基于Node.js实现一个小小的爬虫
以前一直听说有爬虫这种东西,稍微看了看资料,貌似不是太复杂。
正好了解过node.js,那就基于它来个简单的爬虫。
1.本次爬虫目标:
从拉钩招聘网站中找出“前端开发”这一类岗位的信息,并作相应页面分析,提取出特定的几个部分如岗位名称、岗位薪资、岗位所属公司、岗位发布日期等。并将抓取到的这些信息,展现出来。
初始拉钩网站上界面信息如下:
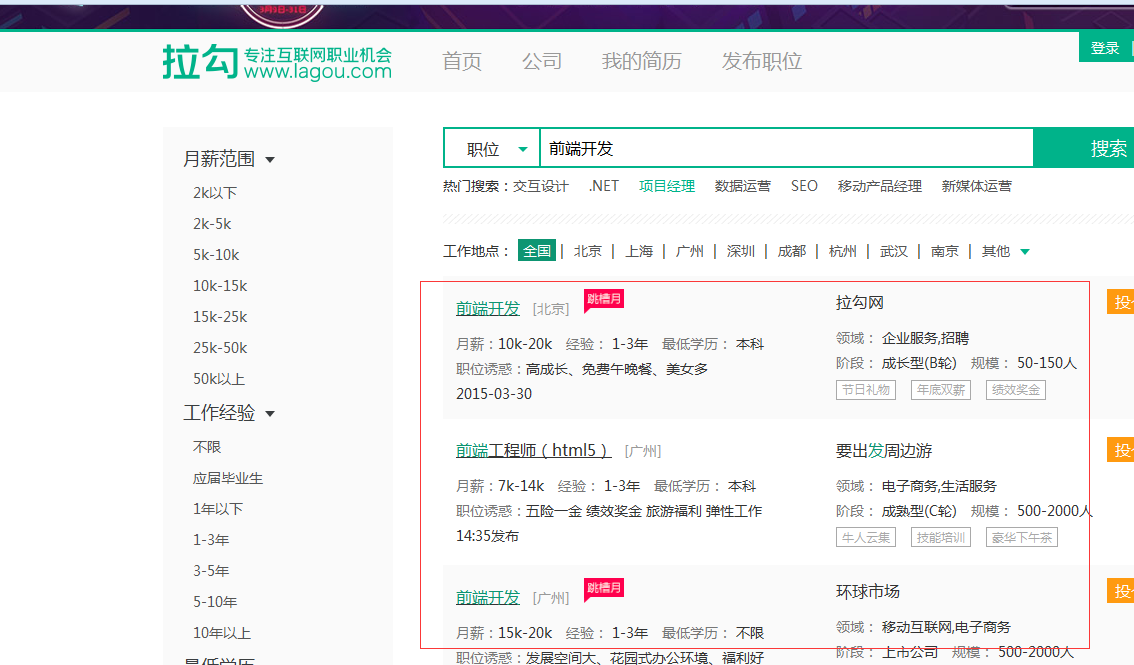
2.设计方案:
爬虫,实际上就是通过相应的技术,抓取页面上特定的信息。
这里主要抓取上图所示岗位列表部分相关的具体岗位信息。
首先,抓取,就得先有地址url:
这个链接就是岗位列表的第一页的网页地址。
我们通过对地址的参数部分进行分析,先不管其他选择的参数,只看最后的参数值:pn=1
我们的目的是通过page来各个抓取,所以设置为pn = page;

其次,爬虫要获取特定信息,就需要特定代表的标识符。
这里采用分析页面代码标签值、class值、id值来考虑。
通过Firebug对这一小部分审查元素


分析得出将要获取哪些信息则需要对特定的标识符进行处理。
3.代码编写:
按照预定的方案,考虑到node.js的使用情况,通过其内置http模块进行页面信息的获取,另外再通过cheerio.js模块对DOM的分析,进而转化为json格式的数据,控制台直接输出或者再次将json数据传送回浏览器端显示出来。
(cheerio.js这东西的用法很简单,详情可以自行搜索一下。其中最主要的也就下边这份代码了,其余的跟jQuery的用法差不多。
就是先将页面的数据load进来形成一个特定的数据格式,然后通过类似jq的语法,对数据进行解析处理)
var cheerio = require('cheerio'),
$ = cheerio.load('<h2 class="title">Hello world</h2>');
$('h2.title').text('Hello there!');
$('h2').addClass('welcome');
$.html();
//=> <h2 class="title welcome">Hello there!</h2>
采用express模块化开发,按要求建立好项目后。进入项目目录,执行npm install安装所需依赖包。如果还不了解express的可以 到这里看看
爬虫需要cheerio.js 所以另外require进来, 所以要另外 npm install cheerio
项目文件很多,为了简单处理,就只修改了其中三个文件。(index.ejs index.js style.css )
(1)直接修改routes路由中的index.js文件,这也是最核心的部分。
还是看代码吧,有足够的注释
var express = require('express');
var router = express.Router();
var http = require('http');
var cheerio = require('cheerio');
/* GET home page. */
router.get('/', function(req, res, next) {
res.render('index', { title: '简单nodejs爬虫' });
});
router.get('/getJobs', function(req, res, next) { // 浏览器端发来get请求
var page = req.param('page'); //获取get请求中的参数 page
console.log("page: "+page);
var Res = res; //保存,防止下边的修改
//url 获取信息的页面部分地址
var url = 'http://www.lagou.com/jobs/list_%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=';
http.get(url+page,function(res){ //通过get方法获取对应地址中的页面信息
var chunks = [];
var size = 0;
res.on('data',function(chunk){ //监听事件 传输
chunks.push(chunk);
size += chunk.length;
});
res.on('end',function(){ //数据传输完
var data = Buffer.concat(chunks,size);
var html = data.toString();
// console.log(html);
