python--requests_html
这个模块从名字上也能看出来,是专门用来解析html的,这个和requests的作者是同一人,非常牛逼的一位大佬。
大致读了一下源码,总共一个py文件(但是引用了其他的模块),加上注释总共才700多行,大部分是基于已有的模块进行了一个二次封装,可以更加方便开发者去调用。
可以的话也推荐阅读一下源码,这样的代码最适合阅读,没有大型框架的代码量,但同时又包含了很多的知识点。因此可以将整个模块全部阅读,进而了解作者的构思,以及整个模块的原理
一般来说,获取页面和解析是分开的,但是requests_html这个模块可以完成这两部分的功能,毕竟里面导入了requests模块
废话不多说,直接上代码
# 首先看一下requests_html下的HTMLSession这个类
from requests_html import HTMLSession
# 这个HTMLSession继承自requests模块下的Session类
session = HTMLSession()
# 毫无疑问,response.text会获取到相应的html页面,既然HTMLSession继承自requests下的Session,那么Session能实现的,HTMLSession都能实现
response = session.get("http://www.bilibili.com")
response.encoding = response.apparent_encoding
# 然而这个response可跟requests库下的Session.get(url)得到的response不一样
# 这个response要强大的多,准确的说应该是response.html,因为response.html下面有很多的属性,先来看看它的功能是什么?
# 1.可以通过response.html.links获取html里面的路径(url),注意得到的是一个集合
for link in response.html.links:
print(link)
'''
只截取一部分
//www.bilibili.com/v/kichiku/guide/
//www.bilibili.com/v/dance/demo/
//www.bilibili.com/v/guochuang/puppetry/
//www.bilibili.com/v/anime/finish/
//www.bilibili.com/v/life/
//live.bilibili.com/e-sports
//www.bilibili.com/v/music/cover/
'''
# 2.获取绝对路径
for link in response.html.absolute_links:
print(link)
'''
只截取一部分
https://www.bilibili.com/v/fashion/makeup/
https://www.bilibili.com/v/dance/
https://www.bilibili.com/v/kichiku/mad/
https://www.bilibili.com/v/technology/speech_course/
https://www.bilibili.com/v/music/oped/
https://www.bilibili.com/v/ent/korea/
'''
# 3.实现CSS选择器
'''
response.html.find("#mmp", first=True)
