【大数据实战】Logstash采集->Kafka->ElasticSearch检索
1. Logstash概述
Logstash的官网地址为:https://www.elastic.co/cn/products/logstash,以下是官方对Logstash的描述。

Logstash是与Flume类似,也是一种数据采集工具,区别在于组件和特性两大方面。常用的数据采集工具有Sqoop、Flume、Logstash,计划将单独写一篇博文论述它们之间的区别,所以这里就不赘述,感兴趣可关注后期的博文。
2. Kafka概述
Kafka的官网是:http://kafka.apache.org/,官方的介绍如下图:

总结来说,Kafka是一个分布式消息队列,具有生产者和消费者的功能,它依赖Zookeeper集群来保存meta数据,根据Topic来归类存储的消息,Kafka集群由多个实例组成,每个实例称为broker。
3. ElasticSearch概述
ElasticSearch是一个分布式的搜索和数据分析引擎。它的官网是:https://www.elastic.co/cn/products/elasticsearch,官方对ElasticSearch的描述如下,通过官方的描述能够对ElasticSearch有一个整体的了解。

3. 编程实战
3.1 小项目介绍
在VM的linux本地logserver目录下存有模拟数据data.log,启动一个logstash监视Linux的logserver目录的data.log日志文件,当日志文件发生了修改,将日志文件采集到Kafka消息队列的名为logs的Topic中,另启动一个logstash将Kafka的消息采集到ElashticSearch,使用ElasticSearch检索数据。
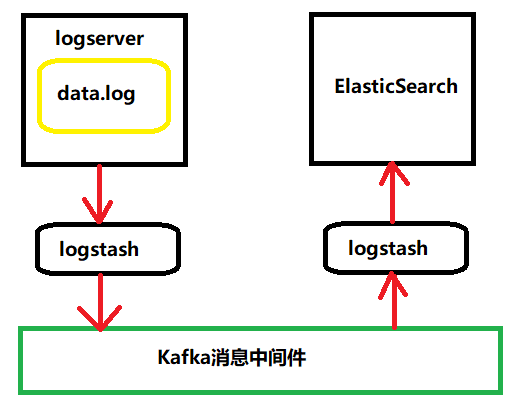
3.2 开发环境
系统环境: VM中存在三台Linux机器(bigdata12,bigdata14,bigdata15)
软件环境:kafka_2.11-0.9.0.1、zookeeper-3.4.10、elasticsearch-2.4.4、logstash-2.3.1
3.3 环境准备
1. 首先在三台机器开启zookeeper,各机器运行zkServer.sh start,Linux下查看是否有然后使用zkServer.sh status查看zookeeper的状态,如果看到leader和follower角色的出现就代表运行正常。
2. 三台启动Kafka,到kafka目录下,运行 nohup bin/kafka-server-start.sh conf/serverproperties.conf。使用
3. 使用非root用户启动elasticsearch,使用非root用户进入elasticsearch目录执行: bin/elasticsearch -d
【注意】,必须是非root用户,否则会报错。如果没有,就创建一个用户。
例如创建一个用户为zhou的话,执行:
(1) 添加用户:useradd bigdata,
(2) 为用户添加密码 :echo 123456 | passwd --stdin zhou,
(3) 将zhou添加到sudoers: echo "bigdata ALL = (root) NOPASSWD:ALL" | tee /etc/sudoers.d/zhou
