Python爬虫中文小说网点查找小说并且保存到txt(含中文乱码处理方法)
从某些网站看小说的时候经常出现垃圾广告,一气之下写个爬虫,把小说链接抓取下来保存到txt,用requests_html全部搞定,代码简单,容易上手.
中间遇到最大的问题就是编码问题,第一抓取下来的小说内容保持到txt时出现乱码,第二url编码问题,第三UnicodeEncodeError
先贴源代码,后边再把思路还有遇到的问题详细说明。
from requests_html import HTMLSession as hs def get_story(url):
global f
session=hs()
r=session.get(url,headers=headers)
r.html.encoding='GBK'
title=list(r.html.find('title'))[0].text#获取小说标题
nr=list(r.html.find('.nr_nr'))[0].text#获取小说内容
nextpage=list(r.html.find('#pb_next'))[0].absolute_links#获取下一章节绝对链接
nextpage=list(nextpage)[0]
if(nr[0:10]=="_Middle();"):
nr=nr[11:]
if(nr[-14:]=='本章未完,点击下一页继续阅读'):
nr=nr[:-15]
print(title,r.url)
f.write(title)
f.write('\n\n')
f.write(nr)
f.write('\n\n')
return nextpage def search_story():
global BOOKURL
global BOOKNAME
haveno=[]
booklist=[]
bookname=input("请输入要查找的小说名:\n")
session=hs()
payload={'searchtype':'articlename','searchkey':bookname.encode('GBK'),'t_btnsearch':''}
r=session.get(url,headers=headers,params=payload)
haveno=list(r.html.find('.havno'))#haveno有值,则查找结果如果为空
booklist=list(r.html.find('.list-item'))#booklist有值,则有多本查找结果
while(True):
if(haveno!=[] and booklist==[]):
print('Sorry~!暂时没有搜索到您需要的内容!请重新输入')
search_story()
break
elif(haveno==[] and booklist!=[]):
print("查找到{}本小说".format(len(booklist)))
for book in booklist:
print(book.text,book.absolute_links)
search_story()
break
else:
print("查找到结果,小说链接:",r.url)
BOOKURL=r.url
BOOKNAME=bookname
break global BOOKURL
global BOOKNAME
url='http://m.50zw.net/modules/article/waps.php'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36 OPR/53.0.2907.99'
} search_story()
chapterurl=BOOKURL.replace("book","chapters")
session=hs()
r=session.get(chapterurl,headers=headers)
ch1url=list(r.html.find('.even'))[0].absolute_links#获取第一章节绝对链接
ch1url=list(ch1url)[0]
global f
f=open(BOOKNAME+'.txt', 'a',encoding='gb18030',errors='ignore')
print("开始下载,每一章节都需要爬到,速度快不了,请等候。。。。\n")
nextpage=get_story(ch1url)
while(nextpage!=BOOKURL):
nextpage=get_story(nextpage)
f.close
爬虫思路及遇到的问题分析如下:
先查找小说,并且把小说链接抓取下来,以网站http://m.50zw.net/modules/article/waps.php为例,首先在浏览器中打开链接并且右键点检查,选择Network标签,我用的是chrome浏览器,按F1设置把Network底下的Preserve log勾选上,方便接下来查找log,以搜索‘帝后世无双’为例,搜索到结果后直接跳到了此本小说的url:http://m.50zw.net/book_86004/
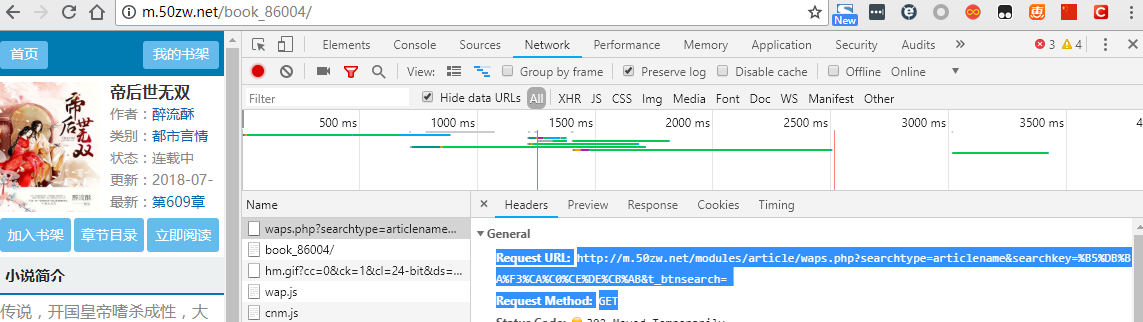
查看到请求方式是GET,Request URL是 http://m.50zw.net/modules/article/waps.php?searchtype=articlename&searchkey=%B5%DB%BA%F3%CA%C0%CE%DE%CB%AB&t_btnsearch=