查找id="mmp"的标签,如果加上first=True,那么会得到第一个标签。不加会得到所有的标签,这些标签会组合成一个列表返回
response.html.find(".mmp", first=True)
显然这个查找class="mmp"的标签
response.html.find("a", first=True)
找到a标签
当然还可以找p标签,div标签,span标签等等
'''
# 获取到的cls便是相应的标签
cls = response.html.find(".play", first=True)
print(cls) # <Element 'p' class=('play',)>
# 这个cls下有很多方法
# 获取文本
print(cls.text) # 播放:10.6万
# 获取属性
print(cls.attrs) # {'class': ('play',)}
print(cls.attrs.get("class", None)) # ('play',)
# 获取所在的html
print(cls.html) # <p class="play">播放:10.6万</p>
a = response.html.find("a", first=True)
print(a) # <Element 'a' href='//www.bilibili.com' title='主站' class=('t',)>
print(a.text) # 主站
print(a.attrs) # {'href': '//www.bilibili.com', 'title': '主站', 'class': ('t',)}
print(a.attrs.get("href", None)) # //www.bilibili.com
'''
a.attrs.get("href", None)所获取的href感觉怪怪的,少了http:
不过不要紧,
import webbrowser
webbrowser.open(a.attrs.get("href", None))
因为我们使用webbrowser是可以打开的
'''
print(a.html) # <a href="//www.bilibili.com" title="主站" class="t"><i class="bili-icon"/>主站</a>
# 我们知道response.html.links|absolute_links可以获取url,那么通过response.html.find获取到的标签依旧可以获取url
print(a.links) # {'//www.bilibili.com'},得到的仍是个集合,哪怕集合里面只有一个元素
# 4.搜索文本。
''' 注意:response.html.text是搜索文本。比如<p>mmp</p>,那么得到的就是mmp。 而response.text,和requests.get(url).text或者request.Session().get(url).text一样,获取得到是整个HTML页面(这里就是<p>mmp>/p>) ''' text = response.html.text print(text) ''' 截取一部分,可以看到获取的是文本,也就是标签里的内容 主站 画友 音频 游戏中心 直播 会员购 BML 下载APP 投 稿 排行榜 首页 -- 动画 MAD·AMV MMD·3D 短片·手书·配音 综合 -- 番剧 连载动画 完结动画 '''
