Hive0.13.1介绍及安装部署
一、简介
hive由Facebook开源用于解决海量结构化日志的数据统计。hive是基于Hadoop的一个数据仓库工具,是基于Hadoop之上的,文件是存储在HDFS上的,底层运行的是MR程序。hive可以将结构化的数据文件映射成一张表,并提供类SQL查询功能。
二、HIVE特点
- 构建在Hadoop之上的数据仓库
- 使用HQL作为查询接口
- 使用HDFS存储
- 使用MapReduce计算
- 本质:将HQL转化成MapReduce程序
- 灵活性和扩展性比较好:支持UDF、自定义存储格式等
- 适合离线数据处理
- hive在Hadoop生态系统中的位置:
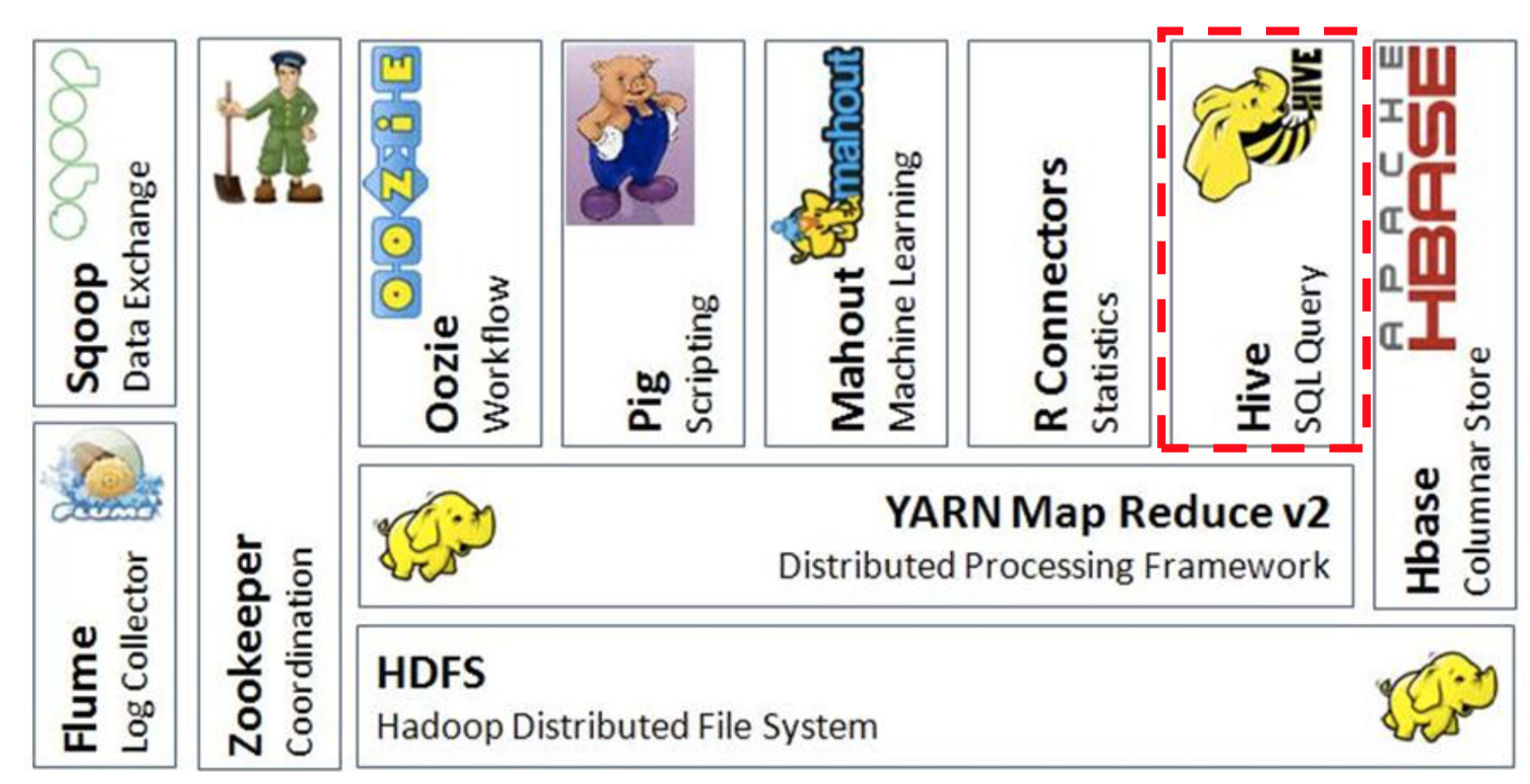
三、hive体系结构

- 用户接口:
- ClientCLI(hive shell)、JDBC/ODBC(java访问hive),WEBUI(浏览器访问hive)
- 用户接口:
- 元数据:Metastore
- 元数据包括:表名、表所属数据库、表的拥有者、列/分区字段、表的类型(是否外部表)、表数据所在目录等
- Hadoop
- 使用HDFS存储,使用MR计算
- 驱动器:Driver
- 包含:解析器、编译器、优化器、执行器
- 解析器
- 将SQL字符串转换成抽象语法书AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误等
- 编译器
- 将AST编译生成逻辑执行计划
- 优化器
- 对逻辑执行计划进行优化
- 执行器
- 把逻辑执行计划转化成可以运行的物理计划。对hive来说,就是MR/TEZ/SPARK
- 元数据:Metastore
四、hive优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 避免了去写MR,减少开发人员的学习成本
- 统一的元数据管理,可以与impala/spark等共享元数据
- 易扩展(HDFS+MR:可以扩展集群规模;支持UDF、UDAF、UDTF等自定义函数)
五、使用场景
- 数据的离线处理,比如:日志分析,海量结构化数据离线分析...