var $ = cheerio.load(html); //cheerio模块开始处理 DOM处理
var jobs = [];
var jobs_list = $(".hot_pos li");
$(".hot_pos>li").each(function(){ //对页面岗位栏信息进行处理 每个岗位对应一个 li ,各标识符到页面进行分析得出
var job = {};
job.company = $(this).find(".hot_pos_r div").eq(1).find("a").html(); //公司名
job.period = $(this).find(".hot_pos_r span").eq(1).html(); //阶段
job.scale = $(this).find(".hot_pos_r span").eq(2).html(); //规模
job.name = $(this).find(".hot_pos_l a").attr("title"); //岗位名
job.src = $(this).find(".hot_pos_l a").attr("href"); //岗位链接
job.city = $(this).find(".hot_pos_l .c9").html(); //岗位所在城市
job.salary = $(this).find(".hot_pos_l span").eq(1).html(); //薪资
job.exp = $(this).find(".hot_pos_l span").eq(2).html(); //岗位所需经验
job.time = $(this).find(".hot_pos_l span").eq(5).html(); //发布时间
console.log(job.name); //控制台输出岗位名
jobs.push(job);
});
Res.json({ //返回json格式数据给浏览器端
jobs:jobs
});
});
});
});
module.exports = router;
(2)node.js抓取的核心代码就是上面的部分了。
下一步就是将抓取到的数据展示出来,所以需要另一个页面,将views中的index.ejs模板修改一下
<!DOCTYPE html>
<html>
<head>
<title><%= title %></title>
<link rel='stylesheet' href='/stylesheets/style.css' />
</head>
<body>
<h3>【nodejs爬虫】 获取拉勾网招聘岗位--前端开发</h3>
<p>初始化完成 ...</p>
<p><button class="btn" id="btn0" onclick="cheerFetch(1)">点击开始抓取第一页</button></p>
<div class="container">
<!--<div class="jobs"> </div>-->
</div>
<div class="footer">
<p class="fetching">数据抓取中 ... 请稍后</p>
<button class="btn" id="btn1" onclick="cheerFetch(--currentPage)">抓取上一页</button>
<button class="btn" id="btn2" onclick="cheerFetch(++currentPage)">抓取下一页</button>
</div>
<script type="text/javascript" src="javascripts/jquery.min.js"></script>
<script type="text/javascript">
function getData(str){ //获取到的数据有杂乱..需要把前面部分去掉,只需要data(<em>......<em> data)
if(str){
return str.slice(str.lastIndexOf(">")+1);
}
} document.getElementById("btn1").style.visibility = "hidden";
document.getElementById("btn2").style.visibility = "hidden";
var currentPage = 0; //page初始0 function cheerFetch(_page){ //抓取数据处理函数
if(_page == 1){
currentPage = 1; //开始抓取则更改page
}
$(document).ajaxSend(function(event, xhr, settings) { //抓取中...