(4) 修改权限: chmod 0440 /etc/sudoers.d/zhou
(5) 从root切换成zhou: su - zhou
(6) 然后再执行启动elasticsearch命令
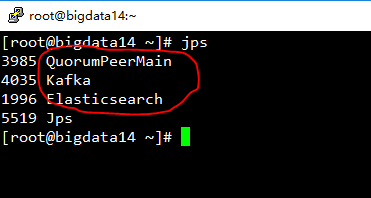
4. 检查进程运行情况
在Linux环境下执行jps命令查看进程是否正常启动,每台机器查看是否有以下进程
在elasticsearch安装了head的前提下,在windows环境开启浏览器,在地址栏输入http://ip地址:9200/_plugin/head ,例如,根据我的配置,输入了http://192.168.243.11:9200/_plugin/head。出现以下界面,表示Elasticsearch启动正常

在以上环节确认后,就代表环境启动运行正常,可以进行正常开发程序。
3.4 开发
3.4.1 编写logstash配置
在bigdata12机器中进入logstash的conf目录:
vi dataTokafka.conf
input {
file {
codec => plain {
charset => "UTF-8"
}
path => "/root/logserver/supernova.log"
discover_interval => 5
start_position => "beginning"
}
}
output {
kafka {
topic_id => "supernova"
codec => plain {
format => "%{message}"
charset => "UTF-8"
}
bootstrap_servers => "bigdata12:9092,bigdata14:9092,bigdata15:9092"
}
}
在bigdata14机器中进入logstash的conf目录:
vi dataToElastic.conf
input {
kafka {
type => "supernova"
auto_offset_reset => "smallest"
codec => "plain"
group_id => "elas2"
topic_id => "supernova"
zk_connect => "bigdata12:2181,bigdata14:2181,bigdata15:2181"
}
}
filter {
if [type] == "supernova" {
mutate {
split => { "message" => "|" }
add_field => {
"id" => "%{message[0]}"
"time" => "%{message[1]}"
"ip" => "%{message[2]}"
"user" => "%{message[3]}"
}
remove_field => [ "message" ]
}
}
}
output {
if [type] == "supernova" {
elasticsearch {
index => "supernova"
codec => plain {
charset => "UTF-16BE"
}
hosts => ["bigdata12:9200", "bigdata14:9200", "bigdata15:9200"]
}
}
}
3.4.2 运行
