Hadoop 2.6 MapReduce运行原理详解
市面上的hadoop权威指南一类的都是老版本的书籍了,索性学习并翻译了下最新版的Hadoop:The Definitive Guide, 4th Edition与大家共同学习。
我们通过提交jar包,进行MapReduce处理,那么整个运行过程分为五个环节:
1、向client端提交MapReduce job.
2、随后yarn的ResourceManager进行资源的分配.
3、由NodeManager进行加载与监控containers.
4、通过applicationMaster与ResourceManager进行资源的申请及状态的交互,由NodeManagers进行MapReduce运行时job的管理.
5、通过hdfs进行job配置文件、jar包的各节点分发。
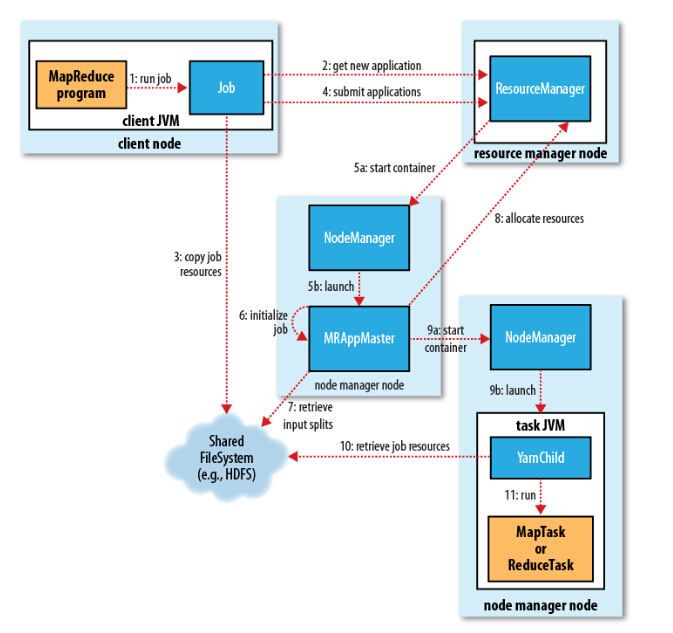
Job 提交过程
job的提交通过调用submit()方法创建一个JobSubmitter实例,并调用submitJobInternal()方法。整个job的运行过程如下:
1、向ResourceManager申请application ID,此ID为该MapReduce的jobId。
2、检查output的路径是否正确,是否已经被创建。
3、计算input的splits。
4、拷贝运行job 需要的jar包、配置文件以及计算input的split 到各个节点。
5、在ResourceManager中调用submitAppliction()方法,执行job
Job 初始化过程
1、当resourceManager收到了submitApplication()方法的调用通知后,scheduler开始分配container,随之ResouceManager发送applicationMaster进程,告知每个nodeManager管理器。
2、由applicationMaster决定如何运行tasks,如果job数据量比较小,applicationMaster便选择将tasks运行在一个JVM中。那么如何判别这个job是大是小呢?当一个job的mappers数量小于10个,只有一个reducer或者读取的文件大小要小于一个HDFS block时,(可通过修改配置项mapreduce.job.ubertask.maxmaps,mapreduce.job.ubertask.maxreduces以及mapreduce.job.ubertask.maxbytes 进行调整)
3、在运行tasks之前,applicationMaster将会调用setupJob()方法,随之创建output的输出路径(这就能够解释,不管你的mapreduce一开始是否报错,输出路径都会创建)
Task 任务分配
1、接下来applicationMaster向ResourceManager请求containers用于执行map与reduce的tasks(step 8),这里map task的优先级要高于reduce task,当所有的map tasks结束后,随之进行sort(这里是shuffle过程后面再说),最后进行reduce task的开始。(这里有一点,当map tasks执行了百分之5%的时候,将会请求reduce,具体下面再总结)
2、运行tasks的是需要消耗内存与CPU资源的,默认情况下,map和reduce的task资源分配为1024MB与一个核,(可修改运行的最小与最大参数配置,mapreduce.map.memory.mb,mapreduce.reduce.memory.mb,mapreduce.map.cpu.vcores,mapreduce.reduce.reduce.cpu.vcores.)
Task 任务执行
1、这时一个task已经被ResourceManager分配到一个container中,由applicationMaster告知nodemanager启动container,这个task将会被一个主函数为YarnChild的java application运行,但在运行task之前,首先定位task需要的jar包、配置文件以及加载在缓存中的文件。
2、YarnChild运行于一个专属的JVM中,所以任何一个map或reduce任务出现问题,都不会影响整个nodemanager的crash或者hang。
3、每个task都可以在相同的JVM task中完成,随之将完成的处理数据写入临时文件中。
Mapreduce数据流
运行进度与状态更新
1、MapReduce是一个较长运行时间的批处理过程,可以是一小时、几小时甚至几天,那么Job的运行状态监控就非常重要。每个job以及每个task都有一个包含job(running,successfully completed,failed)的状态,以及value的计数器,状态信息及描述信息(描述信息一般都是在代码中加的打印信息),那么,这些信息是如何与客户端进行通信的呢?
