(一)Spark简介-Java&Python版Spark
Spark简介
视频教程:
1、优酷
2、YouTube
简介:
Spark是加州大学伯克利分校AMP实验室,开发的通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目Spark以其先进的设计理念,迅速成为社区的热门项目,围绕着Spark推出了Spark SQL、Spark Streaming、MLLib和GraphX等组件,也就是BDAS(伯克利数据分析栈),这些组件逐渐形成大数据处理一站式解决平台。
Spark使用Scala语言实现,它是一种面向对象、函数式编程语言,能够像操作本地集合对象一样轻松的操作分布式数据集。
Spark特点:
1、运行速度快
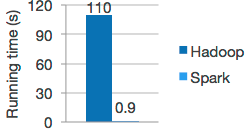
Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。
2、易用性好
Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。
3、通用性强
Spark生态圈即BDAS(伯克利数据分析栈)包含了Spark Core、Spark SQL、SparkStreaming、MLLib和GraphX等组件,这些组件分别处理:Spark Core提供内存计算框架、SparkStreaming的实时处理应用、Spark SQL的即时查询、MLlib的机器学习和GraphX的图处理,它们都是由AMP实验室提供,能够无缝的集成并提供一站式解决平台。

4、随处运行
Spark具有很强的适应性,能够读取HDFS、Cassandra、HBase、S3为持久层读写原生数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算。

Spark与Hadoop的对比(Spark的优势)