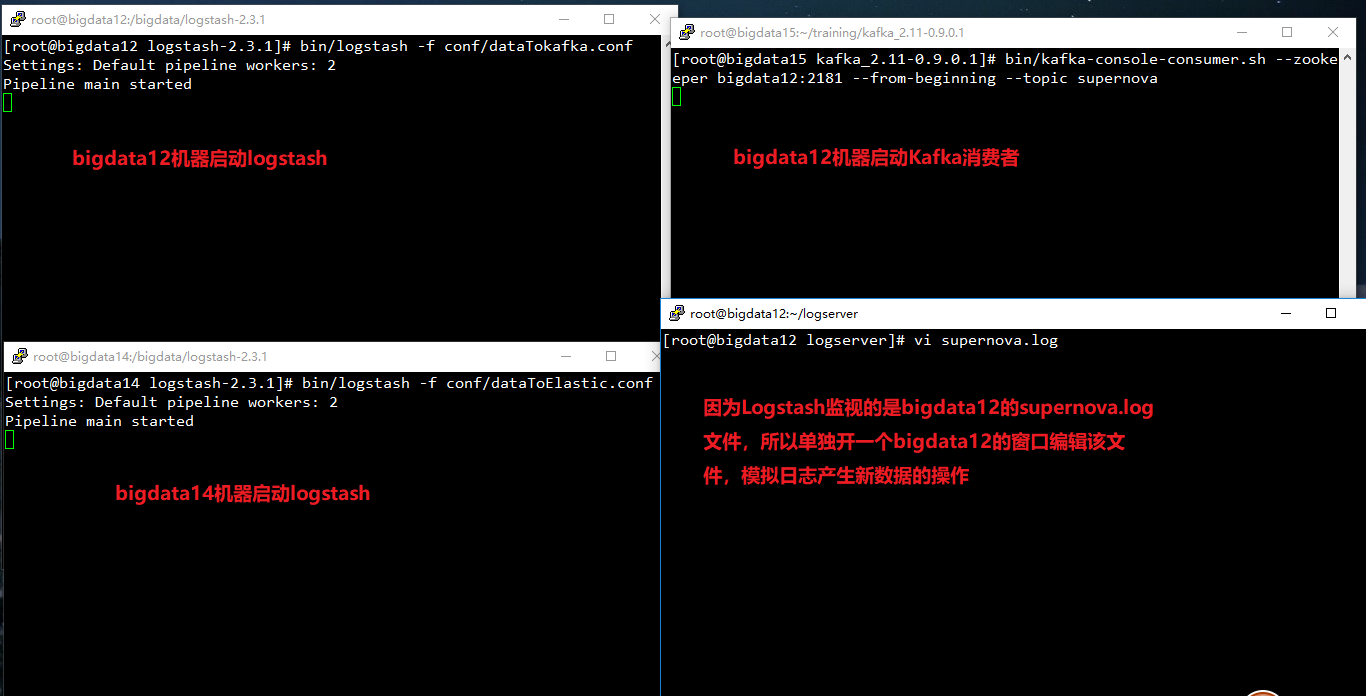
(1) 在bigdata12机器中,使用3.4.1中的dataTokakfa.conf启动logstash。执行:bin/logstash -f conf/dataTokakfa.conf,监听supernova.log文件
(2) 在bigdata14机器中,使用3.4.1中的dataToElastic.conf启动logstach。执行:bin/logstash -f conf/dataToElastic.conf,将Kafka数据采集到Elasticsearch。
(3) 为了便于观察,在bigdata15机器中,启动kafka消费者,查看Topic中的数据。执行:bin/kafka-console-consumer.sh --zookeeper bigdata11:2181 --from-beginning --topic logs,用于消费Kafka中Topic名为logs的消息。
(4) 编辑修改Logstash监听的supernova.log文件。
启动】:
【修改】在bigdata15中修改了数据(右下角窗口)
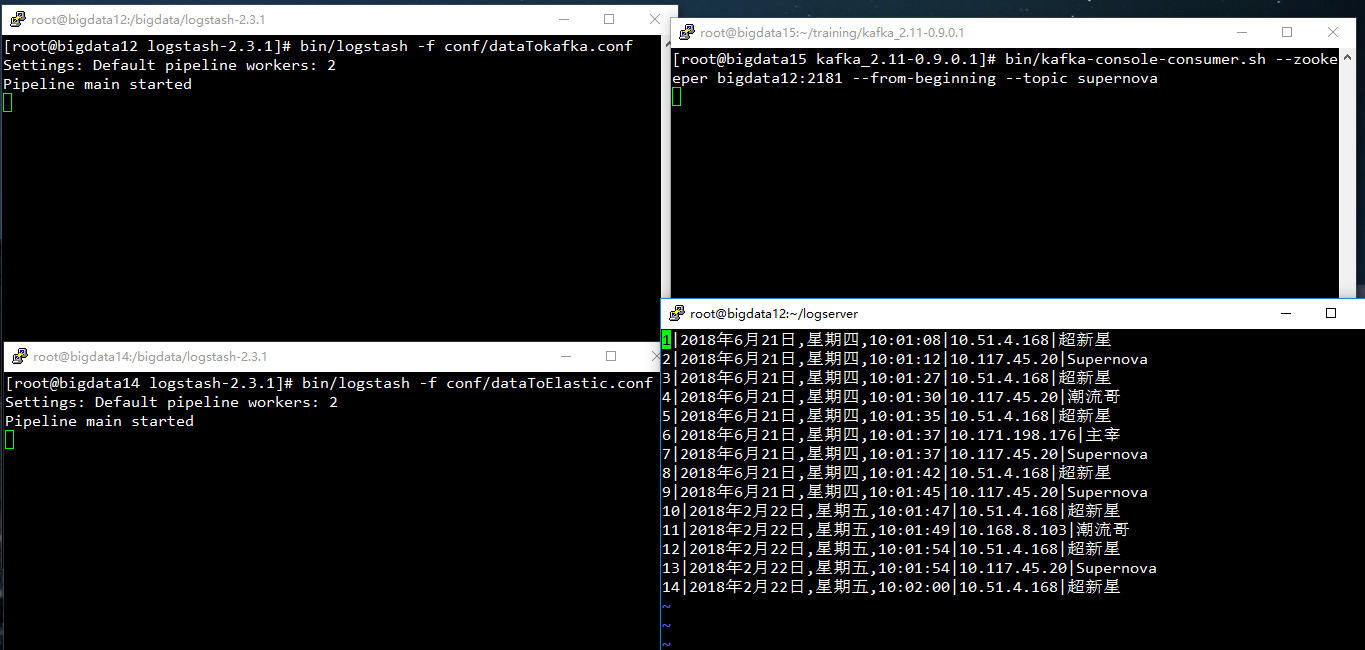
【监视过程】:bigdata15中(右上),kafka的consumer消费到了supernova.log文件中的数据,在bigdata14中,可以看到将数据传至ElasticSearch的数据(左下)

【ElasticSeach结果】
可以看到Elastic集群中,产生了一个supernova的type(类似关系数据库中的table)
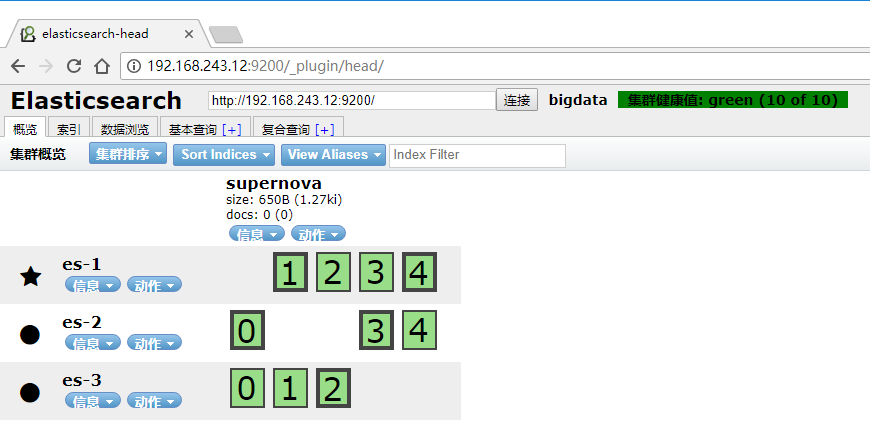
【查看ElasticSearch数据】

3.4.2 ElasticSearch检索
使用Junit单元测试的方法来编写测试方法,代码如下:
EalsticSearch.java
package novaself; import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.junit.Before;
import org.junit.Test; import java.net.InetAddress;
import java.util.Iterator; /**
* @author Supernova
* @date 2018/06/22
*/
public class ElasticSearch { private Client client; /**
* 获取客户端
*/
@Before
public void getClient() throws Exception {
// ElasticSearch服务默认端口9300
Settings settings = Settings.settingsBuilder()
.put("cluster.name", "bigdata").build();
client = TransportClient.builder().settings(settings).build()
.addTransportAddress(new InetSocketTransportAddress(
InetAddress.getByName("bigdata12"), 9300))
.addTransportAddress(new InetSocketTransportAddress(