# 5.搜索网页上的文本。不好说明,直接看例子吧
# 我们看到在获取文本的例子中,截取的结果的最后一个是"完结动画"
search_text = response.html.search("完{}画")[0]
print(search_text) # 结动
search_text = response.html.search("完结{}")[0]
print(search_text) # 动
# 如果不加[0],获取到的是一个<class 'parse.Result'>
print(response.html.search("完{}画"), ":::", type(response.html.search("完{}画"))) # <Result ('结动',) {}> ::: <class 'parse.Result'>
'''
可以看到还是很强大的,是用来在获取的全局的文本中搜索指定的文本
"完{}画",表示搜索开头是"完",结尾是"画"的中间的字段
但是当我指定"完结{}",并不会获取"动画"二字,而是只获取一个"动"字,对于英文也是一样,只会获取一个字符
如果获取不到满足条件的字符的话,比如response.html.search("完{}画cadadasdsa"),那么会返回None
而且这里有一个值得注意的点,那就是我获取"完结{}动画", "{}完结动画", "完结动画{}"会怎么样?
首先这里"完结动画"四个字已经全了,按理说{}已经获取不到内容了,但是
print(response.html.search("完结动画{}")[0]) # <,会得到这么一个东西,表示后面已经没有内容了
print(response.html.search("{}完结动画")[0]) # 会获取整个页面的html(含标签),
print(response.html.search("完结{}动画")[0]) # 动画</span></a></li><li>······uang/chinese/"><span>国产
如果补全的话应该是"(...完结)动画</span></a></li><li>······uang/chinese/"><span>国产(动画...)",
所以这种情况下会获取到上一个"完结"和下一个"动画"之间的html(含标签)
'''
# 6.之前说的选择器,也支持更复杂的选择
但是就不介绍了,因为什么?因为必须要从body标签一层一层的找
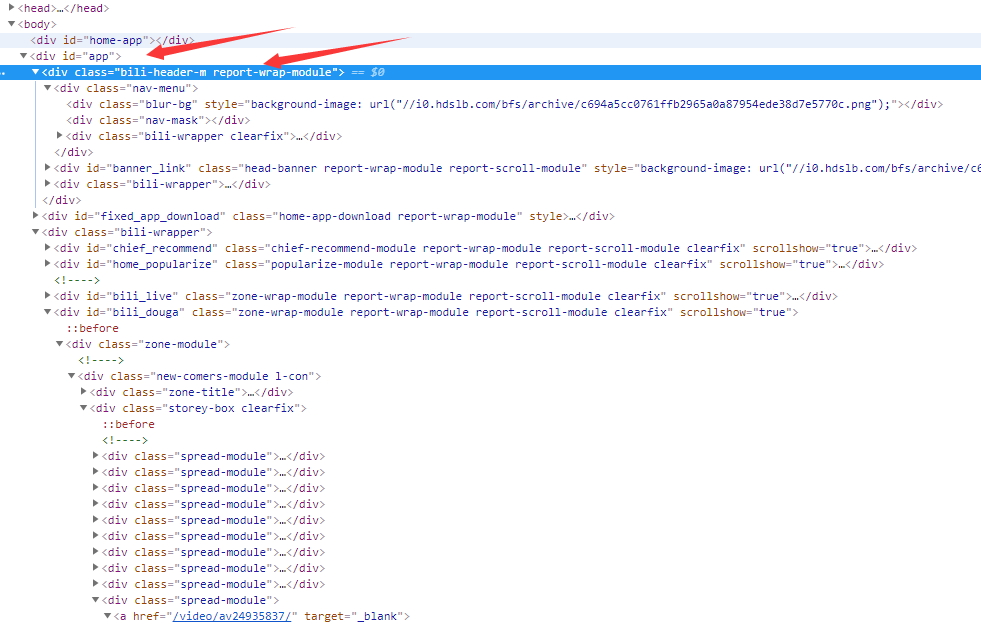
首先body下面有一个id="app"的div标签,下一级是class="bili-header-m report-wrap-module"(注意这里是两个,分别是bili-header-m和report-wrap-module)的div标签。
如果要找的话,可以这样,response.html.find('body > div#app > div.bili-header-m.report-wrap-module'),但是如果我使用response.html.find('body > div.bili-header-m.report-wrap-module')就找不到了,
因为跳过了id="app"的那个div标签,因此这种方法必须从body开始一层一层的往下查找。这样的话会很不方便,如果找中间的某个标签,还要从头开始找,会很恐怖,因此就不推荐了。
# 7.xpath
xpath是一个非常强大的方法,一般我用到xpath,都是从scrapy里面导入的
from scrapy.selector from Selector