2、当一个task开始执行,它将会保持运行记录,记录task完成的比例,对于map的任务,将会记录其运行的百分比,对于reduce来说可能复杂点,但系统依旧会估计reduce的完成比例。当一个map或reduce任务执行时,子进程会持续每三秒钟与applicationMaster进行交互。
Job 完成
最终,applicationMaster会收到一个job完成的通知,随后改变job的状态为successful。最终,applicationMaster与task containers被清空。
Shuffle与Sort
从map到reduce的过程,被称之为shuffle过程,MapReduce使到reduce的数据一定是经过key的排序的,那么shuffle是如何运作的呢?
当map任务将数据output时,不仅仅是将结果输出到磁盘,它是将其写入内存缓冲区域,并进行一些预分类。
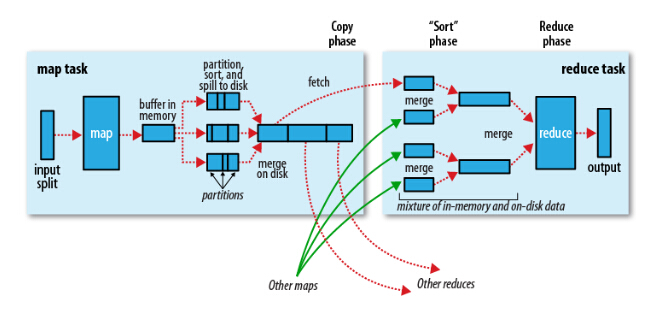
1、The Map Side
首先map任务的output过程是一个环状的内存缓冲区,缓冲区的大小默认为100MB(可通过修改配置项mpareduce.task.io.sort.mb进行修改),当写入内存的大小到达一定比例,默认为80%(可通过mapreduce.map.sort.spill.percent配置项修改),便开始写入磁盘。
在写入磁盘之前,线程将会指定数据写入与reduce相应的patitions中,最终传送给reduce.在每个partition中,后台线程将会在内存中进行Key的排序,(如果代码中有combiner方法,则会在output时就进行sort排序,这里,如果只有少于3个写入磁盘的文件,combiner将会在outputfile前启动,如果只有一个或两个,那么将不会调用)
这里将map输出的结果进行压缩会大大减少磁盘IO与网络传输的开销(配置参数mapreduce.map .output.compress 设置为true,如果使用第三方压缩jar,可通过mapreduce.map.output.compress.codec进行设置)
随后这些paritions输出文件将会通过HTTP发送至reducers,传送的最大启动线程通过mapreduce.shuffle.max.threads进行配置。
2、The Reduce Side
首先上面每个节点的map都将结果写入了本地磁盘中,现在reduce需要将map的结果通过集群拉取过来,这里要注意的是,需要等到所有map任务结束后,reduce才会对map的结果进行拷贝,由于reduce函数有少数几个复制线程,以至于它可以同时拉取多个map的输出结果。默认的为5个线程(可通过修改配置mapreduce.reduce.shuffle.parallelcopies来修改其个数)
这里有个问题,那么reducers怎么知道从哪些机器拉取数据呢?
当所有map的任务结束后,applicationMaster通过心跳机制(heartbeat mechanism),由它知道mapping的输出结果与机器host,所以reducer会定时的通过一个线程访问applicationmaster请求map的输出结果。
Map的结果将会被拷贝到reduce task的JVM的内存中(内存大小可在mapreduce.reduce.shuffle.input.buffer.percent中设置)如果不够用,则会写入磁盘。当内存缓冲区的大小到达一定比例时(可通过mapreduce.reduce.shuffle.merge.percent设置)或map的输出结果文件过多时(可通过配置mapreduce.reduce.merge.inmen.threshold),将会除法合并(merged)随之写入磁盘。
这时要注意,所有的map结果这时都是被压缩过的,需要先在内存中进行解压缩,以便后续合并它们。(合并最终文件的数量可通过mapreduce.task.io.sort.factor进行配置) 最终reduce进行运算进行输出。
参考文献:《Hadoop:The Definitive Guide, 4th Edition》
Hadoop 2.6 MapReduce运行原理详解的更多相关文章
- Nginx与PHP-FPM运行原理详解
目录 1. 代理与反向代理 1. 正向代理:访问google.com 2. 反向代理:通过反向代理实现负载均衡 2. 初识Nginx与PHP-FPM 1. Nginx是什么 2. CGI与FastCG ...