InetAddress.getByName("bigdata14"), 9300))
.addTransportAddress(new InetSocketTransportAddress(
InetAddress.getByName("bigdata15"), 9300));
} /**
* 词条查询: 用户名中有"新"字的数据
*/
@Test
public void testTermQuery(){
/*
* termQuery词条查询: 只匹配指定字段中含有该词条的文档
* 查询user字段为超新星的记录
*/
SearchResponse response = client.prepareSearch("supernova")
.setTypes("supernova")
.setQuery(QueryBuilders.termQuery("user","新"))
.get(); // 获取结果集对象、命中数
SearchHits hits = response.getHits();
// 使用迭代器遍历数据
Iterator<SearchHit> iter = hits.iterator();
while(iter.hasNext()){
SearchHit hit = iter.next();
// 以Json格式输出
String result = hit.getSourceAsString();
System.out.println(result);
} //关闭客户端
client.close();
}
/**
* 模糊查询: 星期四的数据
*/
@Test
public void testWildcardQuery() throws Exception{
/*
* wildcardQuery模糊查询,time字段中包含"四"的数据
*/
SearchResponse response = client.prepareSearch("supernova")
.setTypes("supernova")
.setQuery(QueryBuilders.wildcardQuery("time","四"))
.get(); // 获取结果集对象、命中数
SearchHits hits = response.getHits();
// 使用迭代器遍历数据
Iterator<SearchHit> iter = hits.iterator();
while(iter.hasNext()){
SearchHit hit = iter.next();
// 以Json格式输出
String result = hit.getSourceAsString();
System.out.println(result);
} //关闭客户端
client.close();
}
}
【检索结果】:
词条查询:testTermQuery( )方法的运行结果:

模糊查询:testWildcardQuery ( )方法的运行结果:

【大数据实战】Logstash采集->Kafka->ElasticSearch检索的更多相关文章
- 《OD大数据实战》驴妈妈旅游网大型离线数据电商分析平台
一.环境搭建 1. <OD大数据实战>Hadoop伪分布式环境搭建 2. <OD大数据实战>Hive环境搭建 3. <OD大数据实战>Sqoop入门实例 4. &l ...