Selector(text=xxx).xpath(....),不过requests_html也支持xpath,用法和其他模块里的xpath是类似的,注意这里的结尾不需要extract
# 我们换个网站
from requests_html import HTMLSession
session = HTMLSession()
response = session.get("http://http://www.mzitu.com/xinggan/")
response.encoding = response.apparent_encoding
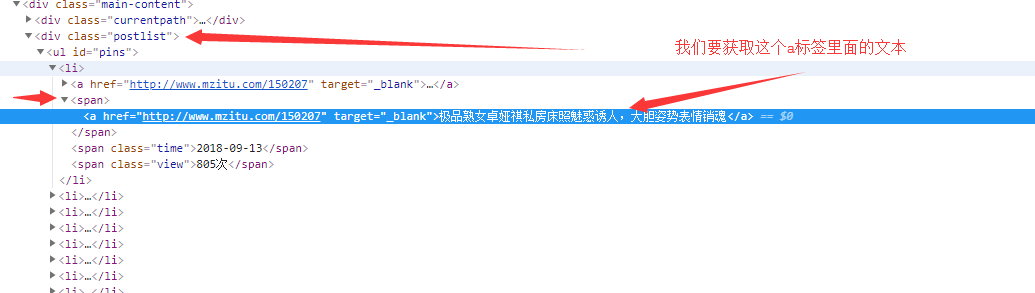
# 7. xpath
a_text = response.html.xpath('//div[@class="postlist"]//span//a/text()', first=True)
print(a_text) # 极品熟女卓娅祺私房床照魅惑诱人,大胆姿势表情销魂
# 也可以这样
a_text = response.html.xpath('//div[@class="postlist"]//span//a', first=True).text
print(a_text) # 极品熟女卓娅祺私房床照魅惑诱人,大胆姿势表情销魂
# 注意:如果我们没有first=True,那么会找到所有满足条件的文本
8.也可以获取包含指定内容的文本
# 按理说我们指定了内容,我们只会获取一个标签,但即便如此如果不加first=True,得到的仍是个列表,即便只有一个元素,所以要加上first=True
cont = response.html.find('a', containing="魅惑诱人,大胆姿势", first=True)
print(cont) # <Element 'a' href='http://www.mzitu.com/150207' target='_blank'>
print(cont.attrs) # {'href': 'http://www.mzitu.com/150207', 'target': '_blank'}
print(cont.text) # 极品熟女卓娅祺私房床照魅惑诱人,大胆姿势表情销魂
'''
我要获取a标签,什么样的a标签呢?文本包含"魅惑诱人,大胆姿势"的a标签
'''
以上就是requests_html的基础用法,可以看到功能还是非常强大的。所有的功能都在response.html下面,response倒没什么乱用。既然在源码中引入了requests模块,而且HTMLSession继承自requests的Session,就说明可以实现下载页面的功能。而且文本的解析也会比BeautifulSoup强大许多,BeafutifulSoup是纯python实现的,速度上自然不会很高。所以以后写一些爬虫完全可以使用一个requests_html足矣,而且源码中还引入了asyncio模块,说明耗费时间部分是异步执行的。
下面介绍进阶用法,不过介绍之前,先来用所学的知识,进行一个简单的爬取图片。

就爬取这些妹子图吧,这些图片分别在一个a标签里面,点击就会跳转。
可以看到这个有40页,我们要把她们都爬取下来

可以看到text就是我们的标题,href就是我们要跳转的url,我们先把这俩获取下来
from requests_html import HTMLSession
session = HTMLSession()