- Hive的执行延迟比较高,因此hive常用于数据分析的,对实时性要求不高的场合
- Hive的优势在于处理大数据,对于小数据没有优势,因为Hive的执行延迟比较高
六、hive部署安装
*注意:安装部署hive之前,首先要安装完成jdk和hadoop。如有需要,可以查看博客:Haoop2.5.0伪分布式环境搭建。
step1:解压安装包
-bin.tar.gz -C /opt/software/
step2:在hdfs上创建hive所需要的目录及权限修改
hdfs dfs -mkdir /tmp hdfs dfs -mkdir -p /user/hive/warehouse hdfs dfs -chmod g+w /tmp hdfs dfs -chmod g+w /user/hive/warehouse
step3:修改hive-env.sh中HADOOP_HOME及HIVE_CONF_DIR属性值,注意改名
# Set HADOOP_HOME to point to a specific hadoop install directory HADOOP_HOME=/opt/software/hadoop- # Hive Configuration Directory can be controlled by: export HIVE_CONF_DIR=/opt/software/hive--bin/conf
step4:hive元数据信息默认是使用的Derby数据库,derby数据库只支持一个hive连接,修改为使用关系型数据库mysql存储hive元数据信息。
- 安装mysql数据库
# 查询系统中没有mysql sudo rpm -qa | grep mysql # 卸载自带的mysql库 -.el6_3.x86_64 # 使用yum进行mysql的安装 sudo yum -y install mysql-server # 查看mysqld服务是否开启 sudo service mysqld status # 启动mysql服务 sudo service mysqld start # 设置开机启动mysqld sudo chkconfig mysqld on # 设置mysql管理员root的密码 mysqladmin -u root password '
- 设置mysql的连接权限
mysql -uroot -p # 进入mysql命令行grant all privileges on *.* to ' with grant option;flush privileges; # 刷新quit; # 退出sudo service mysqld restart # 重启mysql服务
- 自定义hive的配置文件,从默认的文件(hive-default.xml.template)拷贝一份过来,重命名为hive-site.xml,然后删除其中的内容,添加以下内容:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. --> <configuration> <property> <name>hive.exec.mode.local.auto</name> <value>true</value> </property> <property> <name>hive.exec.mode.local.auto.input.files.max</name> <value>100</value> </property> <property> <name>hive.exec.mode.local.auto.inputbytes.max</name> <value>13421772800000</value> </property> <property> <name>hive.cli.print.header</name> <value>true</value> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://bigdata01:3306/hive?createDatabaseIfNotExist=true&useSSL=true&useUnicode=true&characterEncoding=UTF-8</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://bigdata01:9083</value> </property> <property> <name>hive.server2.thrift.port</name> <value>10013</value> </property> </configuration> - 拷贝mysql驱动到/opt/software/hive-0.13.1-bin/lib/目录下
至此,hive部署完成,即可通过命令行输入hive进入hive环境。
Hive0.13.1介绍及安装部署的更多相关文章
- ubuntu12.04+hadoop2.2.0+zookeeper3.4.5+hbase0.96.2+hive0.13.1伪分布式环境部署
目录: 一.hadoop2.2.0.zookeeper3.4.5.hbase0.96.2.hive0.13.1都是什么? 二.这些软件在哪里下载? 三.如何安装 1.安装JDK 2.用parallel ...