- JVM运行原理详解
1.JVM简析: 作为一名Java使用者,掌握JVM的体系结构也是很有必要的. 说起Java,我们首先想到的是Java编程语言,然而事实上,Java是一种技术,它由四方面组成:Ja ...
- 「JVM」知识点详解一:JVM运行原理详解
前言 JVM 一直都是面试的必考点,大家都知道,但是要把它搞清楚又好像不是特别容易.JVM 的知识点太散,不系统,今天带大家详细的了解一下jvm的运行原理. 正文 1 什么是JVM? JVM是Java ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
- Kubernetes学习之路(二十)之K8S组件运行原理详解总结
目录 一.看图说K8S 二.K8S的概念和术语 三.K8S集群组件 1.Master组件 2.Node组件 3.核心附件 四.K8S的网络模型 五.Kubernetes的核心对象详解 1.Pod资源对 ...
- MapReduce工作原理详解
文章概览: 1.MapReduce简介 2.MapReduce有哪些角色?各自的作用是什么? 3.MapReduce程序执行流程 4.MapReduce工作原理 5.MapReduce中Shuffle ...
- hadoop高可用安装和原理详解
本篇主要从hdfs的namenode和resourcemanager的高可用进行安装和原理的阐述. 一.HA安装 1.基本环境准备 1.1.1.centos7虚拟机安装,详情见VMware安装Cent ...
- Nginx+Php-fpm运行原理详解
一.代理与反向代理 现实生活中的例子 1.正向代理:访问google.com 如上图,因为google被墙,我们需要vpnFQ才能访问google.com. vpn对于“我们”来说,是可以感知到的(我 ...
- 正则表达式的运行原理详解(NFA,多分支原理)
原文:https://blog.csdn.net/yx0628/article/details/82722166
随机推荐
- osg,qt编译的一些问题
osg编译例子的时候,打开文件就出问题,可能是一些不兼容的问题 qt编译的是时候要添加qt和vs2010的整合工具,这样才能把 vs2010里面的QTDIR变量和环境变量QTDIR关联起来 同是右击文 ...
- PDF 补丁丁 0.4.3.1518 测试版发布:书签编辑器新增升级书签功能、优化PDF文档阅览器
新的 PDF 补丁丁测试版上线啦! 新版本增加了升级书签的功能(见工具栏的“←”按钮),可以方便地将下级书签升级为上级书签. 另外,新版本还增强了书签编辑器功能中的 PDF阅读器,从之前的单页阅读模式 ...
- Linux (Ubuntu) 下配置VPN服务器
昨天网上找了下VPN的相关信息,居然各种撞墙,特别郁闷,自己不容易找到的东西,记录下VPN的配置信息 ubuntu 13.1下配置VPN ,采用PPTP实现, 第一步.安装pptpd,没有安装包记得 ...
- 移动端web之像素基础
px:css pixels逻辑像素,浏览器使用的抽象单位 dp,pt :device independent pixels 设备无关像素 dpr:devicePixelRatio 设备像素缩放比 计算 ...
- git修改已提交记录的注释
已提交暂存区但还未提交远端仓库 命令:git commit --amend -m 已提交远端仓库 命令:git rebase 可以参考:http://www.cnblogs.com/dudu/p/47 ...
- ExtJs 4 中的MVC应用架构
一.ExtJs 4.x MVC模式的原理与作用 大规模客户端应用通常不好实现不好组织也不好维护,因为功能和人力的不断增加,这些应用的规模很快就会超出掌控能力,ExtJS4带来了一个新的应用架构,不但可 ...
- 如何使用DDMS
Android DDMS如何使用? DDMS 的全称是Dalvik Debug Monitor Service,它为我们提供例如:为测试设备截屏,针对特定的进程查看正在运行的线程以及堆信息.Logca ...
- Nodejs学习笔记(一)--- 简介及安装Node.js开发环境
目录 学习资料 简介 安装Node.js npm简介 开发工具 Sublime Node.js开发环境配置 扩展:安装多版本管理器 学习资料 1.深入浅出Node.js http://www.info ...
- sqlite以及python的应用
有点乱,自己平时,遇到了就记下来,所以没整理. 数据库sqlite,以及Qt对数据库的操作 sql学习网址: sqlite官网:http://www.sqlite.org http://www.w3s ...
- volatile简介
volatile简介 java语言提供了一种稍弱的内存同步机制,即volatile变量.用来确保将变量的更新操作通知到其它线程,保证了新值能立即同步到主内存,以及每次使用前立即从内存刷新.当变量声明为 ...