response = session.get("http://www.mzitu.com/xinggan/")
response.encoding = response.apparent_encoding
# url_title,存储所有要跳转的url以及对应标题
url_title = {}
for element in response.html.xpath('//div[@class="postlist"]//ul[@id="pins"]//span/a'):
url = element.attrs["href"]
title = element.text
url_title[title] = url
# 打印一下看看
for k, v in url_title.items():
print(k, v)
'''
极品熟女卓娅祺私房床照魅惑诱人,大胆姿势表情销魂 http://www.mzitu.com/150207
恰到好处的性感 女神王雨纯妩媚气息勾人魂魄 http://www.mzitu.com/149915
大胸少妇瑞瑞ruirui圆润精致 欲求不满等解救 http://www.mzitu.com/149680
想和黑丝女秘书玩SM捆绑?Egg尤妮丝满足你的幻想 http://www.mzitu.com/150384
孙梦瑶性感迷人的美臀,我猜你会有一个大胆的想法 http://www.mzitu.com/150166
性感徐微微mia全裸浴照释出 诱人胴体美妙绝伦 http://www.mzitu.com/149638
熟女控福利 性感乳神宋KiKi演绎春心荡漾的寂寞人妻 http://www.mzitu.com/150114
性感美女小热巴逆天长腿韵味无穷 http://www.mzitu.com/150067
想入非非!美女私教考拉koala曲线完美无可挑剔 http://www.mzitu.com/149869
微胖小姐姐白晓白 轻熟的气质让你欲罢不能 http://www.mzitu.com/150001
女神宋-KiKi清凉写真性感爆棚 实力演绎人妻的诱惑 http://www.mzitu.com/149829
香车美女小树林,黄楽然致命诱惑不可描述 http://www.mzitu.com/149728
女神周妍希:诱人的身姿,每一个动作都在挑逗你 http://www.mzitu.com/149956
微胖女神龍籹cool丰满身材带来极致的视觉震撼 http://www.mzitu.com/149284
纸巾自备!性感美女卓娅祺丝袜蕾丝致命诱惑 http://www.mzitu.com/149482
丰满女神尤妮丝魔鬼身材无以伦比 巨乳翘臀包你血脉喷张 http://www.mzitu.com/149589
风骚美女王紫琳全身涂满奶油等你来舔 http://www.mzitu.com/149381
人间胸器心妍小公主奇尺大乳撑爆屏幕 http://www.mzitu.com/149209
性感女神小热巴直播洗澡,娇躯玲珑起伏白嫩撩人 http://www.mzitu.com/149528
模特Cccil身材高挑婀娜多姿 五官美艳满满的贵妇气质 http://www.mzitu.com/149163
酒店,王雨纯,销魂一夜 http://www.mzitu.com/149435
韵味旗袍与丝袜高跟性感碰撞 Miko酱的美腿魅力无法形容 http://www.mzitu.com/149051
极品熟妇陆梓琪情趣内衣性感惹火 一脸欲望冷艳迷人 http://www.mzitu.com/148717