$(".fetching").css("display","block");
});
$(document).ajaxSuccess(function(event, xhr, settings) { //抓取成功
$(".fetching").css("display","none");
});
$.ajax({ //开始发送ajax请求至路径 /getJobs 进而作页面抓取处理
data:{page:_page}, //参数 page = _page
dataType: "json",
type: "get",
url: "/getJobs",
success: function(data){ //收到返回的json数据
console.log(data);
var html = "";
$(".container").empty();
if(data.jobs.length == 0){
alert("Error2: 未找到数据..");
return;
}
for(var i=0;i<data.jobs.length;i++){ //遍历数据并提取处理
var job = data.jobs[i];
html += "<div class='jobs'><p><span >岗位序号:</span> "+((i+1)+15*(currentPage-1))+"</p>"+
"<p>岗位名称:<a href='"+job.src+"'target='_blank'>"+job.name+"</a></p>"+
"<p><span >岗位所在公司:</span> "+job.company+"</p>"+
"<p><span>公司阶段:</span> "+getData(job.period)+"</p>"+
"<p><span>岗位规模:</span> "+getData(job.scale)+"</p>"+
"<p><span>岗位所在城市:</span> "+job.city+"</p>"+
"<p><span>岗位薪资:</span> "+getData(job.salary)+"</p>"+
"<p><span>岗位最低经验要求:</span> "+getData(job.exp)+"</p>"+
"<p><span>岗位发布时间:</span> "+getData(job.time)+"</p>"+
"</div>"
} $(".container").append(html); //展现至页面
if(_page == 1){
document.getElementById("btn1").style.visibility = "hidden";
document.getElementById("btn2").style.visibility = "visible";
}else if(_page > 1){
document.getElementById("btn1").style.visibility = "visible";
document.getElementById("btn2").style.visibility = "visible";
}
},
error: function(){
alert("Error1: 未找到数据..");
}
});
} </script>
</body>
</html>
(3)当然了,也少不了样式部分的简单修改 public文件下的 style.css
body {
padding: 20px 50px;
font: 14px "Lucida Grande", Helvetica, Arial, sans-serif;
}
a {
color: #00B7FF;
cursor: pointer;
}
.container{position: relative;width: 1100px;overflow: hidden;zoom:;}
.jobs{margin: 30px; float: left;}
.jobs span{ color: green; font-weight: bold;}
.btn{cursor: pointer;}
.fetching{display: none;color: red;}
.footer{clear: both;}
基本改动的也就这三个文件了。
所以,如果要测试一下的话,可以新建项目后,直接修改对应的那三个文件。
修改成功后,就可以测试一下了。
3.测试结果
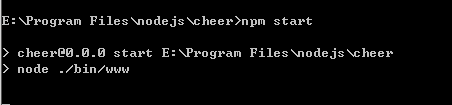
1) 首先在控制台中执行 npm start
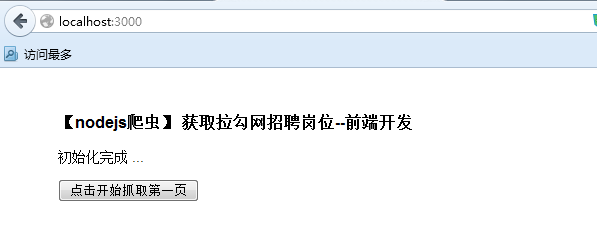
2) 接下来在浏览器输入http://localhost:3000/开始访问
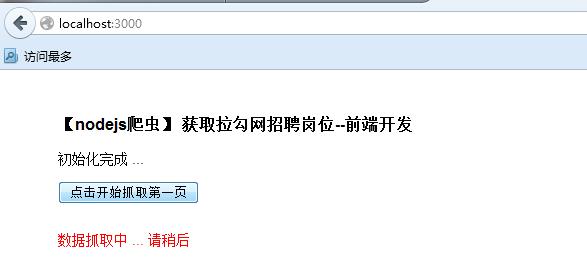
3) 点击开始抓取(这里每次抓取15条,也就是原网址对应的15条)

...

4) 再抓取下一页也还是可以的~

5) 再来看看控制台的输出

看看看看...多简单的小爬虫呀..
简单归简单,最重要的是,知道了最基本的处理形式。
基于Node.js实现一个小小的爬虫的更多相关文章
- 用node.js写一个简单爬虫,并将数据导出为 excel 文件
引子 最近折腾node,最开始像无头苍蝇一样到处找资料,然而多数没什么卵用,都在瞎比比.在一阵瞎搞后,我来分享一下初步学习node的三个过程: 1 撸一遍NODE入门,对其有个基本的了解: 2 撸一遍 ...
- 基于node.js制作爬虫教程
前言:最近想学习node.js,突然在网上看到基于node的爬虫制作教程,所以简单学习了一下,把这篇文章分享给同样初学node.js的朋友. 目标:爬取 http://tweixin.yueyishu ...