- Kafka介绍及安装部署
本节内容: 消息中间件 消息中间件特点 消息中间件的传递模型 Kafka介绍 安装部署Kafka集群 安装Yahoo kafka manager kafka-manager添加kafka cluste ...
- hue框架介绍和安装部署
大家好,我是来自内蒙古的小哥,我现在在北京学习大数据,我想把学到的东西分享给大家,想和大家一起学习 hue框架介绍和安装部署 hue全称:HUE=Hadoop User Experience 他是cl ...
- Storm介绍及安装部署
本节内容: Apache Storm是什么 Apache Storm核心概念 Storm原理架构 Storm集群安装部署 启动storm ui.Nimbus和Supervisor 一.Apache S ...
- Apache Solr 初级教程(介绍、安装部署、Java接口、中文分词)
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- 大数据技术之_13_Azkaban学习_Azkaban(阿兹卡班)介绍 + Azkaban 安装部署 + Azkaban 实战
一 概述1.1 为什么需要工作流调度系统1.2 常见工作流调度系统1.3 各种调度工具特性对比1.4 Azkaban 与 Oozie 对比二 Azkaban(阿兹卡班) 介绍三 Azkaban 安装部 ...
- 【Hadoop离线基础总结】Hue的简单介绍和安装部署
目录 Hue的简单介绍 概述 核心功能 安装部署 下载Hue的压缩包并上传到linux解压 编译安装启动 启动Hue进程 hue与其他框架的集成 Hue与Hadoop集成 Hue与Hive集成 Hue ...
- Hadoop入门进阶课程13--Chukwa介绍与安装部署
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Spark介绍及安装部署
一.Spark介绍 1.1 Apache Spark Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架(没有数据存储).最初在2009年由加州大学伯克利分校的AMPLab开 ...
随机推荐
- 是什么优化让 .NET Core 性能飙升?(转)
欢迎大家持续关注葡萄城控件技术团队博客,更多更好的原创文章尽在这里~~ .NET Core(开放源代码,跨平台,x-copy可部署等)有许多令人兴奋的方面,其中最值得称赞的就是其性能了. 感谢所有社区 ...
- Linux的磁盘分区(三)
RAID 廉价冗余磁盘阵列 Redundant Arrays of Inexpensive Disks 不同级别的RAID功能.特性各不相同 对比项 RAID0 RAID1 RAID10 RAID5 ...
- .NET Core2使用Azure云上的Iot-Hub服务
基于工业4.0大背景下的工业物联网是近几年内热门的话题,依靠信息化技术企业可以实现数字化转型,生产可以实现智能化制造,设备可以实现自动化运作.然而,海量的数据采集是整个建设过程的基础环节,如何处理与利 ...
- solr分词一:mmseg4j
刚接触Lucene2.x和Solr2.x的时候,谈到中文分词,会让我立即想到用庖丁中文分词,庖丁中文分词因巨大的中文词库以及支持不限制个数的用户自定义词库,而且是纯文本格式,一行一词,使用后台线程检测 ...
- 构建命令maven install 打包不是最新的代码
问题: 之前一直用的是mvn install 命令来构建项目,但是最近发现最新的代码没有在war包中.之前看的说 mvn install 命令会执行之前的所有阶段,会被编译,测试,打包. 经查最后采用 ...
- docker查看挂载目录命令
docker inspect -f "{{.Mounts}}" 692691b7416 692691b7416为containerId
- C#中实现对象的深拷贝
深度拷贝指的是将一个引用类型(包含该类型里的引用类型)拷贝一份(在内存中完完全全是两个对象,没有任何引用关系).......... 直接上代码: /// <summary> /// 对象的 ...
- 2-初步了解C#-类与对象
本篇博客对应视频讲解 回顾 我们在第一篇文章中讲了编程中最基本的内容,如输入输出.字符串处理.数字类型计算.分支及循环结构等.无论学习什么语言,这些内容都是相通的. 本篇博客主要演示列表(List)的 ...
- 调用阿里云API 的demo示例(java/python)
Java 示例 // 创建DefaultAcsClient实例并初始化 DefaultProfile profile = DefaultProfile.getProfile(vo.getAliRegi ...
- 手动开发PHP模板引擎 一 (35)
模板叫做TPL,模仿于smarty模板引擎. 我们所说的模板是Web模板,是主要由HTML标记组成的语言来编写的页面,但也有如何表示包含动态生成内容的方式(解析标签).模板引擎是一种软件库,允许我们从 ...