她的性感深入骨髓,东方的韵味令神魂颠倒 http://www.mzitu.com/149329
'''
接下来获取每一个url对应的所有图片

注意这些页码,便是图片的连接,但是我们注意到中间省略了,获取的话从4就直接跳到40了,然后是2表示下一页。这涉及到js的问题,我们下面再说,目前的话我们可以通过索引的方式获取到最大页码,然后再手动组合
以下是代码,是同步的,没有进行异步执行
from requests_html import HTMLSession
import os
# 获取标题以及对应的url
def get_url_title():
response = session.get("http://www.mzitu.com/xinggan/")
response.encoding = response.apparent_encoding
# url_title,存储所有要跳转的url以及对应标题
url_title = {}
for element in response.html.xpath('//div[@class="postlist"]//ul[@id="pins"]//span/a'):
url = element.attrs["href"]
title = element.text
url_title[title] = url
return url_title
def get_pic_link(title, url):
# 首先我在桌面上已经创建了一个名为"妹子图"的文件夹
path = rf"C:\Users\satori\Desktop\妹子图\{title}"
os.mkdir(path)
response = session.get(url)
uncompleted_pic_url_list = response.html.xpath('//div[@class="pagenavi"]//a/@href')
max_page_num = int(uncompleted_pic_url_list[-2].rsplit("/")[-1])
completed_pic_url_list = [url+"/"+str(i) for i in range(1, max_page_num+1)]
for num, pic_url in enumerate(completed_pic_url_list[: -1], 1):
response = session.get(pic_url)
_pic_url = pic_url.rsplit("/", maxsplit=1)[0] + "/" + str(int(pic_url.rsplit("/", maxsplit=1)[1])+1)
img = response.html.xpath(f'//a[@href="{_pic_url}"]/img/@src', first=True)
res = session.get(img, headers={"Referer": pic_url})
with open(os.path.join(path, f"{num}.jpg"), "wb") as f:
f.write(res.content)
if __name__ == '__main__':
session = HTMLSession()
url_title = get_url_title()
for title, url in list(url_title.items()):
get_pic_link(title, url)