然后分析出请求参数有三个,searchtype先固定用图书名来查找,而searchkey我们输入的是”敌后世无双“,url encoding成了%B5%DB%BA%F3%CA%C0%CE%DE%CB%AB,我们在python ide里边分别输入:
"敌后世无双".encode('GBK'):b'\xb5\xd0\xba\xf3\xca\xc0\xce\xde\xcb\xab'
"敌后世无双".encode('utf-8'):b'\xe6\x95\x8c\xe5\x90\x8e\xe4\xb8\x96\xe6\x97\xa0\xe5\x8f\x8c'
对照输出结果我们知道这里url编码采用的是GBK
接下来我们用代码来验证我们分析的结果
from requests_html import HTMLSession as hs
url='http://m.50zw.net/modules/article/waps.php'
payload={'searchtype':'articlename','searchkey':'帝后世无双','t_btnsearch':''}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36 OPR/53.0.2907.99'
}
session=hs()
r=session.get(url,headers=headers,params=payload)
print(r.url)
运行结果:
http://m.50zw.net/modules/article/waps.php?searchtype=articlename&searchkey=%E5%B8%9D%E5%90%8E%E4%B8%96%E6%97%A0%E5%8F%8C&t_btnsearch=
比较得到的url跟我们刚才手动输入后得到的url有出入,代码里边如果没有指定编码格式的话了这里url编码默认是urf-8,因为编码问题我们没有得到我们想要的结果,那接下来我们修改代码指定编码试试
payload={'searchtype':'articlename','searchkey':'帝后世无双'.encode('GBK'),'t_btnsearch':''}
这回运行结果得到我们想要的url:
http://m.50zw.net/book_86004/
好,成功了!!!
那接下来我们要获取第一章节的链接,中间用到了requests_html来抓取绝对链接
bookurl='http://m.50zw.net/book_86004/'
chapterurl=bookurl.replace("book","chapters")
session=hs()
r=session.get(chapterurl,headers=headers)
ch1url=list(r.html.find('.even'))[0].absolute_links
ch1url=list(ch1url)[0]
print(ch1url)
运行结果:
http://m.50zw.net/book_86004/26127777.html
成功取得第一章节链接
接下来我们开始获取小说内容并且获取下一章链接直到把整本小说下载下来为止,
在这个部分遇到UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 46:illegal multibyte sequence,这个问题最终在用open函数打开txt时加两个参数解决encoding='gb18030',errors='ignore'.
在之前也用过另外一种方案,就是把u'\xa0'替换成跟它等效的u' ',虽然解决了'\xa0'的error,可是后来又出现了’\xb0'的error,总不能出现一个类似的rror就修改代码替换一次,所以这个方案被放弃掉.
session=hs()
r=session.get(ch1url,headers=headers)
title=list(r.html.find('title'))[0].text
nr=list(r.html.find('.nr_nr'))[0].text
##nr=nr.replace(u'\xa0',u' ')
nextpage=list(r.html.find('#pb_next'))[0].absolute_links
nextpage=list(nextpage)[0]
if(nr[0:10]=="_Middle();"):
nr=nr[11:]
if(nr[-14:]=='本章未完,点击下一页继续阅读'):
nr=nr[:-15]
print(title,r.url)
print(nextpage)
f=open('帝后世无双.txt', 'a',encoding='gb18030',errors='ignore')
f.write(title)
f.write('\n\n')
f.write(nr)
f.write('\n\n')
Python爬虫中文小说网点查找小说并且保存到txt(含中文乱码处理方法)的更多相关文章
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- 关于爬取数据保存到json文件,中文是unicode解决方式
流程: 爬取的数据处理为列表,包含字典.里面包含中文, 经过json.dumps,保存到json文件中, 发现里面的中文显示未\ue768这样子 查阅资料发现,json.dumps 有一个参数.ens ...