1、Spark的中间数据放到内存中,对于迭代运算效率更高
2、Spark比Hadoop更通用
3、Spark提供了统一的编程接口
4、容错性– 在分布式数据集计算时通过checkpoint来实现容错
5、可用性– Spark通过提供丰富的Scala, Java,Python API及交互式Shell来提高可用性
1、目前大数据处理场景
1. 复杂的批量处理(Batch Data Processing),偏重点在于处理海量数据的能力,至于处理速度可忍受,通常的时间可能是在数十分钟到数小时;
2. 基于历史数据的交互式查询(Interactive Query),通常的时间在数十秒到数十分钟之间
3. 基于实时数据流的数据处理(Streaming Data Processing),通常在数百毫秒到数秒之间
2、以上三种场景都有比较成熟的处理框架
1————————Hadoop的MapReduce来进行海量数据的批处理
2————————Impala进行交互式查询
3————————Storm分布式处理框架处理实时流式数据
3、总结:
1、Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小。
2、由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合。
3、数据量不是特别大,但是要求实时统计分析需求。
Spark成功案例:
1、腾讯
广点通是最早使用Spark的应用之一。腾讯大数据精准推荐借助Spark快速迭代的优势,围绕“数据+算法+系统”这套技术方案,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通投放系统上,支持每天上百亿的请求量。
2、Yahoo
Yahoo将Spark用在Audience Expansion中的应用。Audience Expansion是广告中寻找目标用户的一种方法:首先广告者提供一些观看了广告并且购买产品的样本客户,据此进行
学习,寻找更多可能转化的用户,对他们定向广告。Yahoo采用的算法是logistic regression。目前在Yahoo部署的Spark集群有112台节点,9.2TB内存。
3、淘宝
阿里搜索和广告业务,最初使用Mahout或者自己写的MR来解决复杂的机器学习,导致效率低而且代码不易维护。淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等。将Spark运用于淘宝的推荐相关算法上,同时还利用Graphx解决了许多生产问题,包括:基于度分布的中枢节点发现、基于最大连通图的社区发现、基于三角形计数的关系衡量、基于随机游走的用户属性传播等。
Spark运行模式:
|
Local |
本地模式 |
用于本地开发测试,本地还分为local单线程和local-cluster多线程。 |
|
On yarn |
集群模式 |
运行在yarn框架之上,由yarn负责资源管理,Spark负责任务调度和计算。 |
|
Standalone |
集群模式 |
典型的Mater-slave模式,Spark自带的模式。 |
Concepts:
Application:
Spark Application的概念和Hadoop MapReduce类似,指的是用户编写的Spark应用程序,包含了一个Driver 功能的代码和分布在集群中多个节点上运行的Executor代码。
Driver:
Spark中的Driver即运行上述Application的main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常用SparkContext代表Drive。
Executor:
Application运行在Worker 节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor。在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutorBackend,类似于Hadoop MapReduce中的YarnChild。一个CoarseGrainedExecutorBackend进程有且仅有一个executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task。每个CoarseGrainedExecutorBackend能并行运行Task的数量就取决于分配给它的CPU的个数了。
Cluster Manager:
指的是在集群上获取资源的外部服务,目前有:Standalone、Mesos、Yarn
Worker:
集群中任何可以运行Application代码的节点,类似于YARN中的NodeManager节点。在Standalone模式中指的就是通过Slave文件配置的Worker节点,在Spark on Yarn模式中指的就是NodeManager节点。
作业(Job):
包含多个Task组成的并行计算,往往由Spark Action催生,一个JOB包含多个RDD及作用于相应RDD上的各种Operation。
阶段(Stage):
每个Job会被拆分很多组Task,每组任务被称为Stage,也可称TaskSet,一个作业分为多个阶段。
任务(Task):
被送到某个Executor上的工作任务。
RDD(*):
是Resilient distributed datasets的简称,中文为弹性分布式数据集;是Spark最核心的模块和类。
DAGScheduler:
根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler。
TaskScheduler:
将Taskset提交给Worker node集群运行并返回结果。
Transformations:
是Spark API的一种类型,Transformation返回值还是一个RDD, 所有的Transformation采用的都是懒策略,如果只是将Transformation提交是不会执行计算的。
Action:
是Spark API的一种类型,Action返回值不是一个RDD,而是一个scala集合;计算只有在Action被提交的时候计算才被触发。
(一)Spark简介-Java&Python版Spark的更多相关文章
- (八)map,filter,flatMap算子-Java&Python版Spark
map,filter,flatMap算子 视频教程: 1.优酷 2.YouTube 1.map map是将源JavaRDD的一个一个元素的传入call方法,并经过算法后一个一个的返回从而生成一个新的J ...
- (四)Spark集群搭建-Java&Python版Spark
Spark集群搭建 视频教程 1.优酷 2.YouTube 安装scala环境 下载地址http://www.scala-lang.org/download/ 上传scala-2.10.5.tgz到m ...
- (九)groupByKey,reduceByKey,sortByKey算子-Java&Python版Spark
groupByKey,reduceByKey,sortByKey算子 视频教程: 1.优酷 2. YouTube 1.groupByKey groupByKey是对每个key进行合并操作,但只生成一个 ...
- (三)Spark-Hadoop集群搭建-Java&Python版Spark
Spark-Hadoop集群搭建 视频教程: 1.优酷 2.YouTube 配置java 启动ftp [root@master ~]# /etc/init.d/vsftpd restart 关闭 vs ...
- (七)Transformation和action详解-Java&Python版Spark
Transformation和action详解 视频教程: 1.优酷 2.YouTube 什么是算子 算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作. 算子分类: 具体: 1.Value ...
- (二)Spark-Linux环境准备-Java&Python版Spark
Spark-Linux环境准备 视频教程: 1.优酷 2.YouTube 硬软件环境 1.虚拟机:VMware Workstation 12 2.虚拟机操作系统:RedHat5u4,单核,1G内存,2 ...
- 自己动手实现智能家居之树莓派GPIO简介(Python版)
[前言] 一个热爱技术的人一定向往有一个科技感十足的环境吧,那何不亲自实践一下属于技术人的座右铭:“技术改变世界”. 就让我们一步步动手搭建一个属于自己的“智能家居平台”吧(不要对这个名词抬杠啦,技术 ...
- Spark入门(Python版)
Hadoop是对大数据集进行分布式计算的标准工具,这也是为什么当你穿过机场时能看到”大数据(Big Data)”广告的原因.它已经成为大数据的操作系统,提供了包括工具和技巧在内的丰富生态系统,允许使用 ...
- (六)Spark-Eclipse开发环境WordCount-Java&Python版Spark
Spark-Eclipse开发环境WordCount 视频教程: 1.优酷 2.YouTube 安装eclipse 解压eclipse-jee-mars-2-win32-x86_64.zip Java ...
随机推荐
- 【探索】机器指令翻译成 JavaScript
前言 前些时候研究脚本混淆时,打算先学一些「程序流程」相关的概念.为了不因太枯燥而放弃,决定想一个有趣的案例,可以边探索边学. 于是想了一个话题:尝试将机器指令 1:1 翻译 成 JavaScript ...
- eclipse 快捷键大全
注:因eclipse版本.电脑配置等原因 有些快捷键可能导致不可用(遇到些许问题可在下方评论) [Ct rl+T] 搜索当前接口的实现类 1. [ALT +/] 此快捷键为用户编辑的好帮手,能为 ...
- 探索ASP.NET MVC5系列之~~~2.视图篇(上)---包含XSS防御和异步分部视图的处理
其实任何资料里面的任何知识点都无所谓,都是不重要的,重要的是学习方法,自行摸索的过程(不妥之处欢迎指正) 汇总:http://www.cnblogs.com/dunitian/p/4822808.ht ...
- 07.LoT.UI 前后台通用框架分解系列之——强大的文本编辑器
LOT.UI分解系列汇总:http://www.cnblogs.com/dunitian/p/4822808.html#lotui LoT.UI开源地址如下:https://github.com/du ...
- ExtJS 4.2 业务开发(三)数据添加和修改
接上面的船舶管理业务,这里介绍添加和修改操作. 目录 1. 添加操作 2. 修改操作 3. 在线演示 1. 添加操作 1.1 创建AddShipWindow.js 在业务中的view目录下创建一个Ad ...
- CoreCRM 开发实录——开始之新项目的技术选择
2016年11月,接受了一个工作,是对"悟空CRM"进行一些修补.这是一个不错的 CRM,开源,并提供一个 SaaS 的服务.正好微软的 .NET Core 和 ASP.NET C ...
- 使用技术手段限制DBA的危险操作—Oracle Database Vault
概述 众所周知,在业务高峰期,某些针对Oracle数据库的操作具有很高的风险,比如修改表结构.修改实例参数等等,如果没有充分评估和了解这些操作所带来的影响,这些操作很可能会导致故障,轻则导致应用错误, ...
- MVC如何使用开源分页插件shenniu.pager.js
最近比较忙,前期忙公司手机端接口项目,各种开发+调试+发布现在几乎上线无问题了:虽然公司项目忙不过在期间抽空做了两件个人觉得有意义的事情,一者使用aspnetcore开发了个人线上项目(要说线上其实只 ...
- JQuery 选择器
选择器是JQuery的根基,在JQuery中,对事件的处理,遍历DOM和AJAX操作都依赖于选择器.如果能够熟练地使用选择器,不仅能简化代码,而且还可以事半功倍. JQuery选择器的优势 1.简洁的 ...
- java 设计模式
目录: 设计模式六大原则(1):单一职责原则 设计模式六大原则(2):里氏替换原则 设计模式六大原则(3):依赖倒置原则 设计模式六大原则(4):接口隔离原则 设计模式六大原则(5):迪米特法则 设计 ...