print(f"{title}--完成")

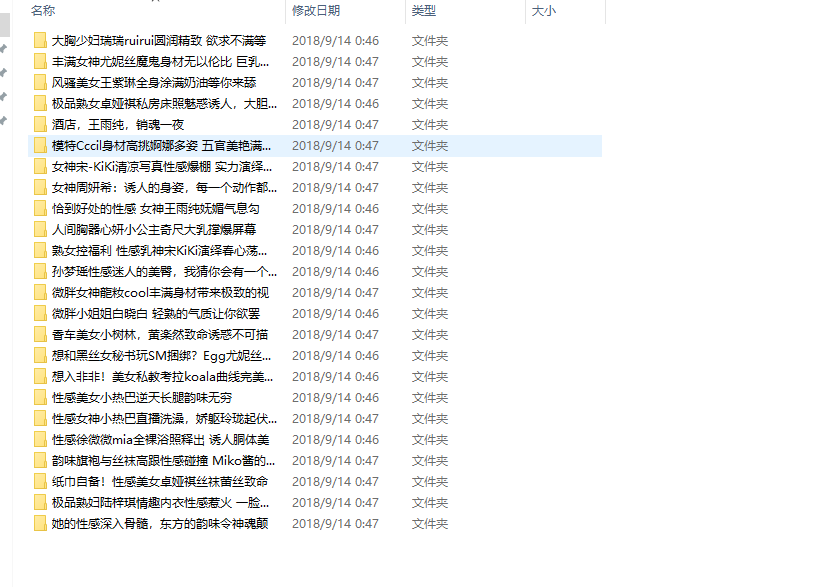
可以看到我们的图片都下载下来了
下面介绍requests_html的进阶教程
1.JavaScript
有些网站是使用JavaScript渲染的,我们直接爬取的话,只会得到一堆的js代码,这不是我们想要的。如何处理这种情况呢,requests_html也会我们提供了方法。
在我们获取的html上调用一下render方法。也就是response.html.render(),这样的话,就会下载一个chromium到用户目录,然后使用它来执行js代码,而且这个过程只会执行一次,下次就可以直接使用了。
from requests_html import HTMLSession
session = HTMLSession()
r = session.get("http://www.bilibili.com")
r.html.render()

此外这个render方法还是可以带参数的
retries:下载页面失败的次数
script:页面上需要执行的js脚本
wait:加载页面前的等待时间(秒),防止超时(可选)
scrolldown:页面向下滚动的次数
sleep:页面初次渲染之后的等待时间
reload:如果为False,那么页面不会从浏览器中加载,而是从内存中加载
keep_page:如果为真, 那么允许使用response.html.page访问页面
比如说微博上的信息,都是异步加载的,就是一开始只显示一部分,你鼠标向下滚动,然后继续显示。
这种时候就可以使用scrolldown和sleep模拟下滑页面,促使js代码加载所有文章
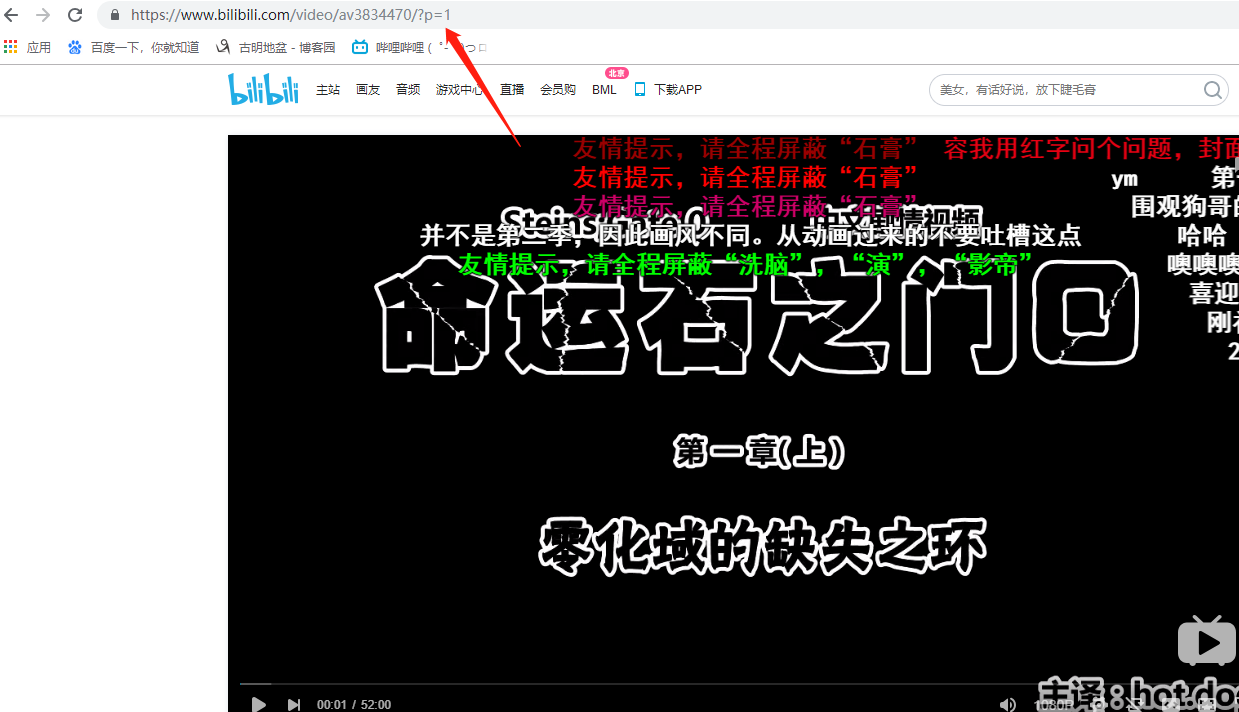
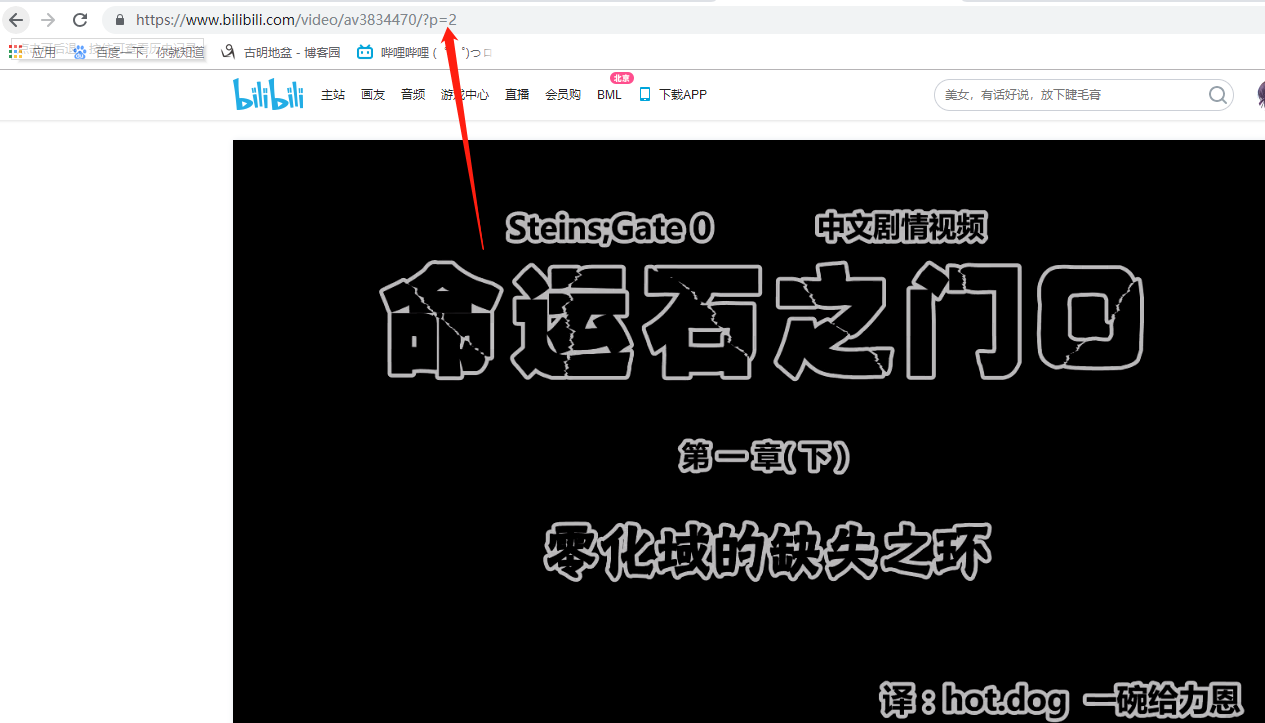
2.智能分页
比方说哔哩哔哩,有的时候会分很多P
python--requests_html的更多相关文章
- Python爬虫中文小说网点查找小说并且保存到txt(含中文乱码处理方法)
从某些网站看小说的时候经常出现垃圾广告,一气之下写个爬虫,把小说链接抓取下来保存到txt,用requests_html全部搞定,代码简单,容易上手. 中间遇到最大的问题就是编码问题,第一抓取下来的小说 ...
- python高级编程读书笔记(一)
python高级编程读书笔记(一) python 高级编程读书笔记,记录一下基础和高级用法 python2和python3兼容处理 使用sys模块使程序python2和python3兼容 import ...
- python接口自动化28-requests-html爬虫框架
前言 requests库的好,只有用过的人才知道,最近这个库的作者又出了一个好用的爬虫框架requests-html.之前解析html页面用过了lxml和bs4, requests-html集成了一些 ...
- 常见Python爬虫工具总结
常见Python爬虫工具总结 前言 以前写爬虫都是用requests包,虽然很好用,不过还是要封装一些header啊什么的,也没有用过无头浏览器,今天偶然接触了一下. 原因是在处理一个错误的时候,用到 ...
- Python缓存技术,装x新高度。
一段非常简单代码 普通调用方式 def console1(a, b): print("进入函数") return (a, b) print(console1(3, 'a')) pr ...