- 《OD大数据实战》HDFS入门实例
一.环境搭建 1. 下载安装配置 <OD大数据实战>Hadoop伪分布式环境搭建 2. Hadoop配置信息 1)${HADOOP_HOME}/libexec:存储hadoop的默认环境 ...
- 《OD大数据实战》Hive环境搭建
一.搭建hadoop环境 <OD大数据实战>hadoop伪分布式环境搭建 二.Hive环境搭建 1. 准备安装文件 下载地址: http://archive.cloudera.com/cd ...
- 大数据应用日志采集之Scribe演示实例完全解析
大数据应用日志采集之Scribe演示实例完全解析 引子: Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它能够从各种日志源上收集日志,存储到一个中央存储系 ...
- 大数据应用日志采集之Scribe 安装配置指南
大数据应用日志采集之Scribe 安装配置指南 大数据应用日志采集之Scribe 安装配置指南 1.概述 Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它 ...
- SparkSQL大数据实战:揭开Join的神秘面纱
本文来自 网易云社区 . Join操作是数据库和大数据计算中的高级特性,大多数场景都需要进行复杂的Join操作,本文从原理层面介绍了SparkSQL支持的常见Join算法及其适用场景. Join背景介 ...
- 大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
http://www.aboutyun.com/thread-6855-1-1.html 个人观点:大数据我们都知道hadoop,但并不都是hadoop.我们该如何构建大数据库项目.对于离线处理,ha ...
- 大数据抓取采集框架(摘抄至http://blog.jobbole.com/46673/)
摘抄至http://blog.jobbole.com/46673/ 随着BIG DATA大数据概念逐渐升温,如何搭建一个能够采集海量数据的架构体系摆在大家眼前.如何能够做到所见即所得的无阻拦式采集.如 ...
- 大数据系列之Flume+kafka 整合
相关文章: 大数据系列之Kafka安装 大数据系列之Flume--几种不同的Sources 大数据系列之Flume+HDFS 关于Flume 的 一些核心概念: 组件名称 功能介绍 Agent ...
随机推荐
- 查询SQL Version详细信息
下面是一个查询SQL Server版本并给出升级建议的SQL代码,用来学习写SQL代码. ------------------------------------------------------- ...
- 图书管理系统 基于form组件
models: from django.db import models # Create your models here. class Book(models.Model): name = mod ...
- Mybatis学习---基础知识考核
MyBatis 2.什么是MyBatis的接口绑定,有什么好处 接口映射就是在IBatis中任意定义接口,然后把接口里面的方法和SQL语句绑定, 我们直接调用接口方法就可以,这样比起原来了Sql ...
- C# 冒泡排序法、插入排序法、选择排序法
冒泡排序法 是数组等线性排列的数字从大到小或从小到大排序. 以从小到大排序为例. 数据 11, 35, 39, 30, 7, 36, 22, 13, 1, 38, 26, 18, 12, 5, 45, ...
- 深入浅出SharePoint——常用的url命令
?&displaymode=design 页面可编辑
- August 27th 2017 Week 35th Sunday
You can't be brave if you've only had wonderful things happen to you. 人生若只是有美好的境遇,那你也没办法学会勇敢. Wherea ...
- December 22nd 2016 Week 52nd Thursday
The best hearts are always the bravest. 心灵最高尚的人,往往也是最勇敢的人. Keep conscience clear, don't let too many ...
- 一个简单的php分页逻辑
php分页 <?php include 'backend/conn.php'; $html = '<ul>'; //输出的html $pageDataNum=3; //每页显示10行 ...
- windows2003 iis6配置文件和win2008/2012 iis7.5配置文件
转载某大牛.... 日国外站的单子 :反正跑着玩 简单看下 先 在线web扫描 https://www.yascanner.com/之后发现存在注入漏洞 asp的站 穿山甲可以注入,但是发现是m ...
- 使用python 操作liunx的svn,方案一
在服务器中要做几个操作,使用命令操作svn,svn文件的创建,svn文件更新,并把指定demo路径,移动到创建的文件夹中,进行提交, # -*- coding:utf-8 -*- import pys ...