃态(Act ...
- hadoop HA分布式集群搭建
概述 hadoop2中NameNode可以有多个(目前只支持2个).每一个都有相同的职能.一个是active状态的,一个是standby状态的.当集群运行时,只有active状态的NameNode是正 ...
- Hadoop(HA)分布式集群部署
Hadoop(HA)分布式集群部署和单节点namenode部署其实一样,只是配置文件的不同罢了. 这篇就讲解hadoop双namenode的部署,实现高可用. 系统环境: OS: CentOS 6.8 ...
- Hadoop HA 深度解析
社区hadoop2.2.0 release版本开始支持NameNode的HA,本文将详细描述NameNode HA内部的设计与实现. 为什么要Namenode HA? 1. NameNode High ...
- 1、hadoop HA分布式集群搭建
概述 hadoop2中NameNode可以有多个(目前只支持2个).每一个都有相同的职能.一个是active状态的,一个是standby状态的.当集群运行时,只有active状态的NameNode是正 ...
随机推荐
- [CF1093E]Intersection of Permutations:树套树+pbds
分析 裸的二维数点,博主用树状数组套平衡树写的,顺便pbds真好用. Update on 2018/12/20:再解释一下为什么是二维数点,第一维是\(la \leq i \leq ra\),第二维是 ...
- SpringCloud 教程 (六)断路器聚合监控(Hystrix Turbine)
一.Hystrix Turbine简介 看单个的Hystrix Dashboard的数据并没有什么多大的价值,要想看这个系统的Hystrix Dashboard数据就需要用到Hystrix Turbi ...
- assert出问题了?
刚学习Objective-C那会儿,还不太了解这个世界的惯用法,所以有些地方使用了C/C++的方式,虽然后来做过一定的修改, 但是项目中还是遗留了一些无关紧要的C/C++代码.比如对断言的运用. as ...
- Ecipse代码调试
1.设置断点 2.启动调试 在代码空白处中右击,选择Debug as —>1 Java Application 快捷键 表示当前实现继续运行直到下一个断点,快捷键为F8. 表示打断整个进程 表示 ...
- loadrunner常用函数整理
1.int web_reg_save_param("参数名","LB=左边界","RB=右边界",LAST); //注册函数,在参数值出 ...
- RAM: Residual Attention Module for Single Image Super-Resolution
1. 摘要 注意力机制是深度神经网络的一个设计趋势,其在各种计算机视觉任务中都表现突出.但是,应用到图像超分辨领域的注意力模型大都没有考虑超分辨和其它高层计算机视觉问题的天然不同. 作者提出了一个新的 ...
- VueX中直接修改数据报错,修改一维数组,二维数组,报错的原因
直接修改state中的的数据是不被允许的,会报错 这个时候可以使用三种种方式处理 第一种:使用拓展运算符,深拷贝一维数组或对象var arrA = [1,2,3,4]var a = [...arr]| ...
- java8 list转Map报错Collectors.toMap :: results in "Non-static method cannot be refernced from static context"
1.问题:java8 list转Map 报错Collectors.toMap :: results in "Non-static method cannot be refernced fro ...
- 阿里云DNS api接口 shell 更改DNS解析
可定时任务检查域名解析,调用alidns.sh更新DNS解析 #!/bin/bash # alidns.sh #https://www.cnblogs.com/elvi/p/11663910.html ...
- php-fpm启动不起来,php-fpm无法启动的一种情况
今天碰了一个很奇怪的问题,平时好好的php-fpm修改了一个参数后,突然启动不起来了,试着把参数还原.甚至用备份的配置文件还原都没办法启动php,而且不给任务启动错误的提示,纳闷!!!后来上网找了个资 ...