- 基于Node.js的强大爬虫 能直接发布抓取的文章哦
基于Node.js的强大爬虫 能直接发布抓取的文章哦 基于Node.js的强大爬虫能直接发布抓取的文章哦!本爬虫源码基于WTFPL协议,感兴趣的小伙伴们可以参考一下 一.环境配置 1)搞一台服务器,什 ...
- NodeBB – 基于 Node.js 的开源论坛系统
NodeBB 是一个更好的论坛平台,专门为现代网络打造.它是免费的,易于使用. NodeBB 论坛软件是基于 Node.js 开发,支持 Redis 或 MongoDB 的数据库.它利用 Web So ...
- 基于 Node.js 平台,快速、开放、极简的 web 开发框架。
资料地址:http://www.expressjs.com.cn/ Express 基于 Node.js 平台,快速.开放.极简的 web 开发框架. $ npm install express -- ...
- Fenix – 基于 Node.js 的桌面静态 Web 服务器
Fenix 是一个提供给开发人员使用的简单的桌面静态 Web 服务器,基于 Node.js 开发.您可以同时在上面运行任意数量的项目,特别适合前端开发人员使用. 您可以通过免费的 Node.js 控制 ...
- 基于Node.js + jade + Mongoose 模仿gokk.tv
原文摘自我的前端博客,欢迎大家来访问 http://www.hacke2.cn 关于gokk 大学的娱乐活动基本就是在寝室看电影了→_→,一般都会选择去goxiazai.cc上看,里面的资源多,质量高 ...
- 基于Node.js的实时推送 juggernaut
基于Node.js的实时推送 juggernaut Juggernaut 基于 Node.js 构建.为浏览器和服务器端提供一个实时的连接,可在客户端和服务器端进行数据的实时推送,适合多角色游戏.聊天 ...
- 基于node.js构建微服务中的mock服务
缘起 由于现在微服务越来越火了,越来越多的微服务融入到了日常开发当中.在开发微服务的时候,经常会遇到一个问题由于依赖于其他服务,导致你的进度受到阻碍.使你不得不先mock出你期望调用依赖服务的输出,来 ...
随机推荐
- ASP.NET路由模型解析
大家好,我又来吹牛逼了 ~-_-~ 转载请注明出处:来自吹牛逼之<ASP.NET路由模型解析> 背景:很多人知道Asp.Net中路由怎么用的,却不知道路由模型内部的运行原理,今天我就给大家 ...
- Partition:Partiton Scheme是否指定Next Used?
在SQL Server中,为Partition Scheme多次指定Next Used,不会出错,最后一次指定的FileGroup是Partition Scheme的Next Used,建议,在执行P ...
- Xamarin+Prism开发详解二:Xaml文件如何简单绑定Resources资源文件内容
我们知道在UWP里面有Resources文件xxx.resx,在Android里面有String.Xml文件等.那跨平台如何统一这些类别不一的资源文件以及Xaml设计文件如何绑定这些资源?应用支持多国 ...
- <译>通过PowerShell工具跨多台服务器执行SQL脚本
有时候,当我们并没有合适的第三方工具(大部分需要付费)去管理多台数据库服务器,那么如何做最省力.省心呢?!Powershell一个强大的工具,可以很方便帮到我们处理日常的数据库维护工作 .简单的几步搞 ...
- npm 使用小结
本文内容基于 npm 4.0.5 概述 npm (node package manager),即 node 包管理器.这里的 node 包就是指各种 javascript 库. npm 是随同 Nod ...
- AEAI DP V3.6.0 升级说明,开源综合应用开发平台
AEAI DP综合应用开发平台是一款扩展开发工具,专门用于开发MIS类的Java Web应用,本次发版的AEAI DP_v3.6.0版本为AEAI DP _v3.5.0版本的升级版本,该产品现已开源并 ...
- centos安装nodejs
1.下载安装nodejs wget http://nodejs.org/dist/v0.10.25/node-v0.10.25.tar.gz compat--c++ tar -xf node-v0.1 ...
- [转载]MVVM模式原理分析及实践
没有找到很好的MVVM模式介绍文章,简单找了一篇,分享一下.MVVM实现了UI\UE设计师(Expression Blend 4设计界面)和软件工程师的合理分工,在SilverLight.WPF.Wi ...
- Android AppBar
AppBar官方文档摘记 2016-6-12 本文摘自Android官方文档,为方便自己及其他开发者朋友阅读. 章节目录为"Develop > Training > Best P ...
- Leetcode 笔记 101 - Symmetric Tree
题目链接:Symmetric Tree | LeetCode OJ Given a binary tree, check whether it is a mirror of itself (ie, s ...