- python魔法函数__dict__和__getattr__的妙用
python魔法函数__dict__和__getattr__的妙用 __dict__ __dict__是用来存储对象属性的一个字典,其键为属性名,值为属性的值. 既然__dict__是个字典那么我们就 ...
- python并发模块之concurrent.futures(二)
python并发模块之concurrent.futures(二) 上次我们简单的了解下,模块的一些基本方法和用法,这里我们进一步对concurrent.futures做一个了解和拓展.上次的内容点这. ...
- Python 爬虫实战(二):使用 requests-html
Python 爬虫实战(一):使用 requests 和 BeautifulSoup,我们使用了 requests 做网络请求,拿到网页数据再用 BeautifulSoup 解析,就在前不久,requ ...
- 路飞学城Python爬虫课第一章笔记
前言 原创文章,转载引用务必注明链接.水平有限,如有疏漏,欢迎指正. 之前看阮一峰的博客文章,介绍到路飞学城爬虫课程限免,看了眼内容还不错,就兴冲冲报了名,99块钱满足以下条件会返还并送书送视频. 缴 ...
- 《实战Python网络爬虫》- 感想
端午节假期过了,之前一直在做出行准备,后面旅游完又休息了一下,最近才恢复状态. 端午假期最后一天收到一个快递,回去打开,发现是微信抽奖中的一本书,黄永祥的<实战Python网络爬虫>. 去 ...
随机推荐
- 相关系数之杰卡德相似系数(Jaccardsimilarity coefficient)
杰卡德相似系数(Jaccardsimilarity coefficient) (1)杰卡德相似系数 两个集合A和B交集元素的个数在A.B并集中所占的比例,称为这两个集合的杰卡德系数,用符号 J(A,B ...
- MySQL统计数据库表大小
use information_schema; SELECT TABLE_NAME, (DATA_LENGTH/1024/1024) as DataM , (INDEX_LENGTH/1024/102 ...
- 并查集——poj1308(并查集延伸)
题目链接:Is It A Tree? 题意:给你一系列形如u v的点对(u v代表一条由u指向v的有向边),请问由给你的点构成的图是不是一棵树? 树的特征:①每个节点(除了根结点)只有一个入度:②只有 ...
- C#程序中SQL语句作为函数参数形式问题
今天遇到一个神奇现象,目前正在写一个Demo,人事管理系统,首先肯定是初始化主页面,在初始化时,需要声明一个登陆窗体,但是当我在登陆窗体中填入登入名称和密码时直接就登陆成功了,但是发现我的status ...
- 牛客网(string::find()函数回忆一下)
链接:https://www.nowcoder.com/acm/contest/109/B来源:牛客网 给出两个串s和x 定义s中的某一位i为好的位置,当且仅当存在s的子序列 满足y=x且存在j使得i ...
- vsCode怎么为一个前端项目配置ts的运行环境
vsCode为一个前端项目配置ts的运行环境,ts文件保存的时候自动编译成js文件: 假设此前端项目名称为Web:文件结构如图 1. 在根目录中新建一个“.vscode”文件夹,里面建一个“tasks ...
- 配置Mac自带的Apache http服务器
Mac系统是自带Apache,所以很方便我们做一些http测试. 我可以先启动默认的服务器 $ sudo apachectl start 在浏览器打开:http://localhost 将会看到下面信 ...
- 判断腾讯QQ是否在线
http://webpresence.qq.com/getonline?Type=1&1617052138: 判断腾讯QQ是否在线接口. 下面是个简单的例子: <!doctype htm ...
- Codeforces Round #519 by Botan Investments翻车记
A:枚举答案即可.注意答案最大可达201,因为这个wa了一发瞬间爆炸. #include<iostream> #include<cstdio> #include<cmat ...
- 02.Java面向对象问题
目录介绍 2.0.0.1 重载和重写的区别?重载和重写绑定机制有何区别?父类的静态方法能否被子类重写? 2.0.0.2 封装.继承.多态分别是什么? 2.0.0.3 接口和抽象类的区别是什么?接口的意 ...