- 「拉勾网」薪资调查的小爬虫,并将抓取结果保存到excel中
学习Python也有一段时间了,各种理论知识大体上也算略知一二了,今天就进入实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫. 第一步:分析网站的请求过程 我们在查看拉勾网上的招聘信息的时候 ...
- python爬虫下载小视频和小说(基础)
下载视频: 1 from bs4 import BeautifulSoup 2 import requests 3 import re 4 import urllib 5 6 7 def callba ...
- 一个简易的Python爬虫,将爬取到的数据写入txt文档中
代码如下: import requests import re import os #url url = "http://wiki.akbfun48.com/index.php?title= ...
- python 读取一个文件夹下的所jpg文件保存到txt中
最近需要使用统计一个目录下的所有文件,使用python比较方便,就整理了一下代码. import os def gci(filepath): files = os.listdir(filepath) ...
- java 保存到mysql数据库中文乱码
<property name="jdbcUrl">jdbc:mysql://localhost:3306/company?useUnicode=true&cha ...
- 第二个爬虫之爬取知乎用户回答和文章并将所有内容保存到txt文件中
自从这两天开始学爬虫,就一直想做个爬虫爬知乎.于是就开始动手了. 知乎用户动态采取的是动态加载的方式,也就是先加载一部分的动态,要一直滑道底才会加载另一部分的动态.要爬取全部的动态,就得先获取全部的u ...
- 用python+selenium抓取微博24小时热门话题的前15个并保存到txt中
抓取微博24小时热门话题的前15个,抓取的内容请保存至txt文件中,需要抓取排行.话题和阅读数 #coding=utf-8 from selenium import webdriver import ...
随机推荐
- linux下GCC编译文件
Linux终端使用技巧: Ctrl+Alt+T打开终端 Ctrl+c死循环退出程序 Shift+Ctrl+T:新建标签页 Shift+Ctrl+N:新建窗口 Shift+Ctrl+Q:关闭终端 终端中 ...
- OpenCV实现彩色图像轮廓 换背景颜色
转摘请注明:https://i.cnblogs.com/EditPosts.aspx?opt=1 有时候我们需要不一样颜色的证件照,下面就用OpenCV来实现证件照的蓝底.红底等换颜色: 代码如下: ...
- es6学习日记3
函数的扩展 ES6 之前,不能直接为函数的参数指定默认值,只能采用变通的方法. function log(x, y) { y = y || 'World'; console.log(x, y); } ...
- String类常用方法练习
String 类代表字符串.Java 程序中的所有字符串字面值(如 "abc" )都作为此类的实例实现. 字符串是常量:它们的值在创建之后不能更改.字符串缓冲区支持可变的字符串. ...
- day05 集合
今日进度(数据类型) 集合 内存相关 深浅拷贝 1.集合表示 1.无序 2.不重复 3.hash查找 #问题:v={}表示? set: v1=set()#空集合 v1={1,2,3,4,5} dict ...
- for break
public static void main(String[] args) { aaa: for (int j = 0; j < 2; j++) { System.out.println(&q ...
- cordova文件传输系统插件使用:cordova-plugin-file-transfer
1. 添加插件:cordova plugin add cordova-plugin-file-transfer 2. 调用方法: var fileTransfer = new FileTransfer ...
- 嵌入式Linux内核tasklet机制(附实测代码)
Linux 中断编程分为中断顶半部,中断底半部 中断顶半部: 做紧急,耗时短的事情,同时还启动中断底半部. 中断底半部: 做耗时的事件,这个事件在执行过程可以被中断. 中断底半部实现方法: taskl ...
- Announcing the Operate Preview Release: Monitoring and Managing Cross-Microservice Workflows
转自:https://zeebe.io/blog/2019/04/announcing-operate-visibility-and-problem-solving/ Written by Mik ...
- oracle-data-mining
create user datamine identified by 123456 QUOTA UNLIMITED ON users; 然后在sqldeveloper工具界面-data miner中, ...